在上一篇文章中,我们是直接用的OpenAI的原生API去使用Function Calling(Tools)功能,正如我们文末总结的那样,自己写需要自己维护历史,写参数类型,自己实现函数的调用,比较繁琐。
在这里,我要试试在Langchain使用该功能,会极大的减缓使用门槛,并且很容易集成到现在有的Chain里。
在Langchain使用Tools
在Langchain里,一般用zod来定义Tools函数的JSON Schema。我们可以专注在参数的描述上面,参数的类型定义和require都交给zod来做。在后续定义Agent Tool的时候,zod也可以加入进行辅助的参数类型检查。
deno install zodzod的用法
简单讲讲zod怎么用。zod是JS生态常见的类型定义和验证的工具库:
import { z } from 'zod'
const stringSchema = z.string()
stringSchema.parse("hi")
stringSchema.parse(123) // Error: Invalid input: expected string, received number这里就会报错:
Stack trace:
ZodError: [
{
"code": "invalid_type",
"expected": "string",
"received": "number",
"path": [],
"message": "Expected string, received number"
}
]报错信息的可读性也很高,这种交给LLM去读取也是非常有效,可以高效地纠正自己的错误。
下面再给一系列的示例来迅速地介绍足够定义Tools参数的zod知识:
import { z } from 'zod'
// 基础类型
const stringSchema = z.string()
const numberSchema = z.number()
const booleanSchema = z.boolean()
// 数组
const stringArraySchema = z.array(z.string())
stringArraySchema.parse(["hi", "there"])
// 对象
const personSchema = z.object({
name: z.string(),
age: z.number(),
// 可选字段
isStudent: z.boolean().optional(),
// 默认值
home: z.string().default("sichuan")
})
// 联合类型
const stringOrNumber = z.union([z.string(), z.number()])
stringOrNumber.parse("hi")
stringOrNumber.parse(123)考虑到方便LLM调用,以便于让它理解参数和传递参数,我们一般不会把参数设置的过于复杂,否则容易让LLM犯错。
使用zod来定义函数的Schema
让我们继续说回之前的那个天气函数,我们用zod来定义Schema
import { z } from "zod"
const getCurrentWeatherSchema = z.object({
location: z.string().describe("The city and state, e.g San Francisco, CA"),
unit: z.enum(["celsius", "fahrenheit"]).describe("The unit of temperature")
})这里就是定义了两个参数
- location是string类型,并且添加了描述
- unit就是枚举类型,并且也添加了对应的描述
我们没有指定optional,默认就是require的
可以使用zod-to-json-schema来把zod定义的Schema转换为JSON Schema:
zod-to-json-schemaimport { zodToJsonSchema } from "zod-to-json-schema"
...
const paramsSchema = zodToJsonSchema(getCurrentWeatherSchema)
paramsSchema我们就可以转换为OpenAI Tools需要的JSON Schema了:
{
type: "object",
properties: {
location: {
type: "string",
description: "The city and state, e.g San Francisco, CA"
},
unit: {
type: "string",
enum: [ "celsius", "fahrenheit" ],
description: "The unit of temperature"
}
},
required: [ "location", "unit" ],
additionalProperties: false,
"$schema": "http://json-schema.org/draft-07/schema#"
}紧接着,我们就可以在Model里去使用这个tools定义:
import { load } from "dotenv"
const env = await load()
const process = {
env
}
import { ChatOpenAI } from "@langchain/openai";
const chatModel = new ChatOpenAI({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
modelName: process.env.OPENAI_MODEL,
temperature: 0,
})
const modelWithTools = chatModel.bind({
tools: [
{
type: "function",
function: {
name: "getCurrentWeather",
