月见八千代AStrBot Agent的持续更新迭代中。我开始思考想让她更有一点人味儿,打算利用GPT-SoVITS训练一版她的声音。作为TTS加进AStrBot里面。
这个工具我是从来没有做过的,做完一套之后,随记录:
先说结论
macOS能跑,但是确实不适合作为主要的训练平台。
- 环境兼容问题比较多
- 下载依赖也容易出问题
- WEBUI在mac上会遇到Gradio starlette localhost 这些代理问题
- CPU训练也很慢
上述参考官方文档的运行过程中的问题基本都可以交给AI做处理,最后的结果就是能运行成功(
本文主要做的事情是 讲解界面是干嘛的
主力方案:Windows + NVIDIA显卡
下载官方的一键包之后,我们看到是这个画面:
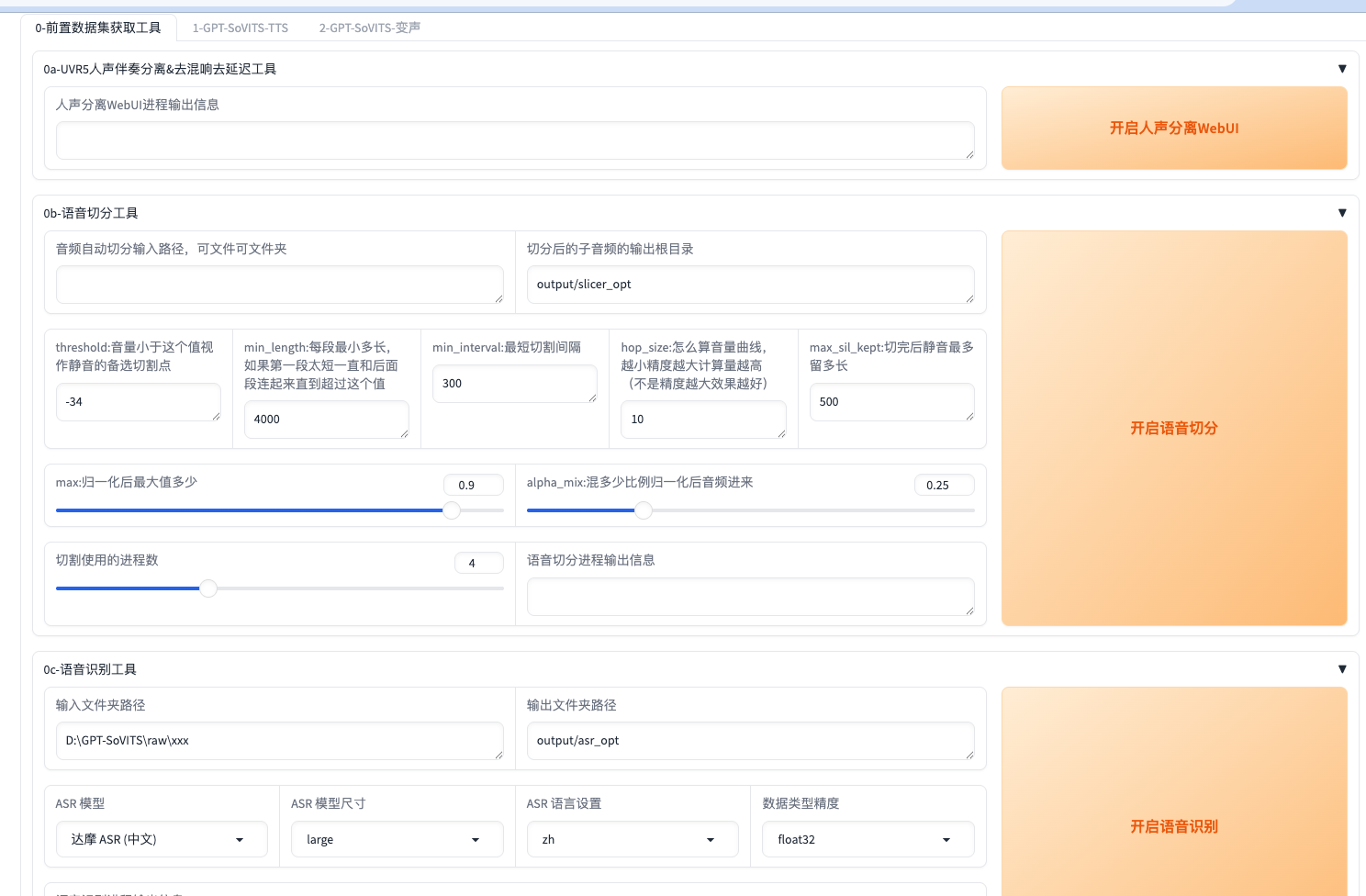
0-前置数据集获取工具
Step1:0a-UVR5人声伴奏分离&去混响去延迟工具
这是一个用于处理音频的工具,如果你的音源已经相当干净了,可以直接跳过这一步:
