想象这样一个场景,在一次深夜的倾诉中,你和你的朋友讲述各种焦虑情绪和压力,对方倾听完了之后,在未来的某一天,他突然问你:”上次你说你想辞职,你后来和领导谈了这个事情吗?“
这一刻,你是不是就觉得,哇,我有被理解、关注着。
这种 持续的记忆与共鸣,正是高质量人际交流的核心。
我们把这种体验迁移到AI对话系统的时候,一个根本性的挑战就出现了:
大语言模型,天生就是健忘的
尽管LLM拥有非常强大的语言理解和生成能力,但是本质上,它是”无状态的“:这意味着每一次请求都是独立的,模型并不会记住上一轮甚至上一句说了什么。
如若我们不主动去管理上下文,AI就像一个刚刚见面就会忘记前一秒对话的人(鱼的记忆?),不断重复提问,忽略情感的变化,丢失关键的信息。
这样的”健忘“,就会让用户迅速对其失去信任,情感连接这种事情也就无从谈起了。
这就是我们这次要处理的核心问题:
我该怎么让AI记住用户、理解对话脉络,并且在此基础之上,构建连贯、自然且有温度的长期互动体验?
这就是 上下文管理
1. 上下文的本质:从单轮对话到多轮交互
在大语言模型应用从业者看来,“上下文工程”并不是崭新的范式,早就在GPT-3.5的时代,这群开发者就已经在努力解决一样的问题:
该怎么样在模型可以理解的范围内,获取更加完整的上下文,并将其有效拼接到提示词里?
大语言模型在拥有充足且结构清晰的上下文的时候,表现远远优于依赖“精心设计但是信息匮乏”的提示词。
1.1 什么是上下文?
归根到底,驱动“上下文工程”概念兴起的根本原因,就是LLM的上下文窗口限制。如果窗口是无限的,那么一切工程皆可免除:我们直接尽数灌入就行了。
但是,正因为有限的视野,我们不得不思考:
在有限的tokens内,怎么去筛选、组织、压缩、动态填充最相关、最完整、最有序的信息?这就包含了:
- 信息优先级判断:什么才是当前任务的关键?
- 信息完整性维护:怎么在分块/压缩中保留最大的语义? (摘要,结构保留)
- 信息动态组合:如何实时整合外部数据源(API/RAG)和内部记忆(历史/记忆)
- 信息交互:洞悉大语言模型和人脑对信息处理的微妙差异。
在大语言模型application里,上下文 指的就是模型在生成回复的时候所依赖的所有历史信息,包括但不限于:
- 用户和AI中间的完整对话历史(messages)
- 用户的个人偏好、性格特征、情感状态
- 之前的决策、承诺或者未完成的任务
- 外语知识或者记忆片段(过往聊天记录的摘要等等)
这些信息共同构成了AI理解当前对话的“背景”,决定了它是否能够做出 连贯、合理、个性化的回应。
上下文工程的核心追求,就是在LLM有限的上下文窗口之内,精准投入使其高效工作必须的完整信息
1.2 为什么上下文对于聊天应用而言如此至关重要?