description: "Get the current weather in a given location",
parameters: paramsSchema
}
}
]
})
await modelWithTools.invoke("成都的天气怎么样?");
看看输出:
AIMessage {
lc_serializable: true,
lc_kwargs: {
content: "",
additional_kwargs: {
function_call: undefined,
tool_calls: [
{
id: "call_IIg2WjdJ7BXU45mDyeXtOtWc",
type: "function",
function: [Object]
}
]
},
response_metadata: {}
},
lc_namespace: [ "langchain_core", "messages" ],
content: "",
name: undefined,
additional_kwargs: {
function_call: undefined,
tool_calls: [
{
id: "call_IIg2WjdJ7BXU45mDyeXtOtWc",
type: "function",
function: {
name: "getCurrentWeather",
arguments: '{"location":"成都, 中国","unit":"celsius"}'
}
}
]
},
response_metadata: {
tokenUsage: { completionTokens: 23, promptTokens: 81, totalTokens: 104 },
finish_reason: "tool_calls"
}
}这里面就是一个AIMessage的信息,携带着跟tool call有关系的信息。
看起来和我们之前用原生的OpenAI API的结果是类似的,加了一些Langchain内部用的信息。
注意:
这里我用到的bind并不是Model特有的一个工具,是所有的Runnable都有的方法,可以把Runnable需要的参数传入进去,返回一个只需要其它参数的Runnable对象。
因为绑定Tools之后的Model依然是一个Runnable对象,所以我们可以很方便地把它加到LCEL链里!
import { ChatPromptTemplate } from "@langchain/core/prompts"
const prompt = ChatPromptTemplate.fromMessages([
["system", "You are a weather bot. You can answer questions about the weather."],
["human", "{input}"]
])
const chain = prompt.pipe(modelWithTools)
await chain.invoke({
input: "成都天气如何?"
})我们得到的是一样的结果:
AIMessage {
lc_serializable: true,
lc_kwargs: {
content: "",
additional_kwargs: {
function_call: undefined,
tool_calls: [
{
id: "call_ukLLcEa57HYHVYKAe3r8jEoO",
type: "function",
function: [Object]
}
]
},
response_metadata: {}
},
lc_namespace: [ "langchain_core", "messages" ],
content: "",
name: undefined,
additional_kwargs: {
function_call: undefined,
tool_calls: [
{
id: "call_ukLLcEa57HYHVYKAe3r8jEoO",
type: "function",
function: {
name: "getCurrentWeather",
arguments: '{"location":"成都, 中国","unit":"celsius"}'
}
}
]
},
response_metadata: {
tokenUsage: { completionTokens: 23, promptTokens: 94, totalTokens: 117 },
finish_reason: "tool_calls"
}
}多tools model
同样的,我们也可以在model里面去绑定多个tools,就跟之前我们用OpenAI的API类似。我们再用Zod声明一个getCurrentTimeSchema:
const getCurrentTimeSchema = z.object({
format: z.enum(["iso", "locale", "string"]).optional().describe("The format of the time, e.g iso, locale, string")
})
const getCurrentTimeParamsSchema = zodToJsonSchema(getCurrentTimeSchema)注意,我们这里使用了optional工具函数,所以输出的JSON Schema就不会把这个参数视为require:
{
type: "object",
properties: {
format: {
type: "string",
enum: [ "iso", "locale", "string" ],
description: "The format of the time, e.g iso, locale, string"
}
},
additionalProperties: false,
"$schema": "http://json-schema.org/draft-07/schema#"
}使用多个tools的代码也是一样的:我们重新写一个modelWithMultiTools,会根据用户的输入和上下文去调用合适的Function:
...