让我们看看进来长啥样:
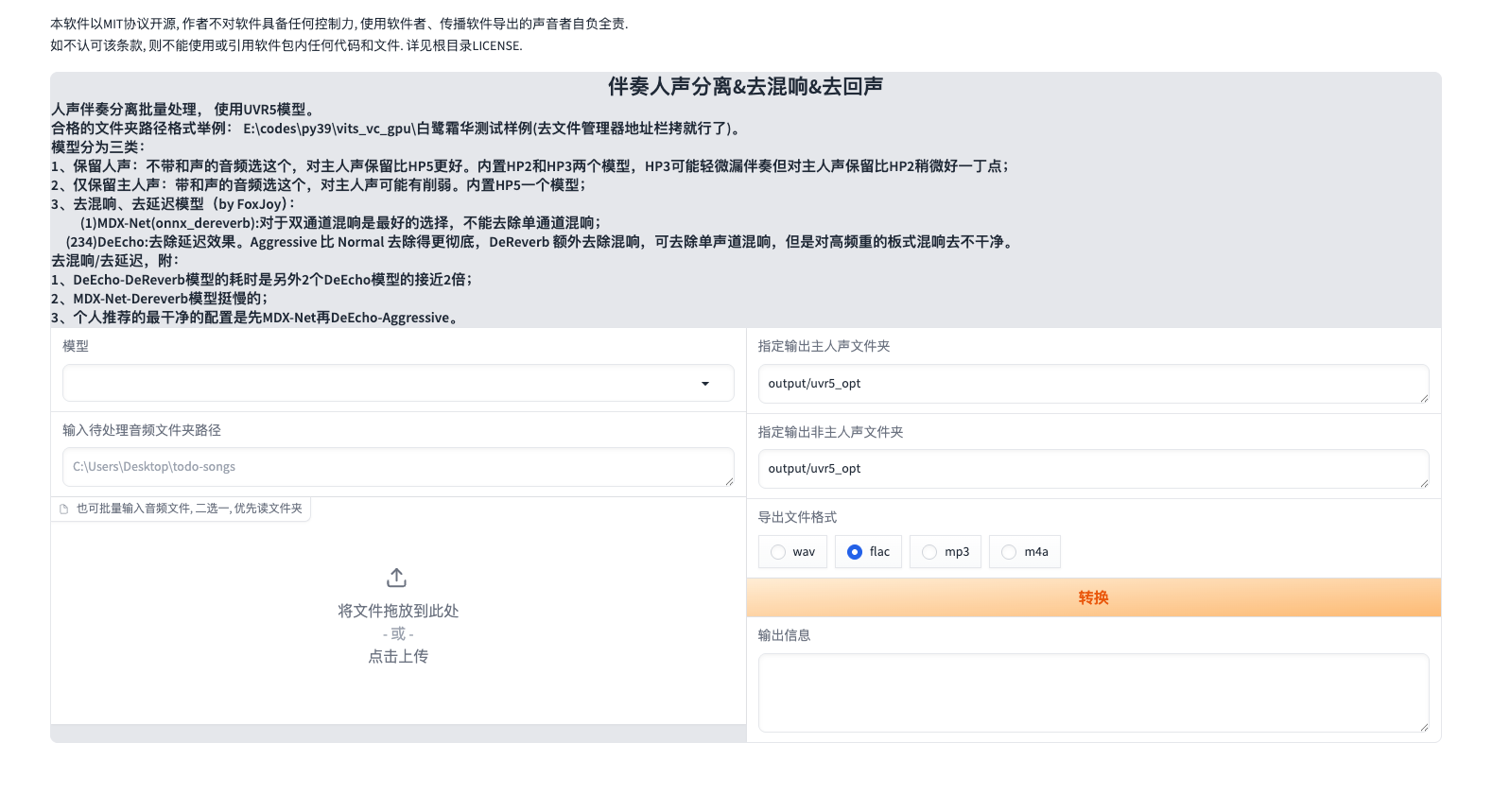
模型基本都是一键包里面自带的,都是Huggingface上面的有意思的模型。
你可以把你待处理的音频拖上去,然后生成出来的音频会在output文件夹下面:

vocal前缀就是主人声的音频文件,他就可以作为训练用的内容了。
Step2:0b-语音切分工具
把Step1拿到的vocal文件,放在输入路径里,没有特别的要求的话,直接开启语音切分就可以了,你可以在output文件夹下面看到slicer_opt:
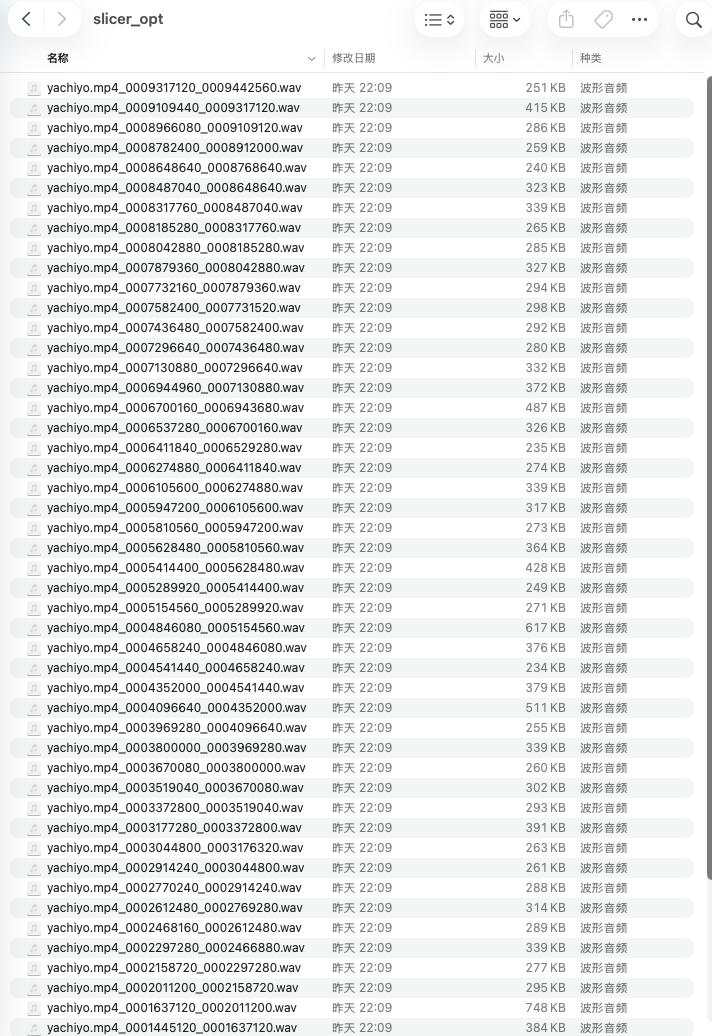
这里会被切分成数十个几秒钟的音频,用于后面做参考音频用的(划重点)
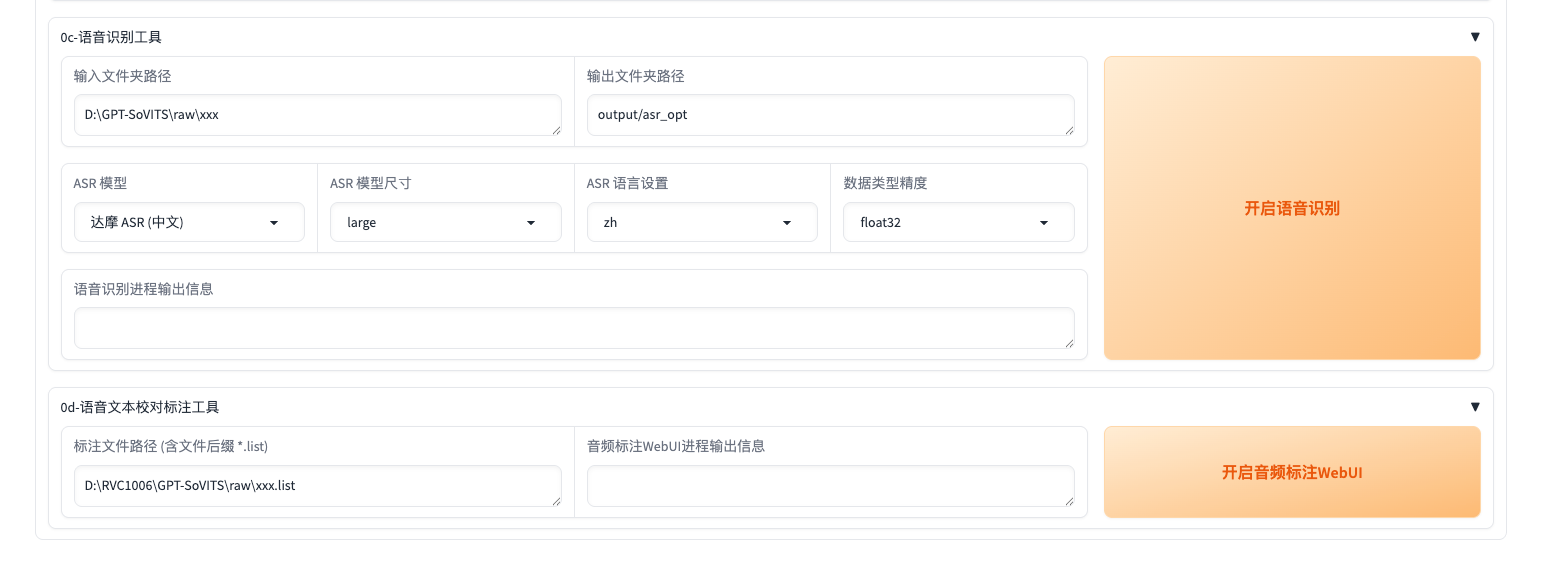
Step3:0c-语音识别工具
这里则是通过语音识别工具拿到识别的文本