因为我们要做的情感交流机器人,不同于任务型的对话(订机票,查天气),它的价值不在于”完成特定的事情“,而是在于”建立关系“。关系的建立,依赖于一致性、连续性以及共情性这三个关键要素
| 要素 | 依赖的上下文能力 |
|---|---|
| 一致性 | AI需要保持角色、语气、价值观稳定,避免前后矛盾 |
| 连续性 | AI需要记住用户之前的情绪、事件、承诺,形成叙事线索 |
| 共情性 | AI需要感知情绪变化的趋势,实时回应,体现”陪伴感“ |
比方说你前几天才给AI吐槽过工作强度大,老是加班,三天之后,你给AI发了一句:”芜湖!我昨天睡了个好觉,加班到头啦!“ AI:”太好啦!是不是最近调整了作息?老板不催你加班了吗?“
喏,虽然AI没有明说它记得你睡不好,一直加班,但是他回应的内容就隐含了对于过去的记忆,形成了情感上的延续。这就是上下文管理的意义。
我们该怎么样才可以动态地、智能地构建和维护整个上下文窗口呢?(Context Window)? LLM的输入长度是有限的,如何利用这个有限的空间至关重要。
方法有三:
- 上下文压缩(Context Compression):保持关键信息的同时,删减不重要的或者冗余的内容,节省空间
- 对话历史管理:多轮对话里,有效地总结和管理之前的对话历史,确保对话的连贯性,避免上下文窗口被陈旧信息给填满。
- 动态上下文注入:根据对话的进展或者用户的行为,实时地从外部源(用户画像数据库、实时传感器数据)拉取信息,注入到上下文里。
2. 上下文管理的技术实现路径
2.1 最基础的方式:对话历史拼接(Naive Context Window)
最直接的方法就是把所有的历史对话信息(包括用户输入的和AI回复的) 按照时间顺序拼接,作为prompt的一部分传递给模型。
这种做法有优势也优劣势:
优点:简单直观,不需要额外的系统,适合短对话的MVP验证(最小可行性验证)
缺点:受限于模型上下文窗口,无法支持长期记忆 随着对话的增长,成本将会急剧上升(token计费),信息冗余,关键信息也可能会被淹没在噪声之中
2.2 对话摘要(Conversation Summarization)
解决长对话问题,我们则可以引入动态摘要机制: 定期把历史对话压缩成一段简洁的摘要,作为”长期记忆“进行保留
比方说,使用一个轻量的模型对过去10轮对话的历史记录进行总结,最后得到:
用户近期因为项目压力大而焦虑,昨晚提交之后情绪明显好转,表现出了轻松感
这个摘要可以选择直接添加到后续对话的prompt里面,也可以选择存到数据库,供未来对话调用。
实现策略有三:
- 定时触发:每N轮对话之后,生成一次摘要
- 事件触发:当检测到情绪转折、任务完成等关键节点,生成一次
- 分层摘要:短期记忆保留原始对话,长期记忆使用摘要
优点:突破上下文窗口限制,降低了成本,保留了核心的信息
缺点:摘要受限于模型选择,有可能丢失细节,我们需要设计良好的提示词确保精准性
2.3 向量数据库 + 检索增强(RAG for Memory)
这就是目前最为主流的长期记忆方案了: 把用户的对话历史记录,关键事件,情感状态等信息 向量化存储,然后在需要的时候,通过语义检索,把记忆召回。
流程如下:
- 记忆编码:把每天重要的对话或事件(用户提到了”失眠“)通过嵌入模型(text-embedding-3-small)转换为向量,存入到向量数据库(Milvus,Qrdant)
- 记忆检索:用户发起新对话的时候,根据当前输入语义检索最相关的记忆片段
- 上下文注入:把检索到的记忆全部作为补充上下文插入prompt,辅助生成回复。
下面来一段伪代码你就知道了:
current_query = "昨天晚上睡得不错"
relevant_memories = vectore_db.search(query=current_query, top_k=3)
# 返回: ["用户上周抱怨了失眠", "用户曾经尝试冥想", "用户对工作压力很敏感"]
prompt = f"""
你是一个心里陪伴者,用户的记忆如下:
{relevant_memories}
当前对话:
User: {current_query}
Assistant:
"""优点:支持海量记忆存储,检索精准,避免信息过载 可结合元数据(时间、情绪标签)实现智能过滤
挑战:需要设计记忆提取策略(哪些内容记得你记忆?)检索可能会召回无关或者过时的信息,增加系统的复杂度
2.4 结构化记忆系统(Knowledge Graph / Profile Store)
更进一步,我们可以对用户的长期信息进行结构化建模,形成”用户画像“或者说是”情感知识图谱“
比如说,我们给用户建立一个JSON格式的个人档案:
{
"basic_info": {
"name": "小林",
"age": 28,
"location": "上海"
},
"emotional_profile": {
"stress_triggers": ["工作截止", "人际冲突"],
"coping_methods": ["跑步", "听音乐"],
"current_mood": "relieved"
},
"key_events": [
{
"date": "2025-10-01",
"event": "项目提交成功",
"emotion": "relieved",
"ai_response": "为你感到开心!"