const modelWithMultiTools = chatModel.bind({
tools: [
{
type: "function",
function: {
name: "getCurrentWeather",
description: "Get the current weather in a given location",
parameters: getCurrentWeatherParamsSchema
}
},
{
type: "function",
function: {
name: "getCurrentTime",
description: "Get the current time in a given location",
parameters: getCurrentTimeParamsSchema
}
}
]
})
await modelWithMultiTools.invoke("现在是什么时候?成都的天气怎么样?");控制model对于tools的调用
还是一样,我们可以像使用API一样通过tool_choice来控制LLM调用函数的行为:
比如我不允许调用函数:
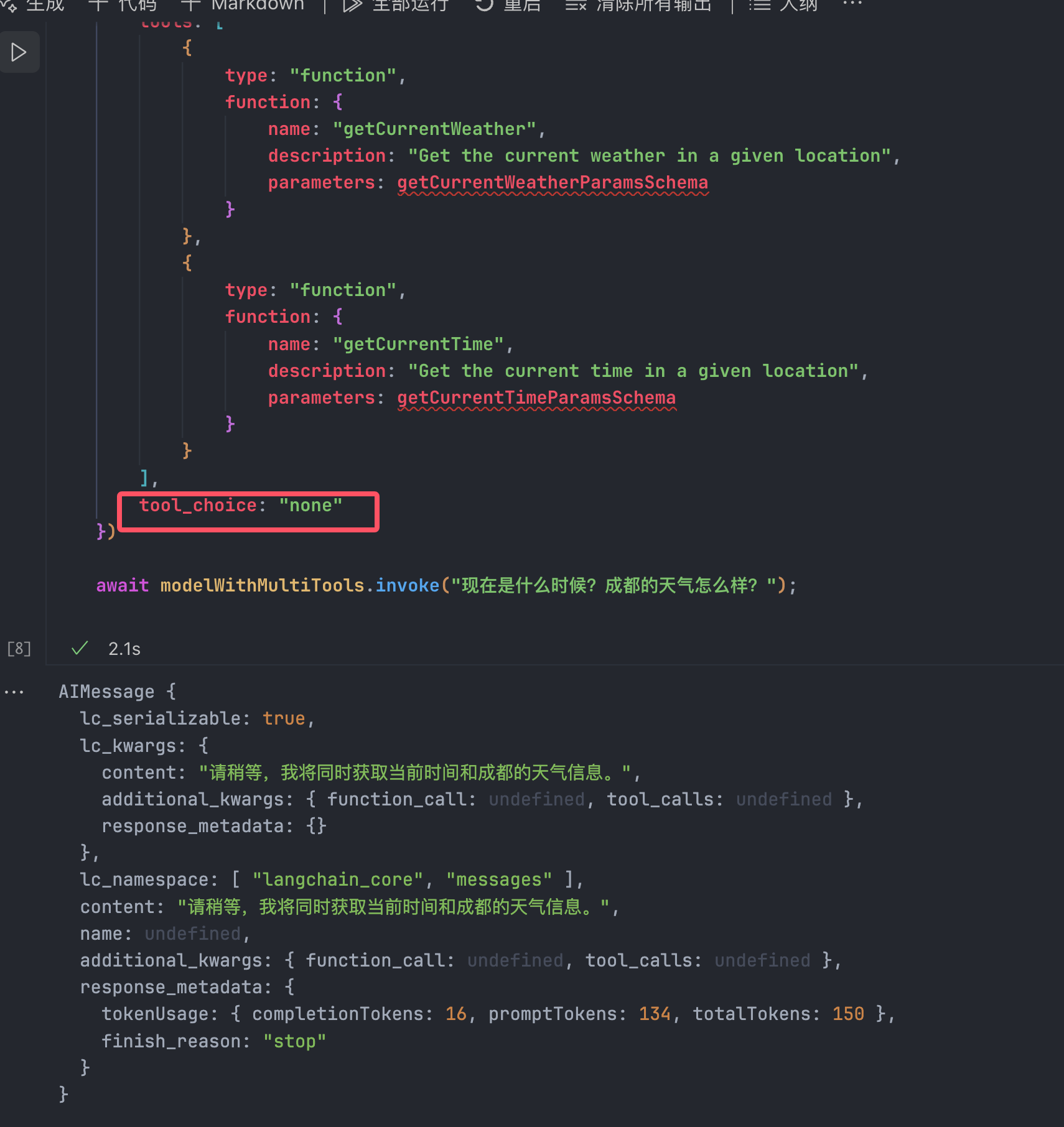
强制调用某个函数:
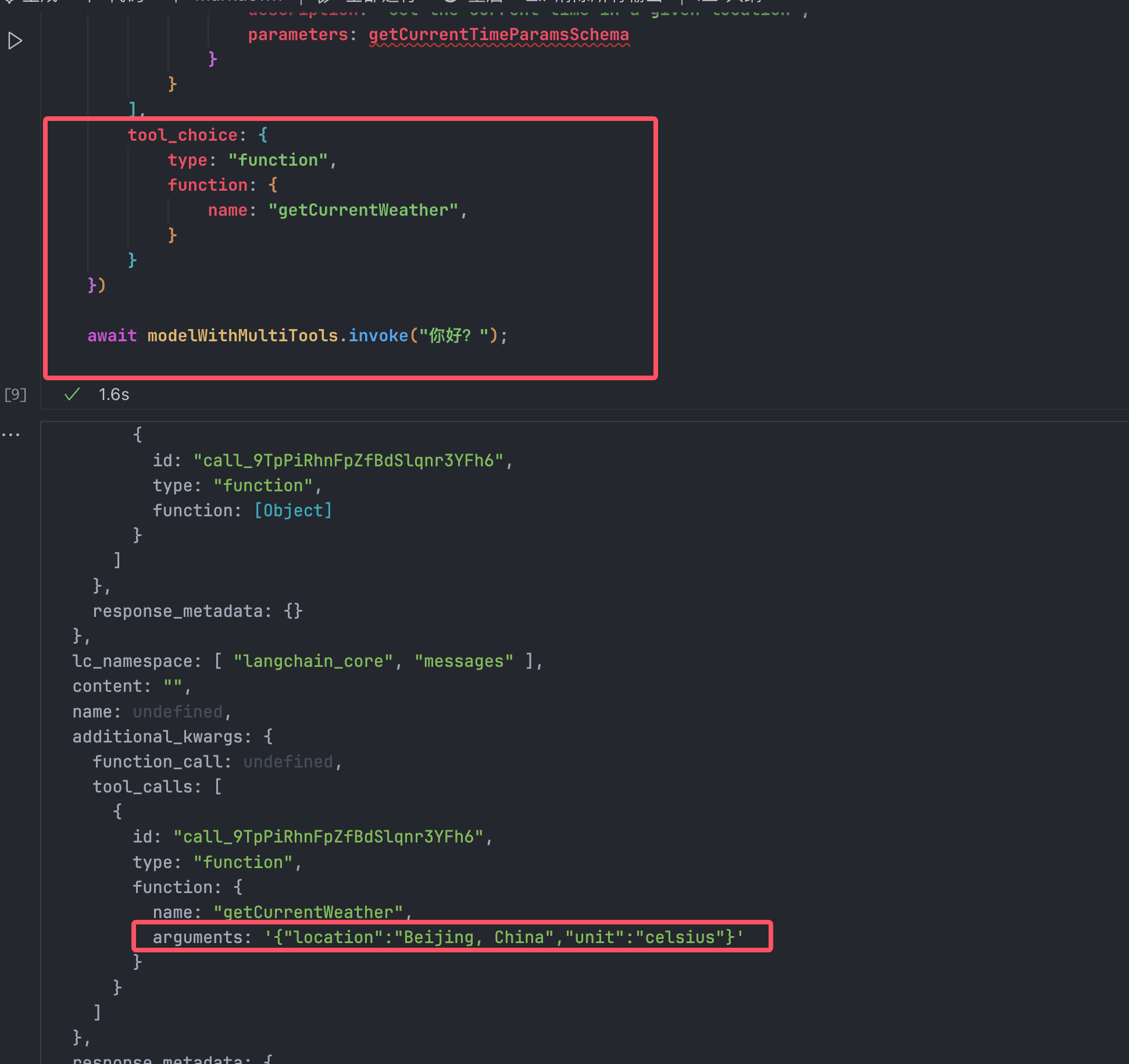
如出一辙,也是产生了严重的幻觉。
使用Tools给数据打标签