输入文件夹路径就是Step2里面拿到的slicer的文件夹,理论上,第二步跑完了之后,这里会自动填入。如果你的音频不是中文,是日文或者英文或者其他语种,ASR模型要选择如图这种:
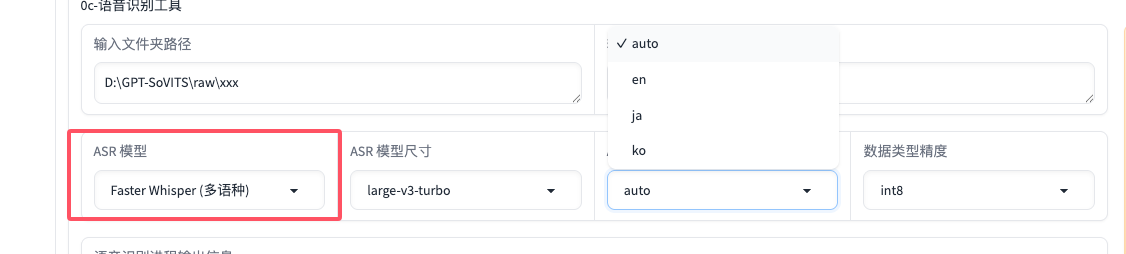
做完了之后,在output里面也能看到一个.list后缀的文件:

我们用VScode打开: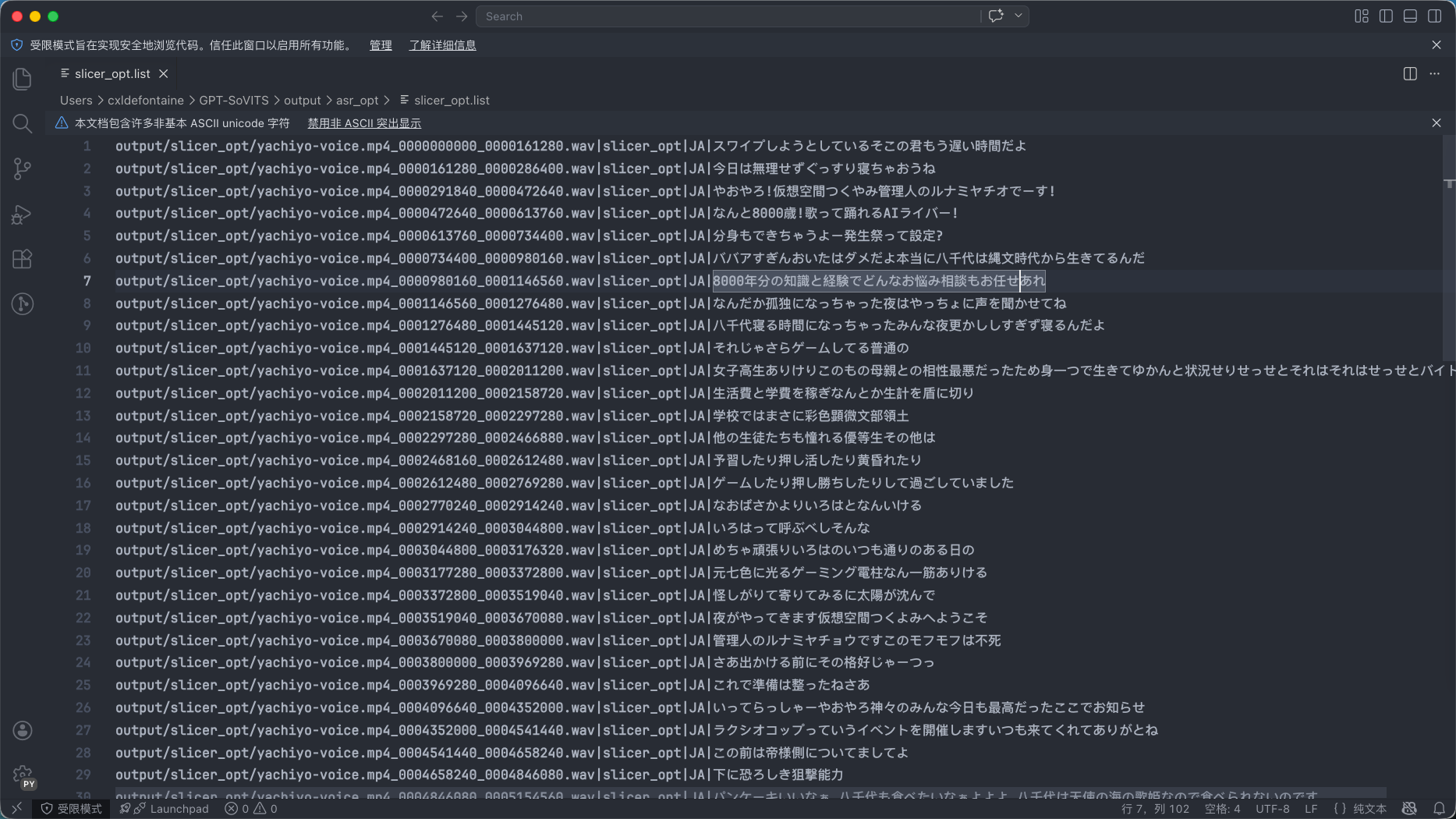
就能看到每一段被切分的音频对应的识别字幕。敲重点:这些字幕也是后续生成的时候要用到的参考数据。
Step4:0d-语音文本校对标注工具
这个会打开一个新的WebUI界面,作用是人工核对精准性: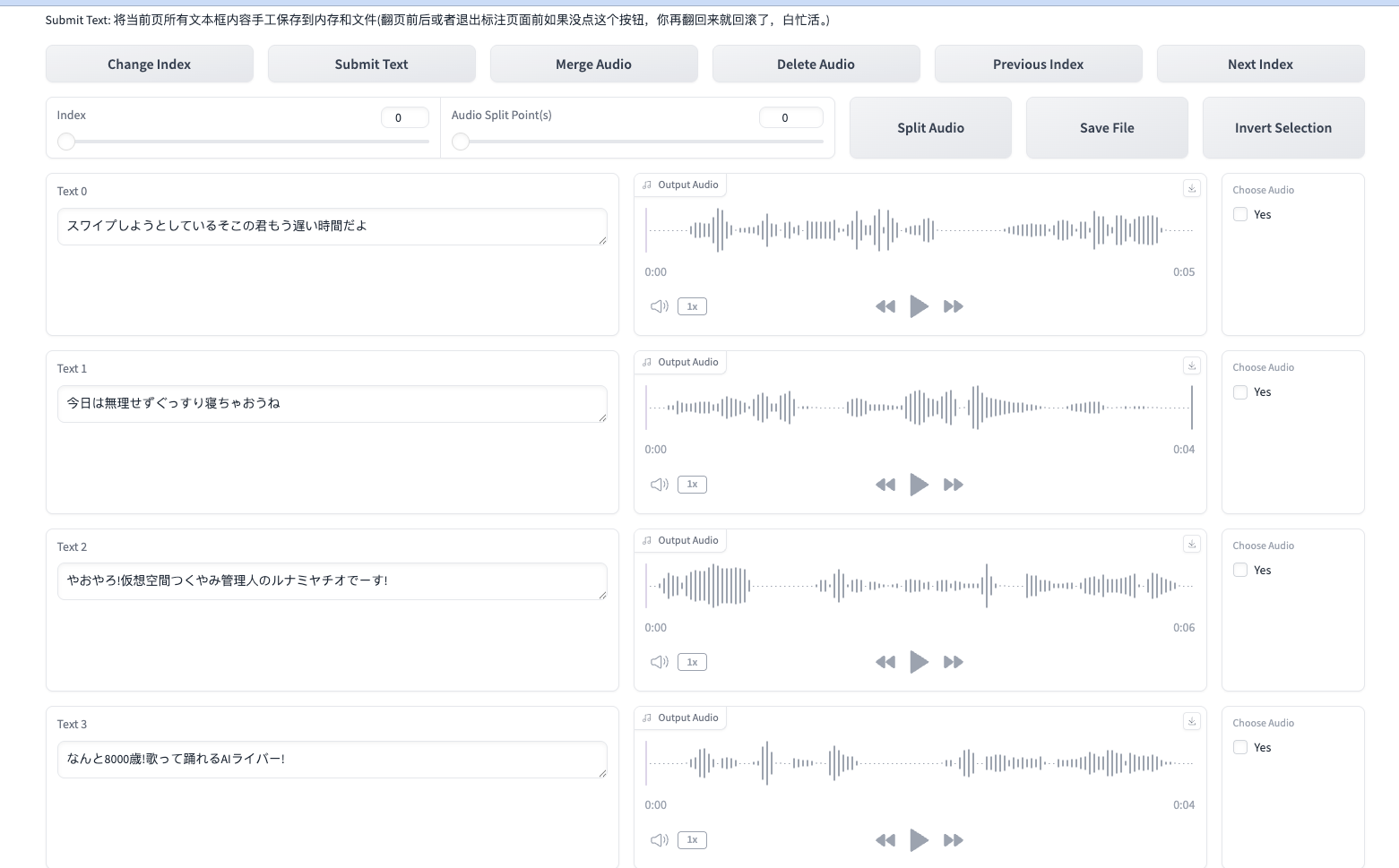
简单来说就是让你一边听一边看文本做一下对比,有问题的话就手动修改一下,然后submit就可以修改内容了。如果没有问题可以直接关闭。
1-GPT-SOVITS-TTS
页面总体介绍
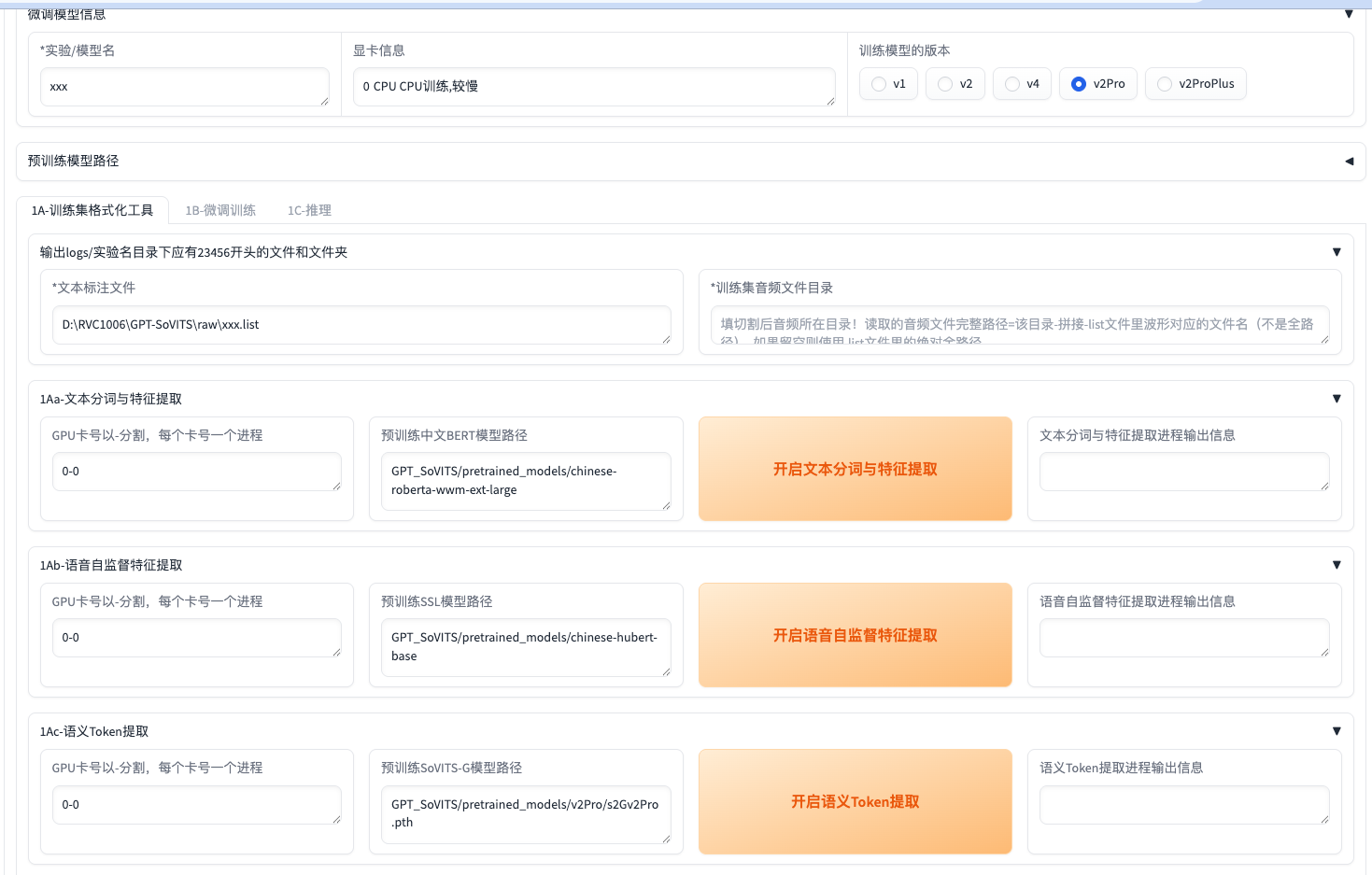