}
]
}
这种结构化档案可以
- 每次对话之前加载,作为固定的上下文
- 由Ai在对话中动态更新(比如说今天对话的时候检测到用户情绪低落,我们更新一下current_mood)
- 与向量数据库结合,实现”结构化 + 非架构化“的混合记忆
优点:信息清晰,易于维护,支持逻辑推理
缺点:需要设计Schema,灵活性较低
3. 上下文管理的高级技巧与最佳实践
在有限的token预算之下,智能裁剪,动态更新,污染防控要怎么做?
3.1 上下文裁剪策略:如何在有限窗口内最大化信息价值?
当对话过于长的时候,我们必须要决定”保留什么,丢弃什么“。常见的裁剪策略如下表
| 策略 | 说明 | 适用场景 |
|---|---|---|
| 滑动窗口 | 保留最近N轮对话 | 短期任务型对话 |
| 分层保留 | 近期对话保留完整,远期的保留摘要 | 长期情感陪伴 |
| 关键事件锚定 | 保留标记为”重要“的对话轮次(情绪爆发,承诺) | 心理支持场景 |
| 基于注意力预测 | 使用模型预测那些历史消息最有可能影响当前的回复 | 高级优化 |
推荐的实践方法一般是:
结合 ”滑动窗口 + 关键事件锚定 + 定期摘要“,实现效率与记忆完整性的平衡。
3.2 记忆的唤醒与遗忘机制
记忆是AI系统的基本组成部分。
记忆分成三类:
参数化记忆、上下文结构记忆与上下文非结构记忆。其中
- 参数化记忆:模型训练后存在脑子里的知识
- 上下文结构化信息:存在数据库、表格、知识图谱里的信息
- 上下文非结构化信息:文档、图片、网页、聊天记录这类原始信息
并不是所有的记忆都应该永久保留。我们需要设计记忆生命周期管理,让AI跟人类一样:记得住重要的,淡忘琐碎的,适时”假装忘记“
3.2.1 构建分层记忆体系
想象一下,如果你记得生活中的每个细节:行人的脸,呼吸的感觉,吃的每一顿饭。这些信息会淹没掉真正重要的记忆。遗忘是一种过滤机制,帮我们保留有限的有价值的信息。
Agent也是一样,随着交互的增加,历史数据便会无限地增长。如果不加选择地保存所有内容,会面临几个问题:
- 存储成本:每个用户的历史数据都完整的保存 ,存储需求将会爆炸式地增加
- 检索效率:在海量历史记录中找到相关的信息的速度会越来越慢
- 注意力分散:太多无关信息会干扰到Agent的决策
- 隐私风险:永久保存了所有的对话会增加数据泄露的风险。
我们可以把记忆按照时间与重要性分三层:
- 短期记忆:当前对话的上下文(通常来说是5~10轮对话),会话结束之后自动清除
- 中期记忆:用户偏好、近期事件(比如”上周失眠“ ”刚提交项目“),保留数天或者数周;
- 长期记忆:重大人生节点、核心人格特征(害怕公开演讲、喜欢冥想),可以长期存储甚至于说是永久保留。
关键问题在于:远期记忆该如何自然而然的”淡化“,而不是粗暴的删除?