数据预处理的时候,给数据打标签是很常规的操作。
在LLM没有出来之前,与自然语言有关系的任务基本都是交给了python的深度学习来处理。
但是有了LLM之后,除了专业领域之外的绝大部分的任务都可以由它完全胜任。
得益于LLM展现出来的非常强大的跨语言理解能力,我们的工具可以针对任何的语言,甚至可以让LLM分辨使用了什么语言。这些任务在LLM之前都需要很复杂的处理才可以实现。
我们先来定义一下提取信息的函数Schema:
const getTagSchema = z.object({
emotion: z.enum(["pos", "neg", "neutral"]).describe("文本情感"),
language: z.string().describe("文本的核心语言(应该是ISO 639-1代码)"),
});
const getTagParamsSchema = zodToJsonSchema(getTagSchema);这里有两个参数,一个是态度,一个是语言
这里要对于没有做过数据分析的小伙伴们解释一下我的设定:
- emotion给出的三个参数,pos代表积极的、neg代表消极的、neutral代表中性的。
- 第二个参数是语言,理论上我们会强调提取文言的核心语言种别,来应对部分多语言混杂的情况,如果你对语言的准确性非常的看重,我们可以在这里加入更多的描述,比如:语言占比超过60%视为主体语言。
在我们执行数据标签的过程中,就如同我上一篇文章说到的那样,我们要强制调用这个函数,以确保LLM对于任何输入都会执行数据标签的分析。
const modelTagging = chatModel.bind({
tools: [
{
type: "function",
function: {
name: "getTag",
description: "为特定的文本获取标签",
parameters: getTagParamsSchema
}
}
],
tool_choice: {
type: "function",
function: {
name: "getTag",
}
}
})然后我们来组合为Chain:
import { JsonOutputToolsParser } from "@langchain/core/output_parsers/openai_tools"
const prompt = ChatPromptTemplate.fromMessages([
["system", "仔细思考,你有充足的时间进行严谨的思考,然后按照指示对文本进行标记。"],
["human", "{input}"]
])
const chain = prompt.pipe(modelTagging).pipe(new JsonOutputToolsParser())这里我们用到的提示词,是一种常用的技巧,有论文验证过,这些词就像是说了就会奏效的魔法单词,加入之后会显著提高输出的质量。