实验/模型名:你这次训练出来的GPT-SoVITS模型的名字
显卡信息:我截图的环境是macOS,正常来说,如果是Windows+N卡,这里会显示N卡的信息。
训练版本重点讲一下,(V2和V4)的区别:
- V2系列:适合普通的二创素材、质量不算完美的、想要效果稳定一点。
- V4: 适合干净统一的数据、更想要贴进参考音频的、想要更强的参考驱动感
然后页面分为1A 1B 1C三个子tab,分别对应了三个训练步骤。
预训练模型路径非必要不要进行修改。完整包是自带的有。
文本标注文件和训练集音频文件目录都上上个大步骤做的,直接搬过来就行。
Step1: 1A-训练集格式化工具
这一步没有什么需要特别注意的:
如果一键三连能跑通,就直接一键三连。
Step2:1B-微调训练
这个是最关键的一步,从这里产生的GPT和So-VITS模型。这些模型训练好了是可以直接迁移到其他设备上马上用的。
如果你走的是V4(训练用音频足够干净),可以直接参考我的图示参数:
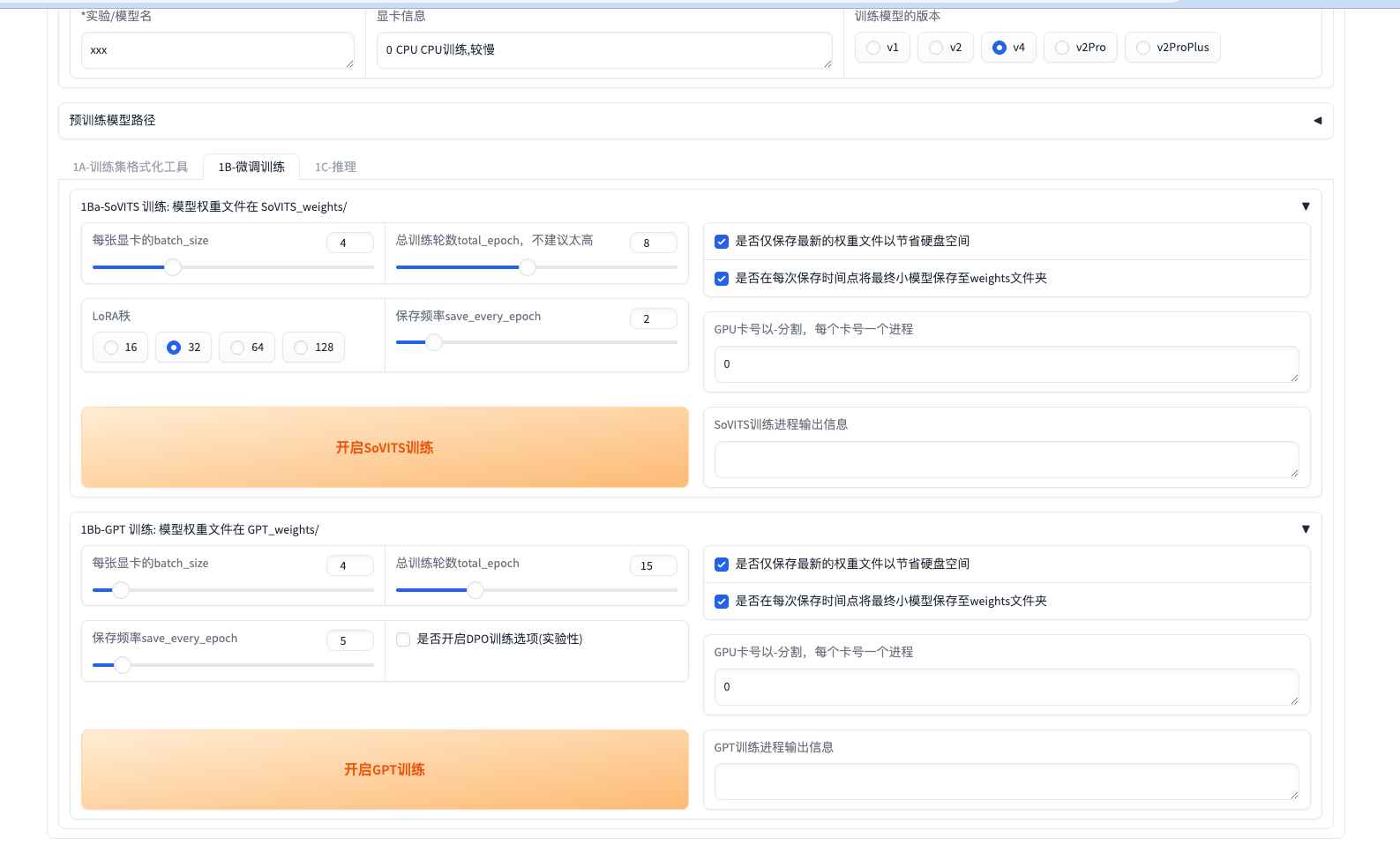