诶!DeepSeek 在OCR论文里有提到过光学压缩式遗忘机制:
他们观察到,人类记忆具有”距离越远,细节就越模糊“的特征,于是,历史对话把它们渲染成图像并且逐级压缩分辨率就得到了:
- 近期对话 (<3天):高分辨率(800+tokens),保留完整的语义;
- 一周前对话:中等分辨率(256 tokens),保留主干内容;
- 久远记忆(>1个月):低分辨率 (64 tokens),仅仅保留概要印象
这种方式可不是简单的截断或者丢弃,让信息随着时间自然衰减:模型依然可以”看到“过去,但是细节越来越模糊,就像你经常回味过去的事情一样。 这样控制了token消耗,也保留了记忆的连续性。
启示:遗忘不是缺陷,而是一种优化策略。真正的智能不在于记住一切,而在于知道什么值得高保真保存,什么可以优雅淡化。
3.2.2 赋予用户遗忘控制权
我们还得和用户的伦理结合起来:
允许用户通过自然语言命令主动接管记忆,比如说:
- 忘记我说的话
- 不要再和我提前任的事情了
- 我不希望你记住我的住址,请忘掉
- 系统应该支持选择性遗忘:不是删除整段历史,而是降低特定话题的记忆权重或者直接设置”静音“。
3.2.3 实现情景化的记忆召回
值得我们注意的是,遗忘并不等于删除。人类的遗忘只不过是记不起细节,并不是信息消失了。 一样的道理,AI的记忆系统应该支持按需唤醒:
当用户明确提及到某个时间点(“你还记得上个月我说要辞职吗?”)系统就可以临时加载这个片段的高分辨率版本。这需要一个高效的索引机制(基于时间,关键词,情绪标签的元数据),快速的定位到历史片段。
遗忘是常态,召回则是特例
我们的习惯认知可能会认为,上下文长度就是硬性指标,越长就越好。实际上并非如此!长度和质量没有正相关。适度的遗忘反而可以提高系统表现:因为可以减少无关干扰,降低计算成本,聚焦当前的情境。
3.3 上下文污染与一致性维护
当上下文过长或者混乱的时候,就可能会出现“上下文污染”,也就是说AI被无关信息干扰了,导致回复偏离了主题。
常见的防范措施有:
- 在prompt中明确“当前任务”和“对话目标”
- 使用分隔符或者标签清晰区分不同类型的上下文(【记忆】、【对话历史】)
- 定期重置上下文,避免“对话漂移”。
除此之外,还需要确保AI角色一致性。比如说,设定“温柔的倾听者”。就不应该在后续的对话里突然变得“理性分析”起来。
4. 项目案例,我们来升级一下记忆系统
4.1 需求:
”kaguya“需要具备:
- 记住用户的情绪变化趋势
- 回应用户提到的生活事件
- 保持温暖、稳定的人格
- 支持跨会话记忆
4.2 以此,我们来进行系统的架构升级
src/
│... 其它代码
└── app/
├── routers/
│ ├── chat.py
│ │ # 对话接口路由
│ │ # 例如 POST /chat
│ │ # 接收用户消息,调用 chat feature
│ ├── memory.py
│ │ # 记忆相关接口
│ │ # 例如查询记忆、写入记忆、删除记忆
│ ├── evaluation.py
│ │ # 评估相关接口
│ └── feedback.py
│ # 用户反馈相关接口
│
├── features/
│ ├── chat/
│ │ ├── schemas.py
│ │ └── service.py
│ │ # chat 主业务编排
│ │ # 串联 context、memory、engine
│ │
│ ├── context/
│ │ ├── schemas.py
│ │ ├── assembler.py
│ │ │ # 上下文组装器
│ │ │ # 负责拼接 history / memory / prompt / RAG 文档
│ │ └── service.py
│ │ # context 编排层
│ │ # 决定本轮取哪些上下文、裁剪顺序和优先级
│ │
│ ├── memory/
│ │ ├── schemas.py
│ │ ├── extractor.py
│ │ │ # 记忆提取器
│ │ │ # 从对话中抽取可沉淀的长期信息
│ │ ├── manager.py
│ │ │ # 记忆管理器
│ │ │ # 负责去重、更新、合并、生命周期管理
│ │ └── service.py
│ │ # memory 编排层
│ │ # 连接 extractor / manager / infra
│ │
│ └── evals/
│ ├── schemas.py
│ └── service.py
│ # 评测执行与 judge 评审服务
│
├── infra/
│ ├── database.py
│ │ # 普通数据库接入
│ │ # 适合存用户、记忆元数据、反馈、评测记录
│ └── vector_store.py
│ # 向量数据库接入
│ # 适合记忆检索、RAG 检索
│
├── core/
│ ├── schemas.py
│ │ # 全局通用模型
│ ├── engine.py
│ │ # 模型调用引擎
│ ├── prompt_loader.py
│ │ # prompt 读取
│ └── prompts.py
│ # 常用 prompt 注册
│
├── config/
│ ├── schemas.py
│ │ # 配置对象模型
│ └── settings.py
│ # 配置加载入口
│
└── prompts/
# 各类 prompt 文件
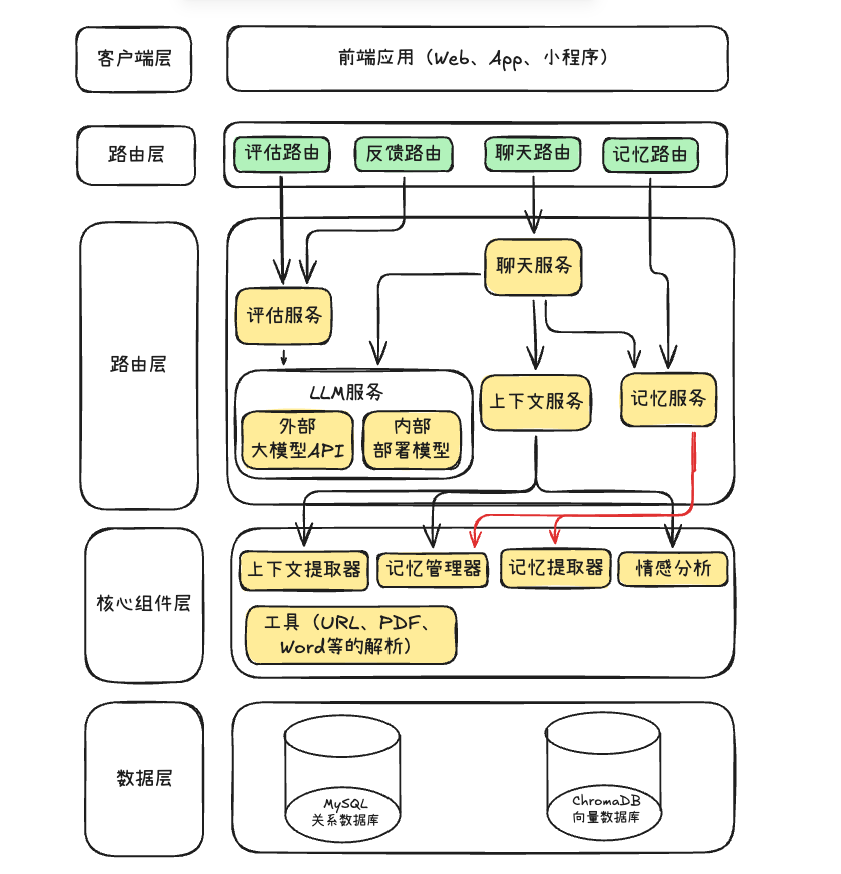
上下文管理,主要就是对后端进行升级,升级之后的目录如上↑
然后,这个聊天架构就会被分成客户端层、路由层、服务层、核心组件层、数据层、关联外部大模型API(Deepseek,Qwen,ChatGPT等 LLM服务);客户端层的前端应用通过路由层的评估、反馈、聊天、记忆路由,对接服务层的评估服务、聊天服务等等。聊天服务则依托上下文服务、记忆服务,结合核心组件层的上下文组装器、记忆管理器、记忆提取器、情绪分析器,和MySQL关系数据库,ChromaDB向量数据库进行交互,评估服务调用外部API,各层协同支撑聊天能力。
4.3 关键实现步骤
在“kaguya”机器人背后,一次看似自然的对话,实际上到底经历了什么,经过了怎么样的一场精密的记忆旅程?