SoVITS
- batch_size = 4
- total_epoch = 8
- LoRA秩 = 32
- save_every_epoch = 2
- GPU卡号 = 0
GPT
- batch_size = 4
- total_epoch = 15
- save_every_epoch = 5
- GPU卡号 = 0
- DPO 不勾
一个个点,先点开启SoVITS训练,再点开启GPT训练。
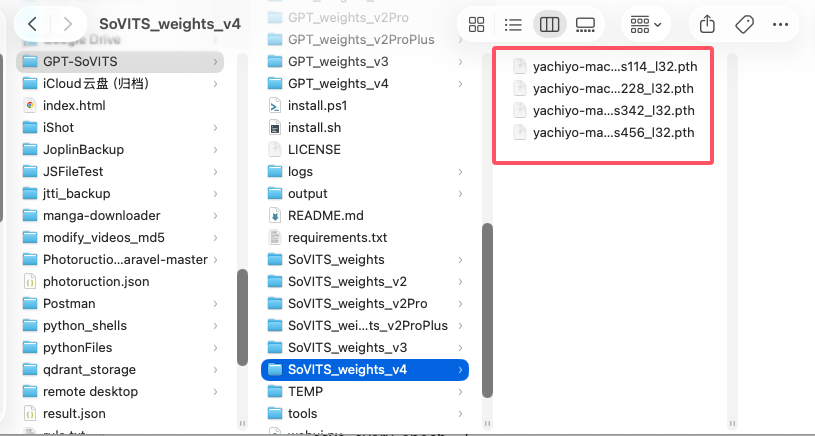
等两个都完成之后,我们会在对应的目录找到他们的训练成果:
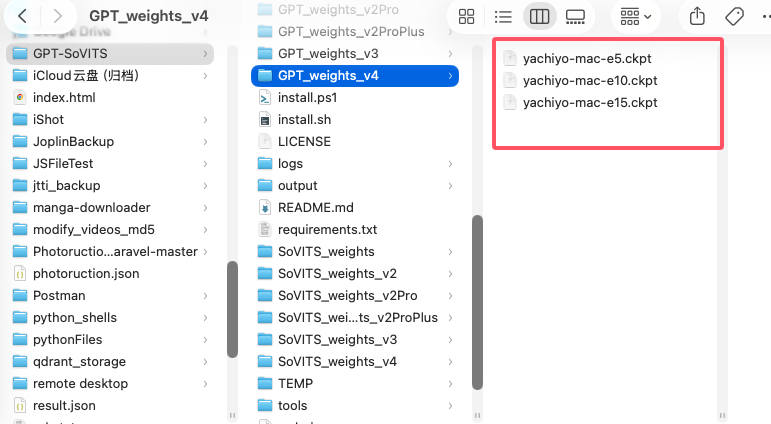
- .ckpt 或 GPT 相关的是 GPT
- .pth 的是 SoVITS
这里科普一点小知识,你看这些训练出来的模型的名字都很复杂对吧,实际上都有意义的:
GPT 模型里的 e15,就是 第 15 个 epoch 保存出来的权重。官方 s1_train.py 在保存 GPT 权重时,文件名就是按 exp_name-e{epoch}.ckpt 来命名,同时还会把说明写成 GPT-e{epoch}。所以像 xxx-e15.ckpt,直接读作“GPT 训练到第 15 轮时保存的权重”。
SoVITS 模型里的 e8,同样是 第 8 个 epoch。官方 s2_train.py 保存导出权重时,名字会拼成 exp_name_e{epoch}_s{global_step};如果是 v3/v4 这条 LoRA 训练分支,则会拼成 exp_name_e{epoch}_s{global_step}_l{lora_rank}。所以你看到的 e8,就是第 8 轮。
s456 里的 s,指的是 steps / global_step,也就是训练进行了多少个全局步数。官方保存函数 savee() 里也把 info 写成了 "{epoch}epoch_{steps}iteration",这和文件名里的 s{global_step} 是对应的。也就是说,s456 就是“保存这份权重时,训练总步数走到了 456 步”。
l32 里的 l,指的是 LoRA rank。在 v3/v4 的 SoVITS LoRA 训练脚本里,lora_rank 会从配置读入,保存目录里也会带上 rank,导出权重文件名会明确写成 _l{lora_rank};同时 savee() 还会把 lora_rank 写进权重元信息里。于是 l32 就是“这份权重是用 LoRA rank = 32 训练出来的”。
所以你可以直接这样读:
- GPT: yachiyo-e15.ckpt = GPT 第 15 轮
- SoVITS: yachiyo_e8_s456.pth = SoVITS 第 8 轮,第 456 步
- SoVITS: yachiyo_e8_s456_l32.pth = SoVITS 第 8 轮,第 456 步,LoRA rank 32
补一个实用判断:
- 看 e:主要看训练轮次,方便你比较早期和后期权重
- 看 s:更细地看保存时机,尤其数据量不同时很有用