如图所示: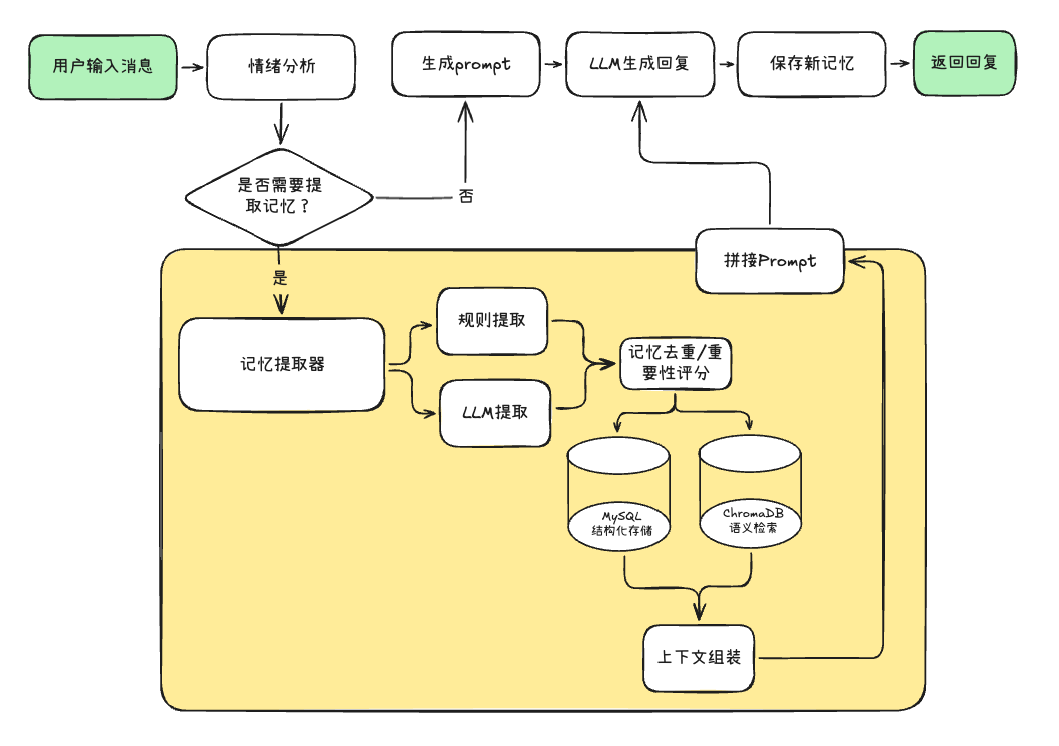
对照流程图,我们分别看看每个处理阶段的详细情况
4.3.1 步骤一:用户输入处理阶段
首先由用户输入消息,系统接收用户的文本输入。之后就是情绪分析,使用情绪分析器对用户消息进行情感识别,判断情绪类型和强度。
比如,用户说:“我好焦虑,我要撑不住了。。。”
系统接收到输入内容之后,并不会直接生成回复,而是先启用情绪分析器。就像一个经验老道的咨询师敏锐捕捉到语气里的颤抖一样,我们的AI也会判断这句话之后的情绪类型(焦虑?愤怒?绝望?)甚至可以分析出强度的等级。
如果情绪足够的强烈,例如我们定一个规则,7级以上就算一个警示等级。或者文本里出现了“辞职“、”分手“等关键词,那么系统就会意识到:这是一个关键的节点,需要被记住。
并非所有的对话都需要被记忆,通过智能决策避免过度检索,节省资源,也可以防止打扰用户当前的情绪波动
4.3.2 步骤二:记忆提取决策阶段
接下来的问题:要不要去查询一下用户以前说过什么?
你看,比如说哪一天你朋友突然来一句:”我靠那个新出的电影超级好看!“。但是你还记得他两周前还说,他从来不去电影院看电影。你本来该一起说,我靠电影确实精彩。但是如果你突然来一句:”你不是说你不去电影院看电影吗?“ 这个时候就尴尬起来了。
所以要怎么判断记忆有没有必要提取?根据消息的内容和情绪强度判断是否需要检索历史记忆。决策条件如下:
- 情绪强度 > 7级
- 包含关键词(面试,考试,分手等)
- 消息长度 > 30 而且 情绪强度 > 5级
所以说,”是否唤醒记忆“是一次谨慎的选择。当内容足够重要、情绪足够浓烈的时候,系统才会触发记忆提取流程。
4.3.3 步骤三:记忆提取阶段
一旦决定回溯,记忆提取器便开始工作。它采用一种“人机协作”的策略:
- 规则引擎像一名档案管理员,快速扫描结构化信息:有没有提到具体事件?是否做出了承诺?是否有明确的人际关系描述?
- 大语言模型辅助提取则像一位心理分析师,深入语义层面,提炼出那些隐含在意境中的关键线索,比如“最近总觉得自己不够好”背后的自我怀疑倾向。
提取完成后,系统还会自动去重,并为每条记忆打上“重要性分数”,确保最有价值的信息优先浮现。
4.3.4 步骤四 记忆存储与检索阶段
这些珍贵的记忆存放在哪里?我们采用了双数据库架构:
- MySQL 负责存储结构化的用户画像和对话元数据,比如姓名、偏好、上次登录时间等,适合精确查询。
- ChromaDB 作为向量数据库,则把每一句对话转化为语义向量,支持“模糊匹配”式的联想检索——哪怕用户换了一种说法,也能找到相关的过往经历。
这就像是既有工整的档案柜,也有充满灵感的灵感墙,两者互补,让记忆既准确又有温度。
4.3.5 步骤五 上下文组装阶段
面对海量记忆,不能一股脑儿塞给AI。我们需要一个“编辑部”来精选素材。
上下文组装器会根据以下原则筛选最相关的记忆片段:
- 最多召回3条最相关的内容(Top-K)
- 优先考虑近7天内的近期记忆
- 只保留重要性评分高于0.5、相似度超过0.3的记忆
这样一来,AI不会被陈年旧事干扰,也不会因信息过载而迷失重点。
4.3.6 步骤六 上下文构建阶段
现在,我们手握三类拼图:
- 用户画像:你是谁?性格如何?喜欢怎样的沟通方式?
- 长期记忆:你曾分享过的重大事件、反复出现的情绪模式;
- 短期上下文:最近5轮对话的历史,保持对话连贯。
上下文组装器将它们融合成一份个性化的“对话背景报告”,成为AI理解你的完整依据。
4.3.7 步骤七 Prompt生成与LLM调用阶段
这份精心构建的上下文,最终会被嵌入到一个结构化Prompt模板中,传给大模型。模板中不仅包含你的故事,还有AI的角色设定:“你是一位温暖、耐心的心理陪伴者,请用共情而非评判的方式回应。”
于是,AI不再是冷冰冰的知识机器,而是一个“知道你经历过什么”的对话伙伴。
4.3.8 步骤八 记忆更新与响应返回阶段
对话结束前,系统还会悄悄完成最后一步:把这次交流中的新信息,如情绪变化、新事件、新的应对方式,重新编码并存入双数据库。
4.3.9 总结
记忆系统的核心技术特点:
- 智能记忆提取:结合规则和LLM双重的策略,确保关键信息不遗漏
- 双数据库架构:向量数据库支持语义化检索,关系数据库支持结构化数据查询
- 多维度检索:时间、重要性、相似度等多个维度
- 个性化上下文:基于用户画像和历史记忆构建个性化对话上下文
- 分层架构设计:Router -> Service -> core -> data。便于维护与拓展
5. 产品经理维度的考量
说点开发之外的事情,最近随着新闻报道越来越多AI失业的事情,让我开始思考,我或许应该掌握一些技术之外的东西,所以才有这个部分的加更,我想从产品经理的角度思考一个项目还有什么东西是我们没想到的,比如:产品哲学和伦理自觉。
5.1 记忆的提取方式:应该自然而然,而不是监控