- 看 l:只在 LoRA 路线里重要,表示这份权重属于哪种 LoRA 配置
在实际挑权重试听时,优先按这个思路:
先选 epoch 最大的那份,再和前一个保存点对比听。例如先听 e8,再听 e6,看后面是不是变得更像,还是开始发闷、发飘。
Step3:1C-推理
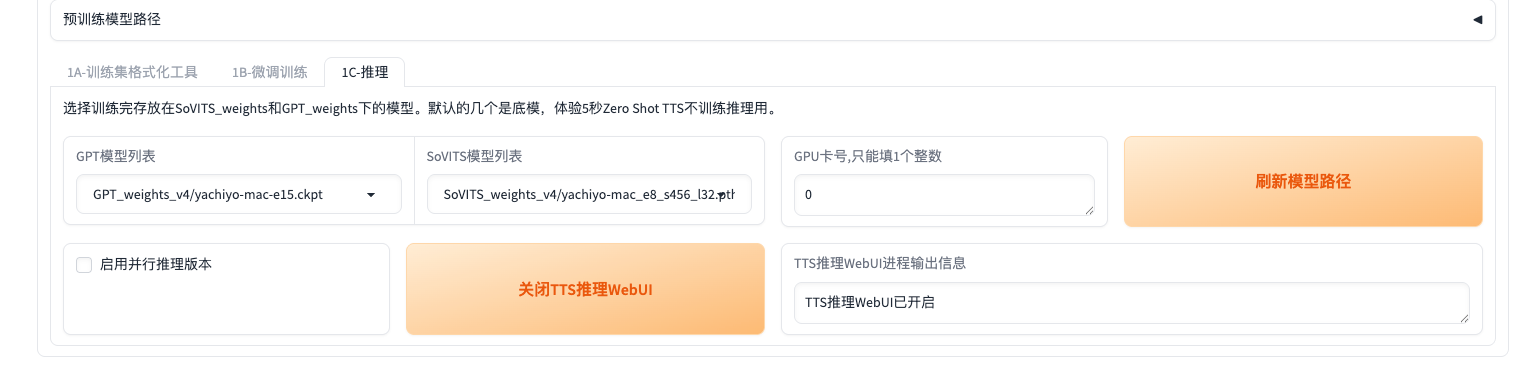
在这里把你刚刚训练出来的模型选上,然后我们打开TTS推理WebUI:(注意不要打开并行推理,电音有点严重)
然后我们回到第一个大步骤里面拿到的切片音频和对应的文本做参照:
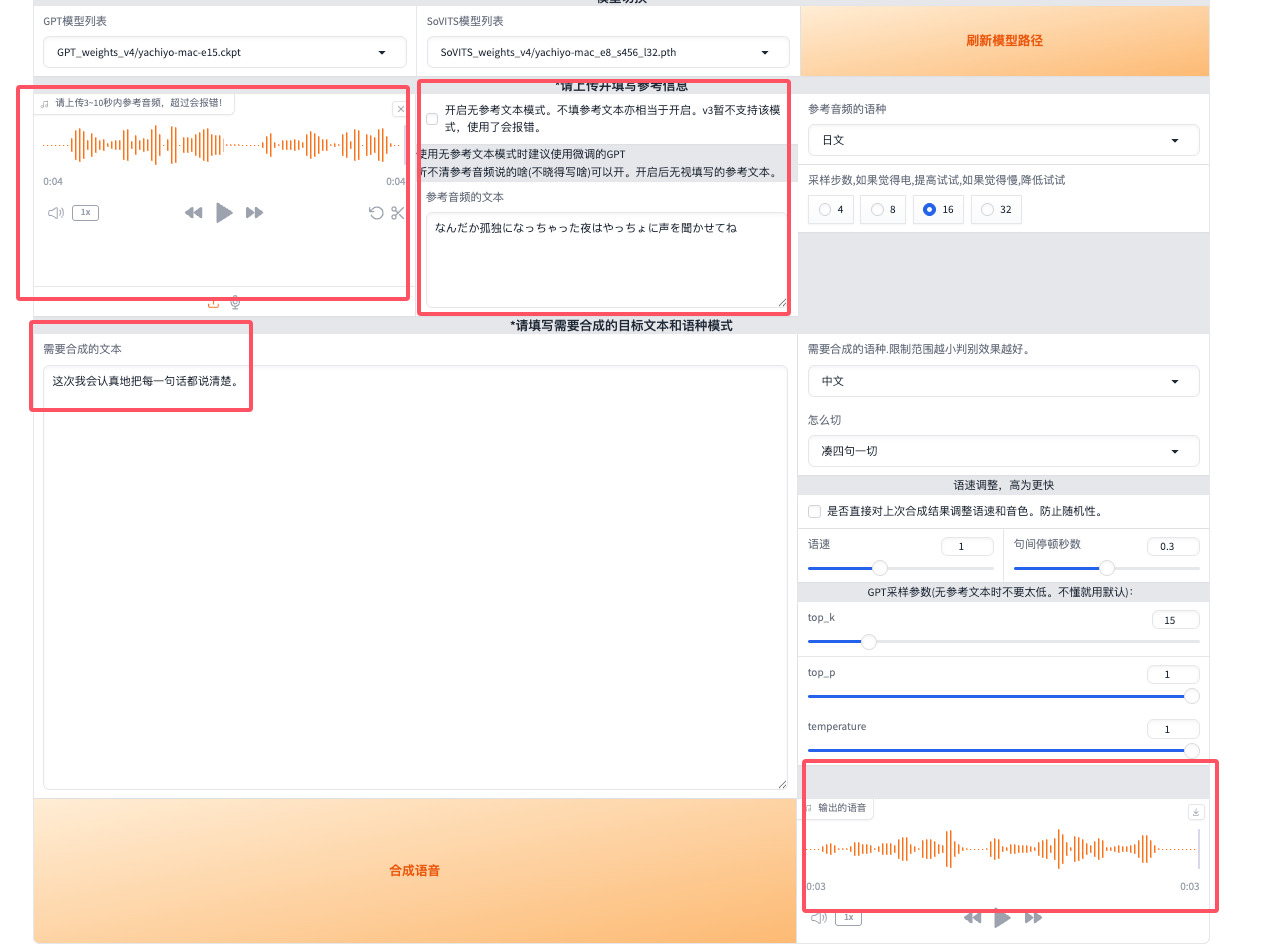
这个调试窗口会有很多很多的参数,效果不佳就修改采样步数,语速,Top-K和Top-P以及温度,或者调整上面模型的训练序号之类的所有东西,直到你满意为止。
记录下参数之后,将你满意的模型和参数已经参考音频和文本都做好备份,GPT-SoVITS支持部署为本地的API,届时就可以部署到诸如AStrBot之类的服务上去了,这样,你就拥有了一个语音助手!