AI提及到用户的过去的时候,会直接影响到信任的感知,比如说:
- “我记得你上周失眠了三天” —— 就会产生被监听的不适应感
- ”你之前提到了睡眠有点困扰,现在你有改善了吗?“ —— 这种表述就是体现关怀,避免了监控感。
关键在于,让用户感觉到”被理解“,而不是”被记录“
5.2 透明性:让用户知道,你在记忆什么
就如同ChatGPT一样,应该明确地告知用户哪些信息要被保留、如何使用、应该保存多久:
- 在首次提到以前的过往内容时候,提示”根据您以前的分享,我注意到。。。“
- 提供清晰的隐私说明页,解释记忆机制和数据流向
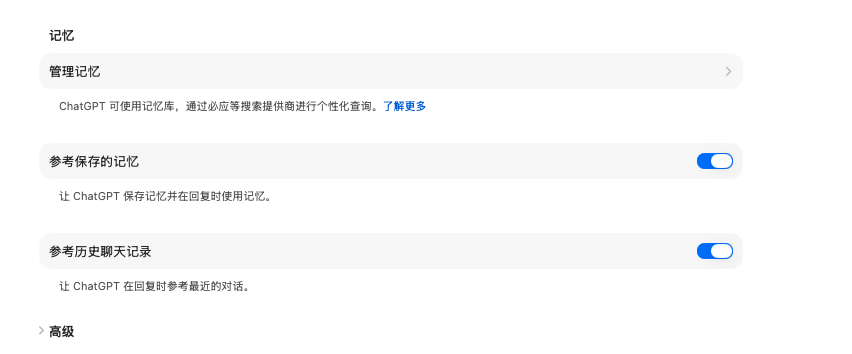
5.3 可控:让用户拥有”记忆管理权“
真正的信任来源于掌握,用户理应有权利管理记忆:
也是一样,让我们参考ChatGPT:
5.4 隐私边界: 最小化、选择性以及遗忘
最小化原则:只要记住必要的,不要进行贪婪收集
记住用户喜欢清淡饮食是合理的,但是如果记住用户每周的点餐记录那就有点越界了
选择性记忆:
记住用户的爱好是加分项,但是频繁主动提及那就很有压迫感了
比如:- 过度 = 冒犯: ”你昨天没听推荐的歌,是不是心情不好?“
- 适当 = 贴心:”你想试试上次说想听的那种音乐吗?“
遗忘的艺术
- 当用户刻意避免某个话题的时候,AI会感知并且主动转移话题
- 对敏感话题(心理困扰、失败经历)设置自动衰减机制,随着时间淡化记忆权重
- 支持”情境性遗忘“ —— 在新对话中不强行延续旧话题,除非用户主动提及。
5.5 情感分寸
- 警惕情感依赖风险
- 拒绝扮演专业角色
- 主动引导回归现实
问题
假设你需要为一款面向大学生的情感陪伴 AI(主打缓解学业压力、人际关系焦虑)设计上下文管理系统,已知核心用户场景如下:
- 学生 A 每周三晚固定吐槽 “小组作业分工不均”,持续了 3 周,本周突然提到 “这次小组合作很顺利”;
- 学生 B 曾透露 “怕考英语六级”,1 个月后分享 “六级过了”,但未主动提及之前的焦虑;
- 多位学生反馈 “不希望 AI 频繁直白地说‘我记得你上次提过 XX’”,觉得有 “被监视感”。
那么问题来了:
- 你会优先选择哪两种技术方案组合构建该 AI 的记忆系统?请说明选择理由(需对应学生场景痛点)?
- 针对避免用户产生被监控感的问题,你会设计怎样的 “记忆提及方式”?请举例说明(比如学生 B 分享 “六级过了” 时,AI 如何回应)?
点击查看答案
我会选择summary + 结构化记忆来构建AI的记忆系统,然后以History 为辅助,保证通话的连续性,RAG + 向量数据库作为长周期挑选候选记忆的手段,但是不直接喂给LLM。
短期记忆并不会记住一个月之后的那种事情,所以先pass,另外,RAG 这类长记忆提及容易导致记忆被记住的太过久远,产生被监视的感觉。
为了避免监控感,可以使用few-shot来写例子,控制输出的情绪,记忆确实需要存在,但是表达一定要克制。