这种方法被称为“自我反思”(self-reflection),通过在提示中加入类似的引导语,模型会倾向于生成更准确和详细的回答。
另外,我们只需要LLM输出的JSON标签,所以使用JsonOutputToolsParser直接拿到Tools的JSON输出就行了。
测试一下:
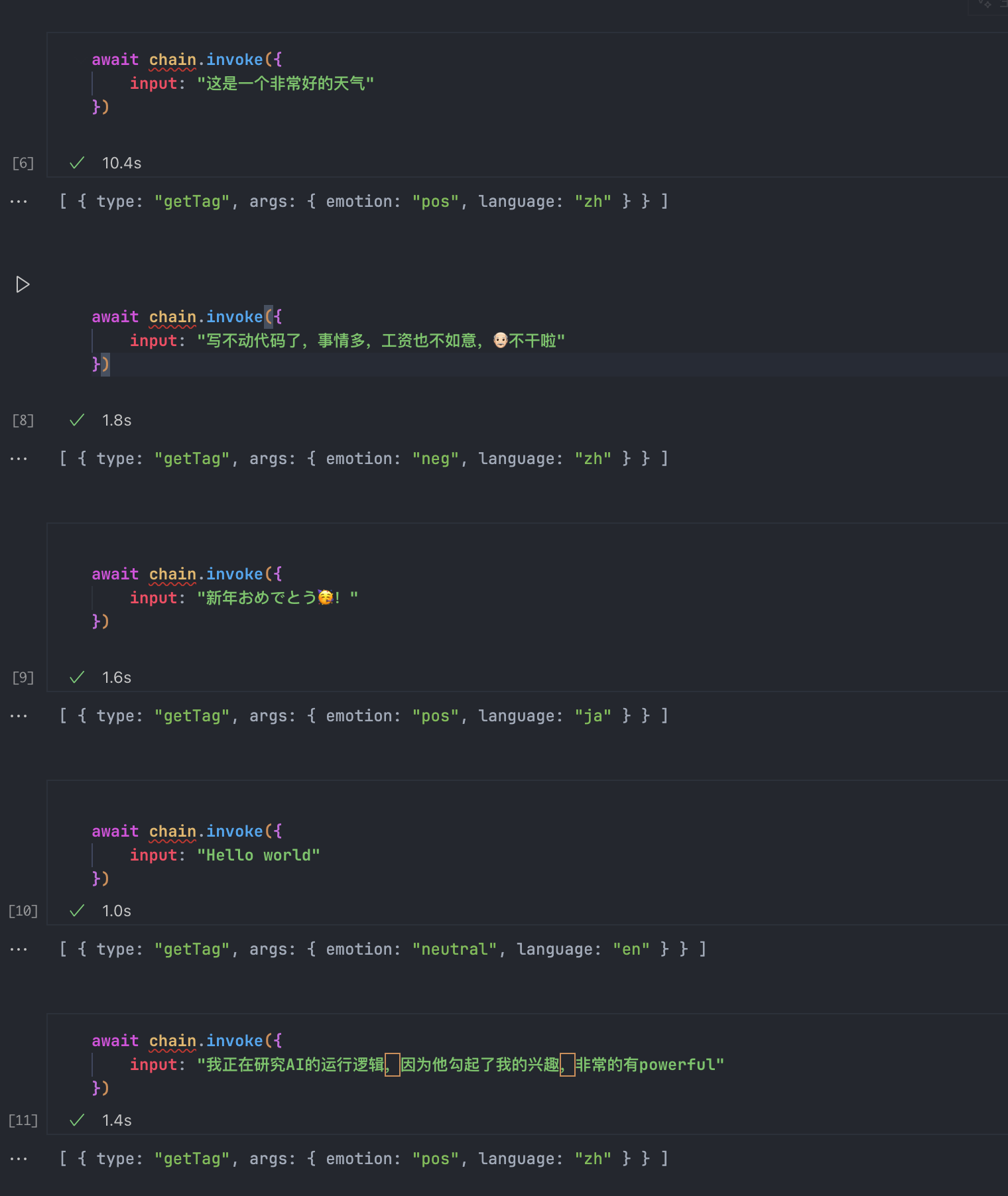
喏,可以看到,我们声明了提取数据中的核心语言,即便是最后一个这种中英双语的情况,也还是可以得到正确的信息。
在这里展示的就是LLM的Zero-shot learning能力 (零样本学习)。
指的就是:在没有明确的任务示例或训练数据的情况下,模型仅通过prompt来完成一个新的任务
使用Tools进行信息提取
我们再看tools的另一个用法,那就是信息的提取。和打标签有点像,在实际工程中不做过多的区分。
直观上就是打标签给数据打上给定的一些标记
信息提取就是LLM理解原始文本之后,提取里面的信息
类似于黏贴地址,然后自动识别姓名手机地址。
来写一个描述一个人的信息的Schema:
const personalExtractionSchema = z.object({
name: z.string().describe("人的名字"),
age: z.number().optional().describe("人的年龄"),
}).describe("从文本中提取个人信息");把age设计成非必选的number,因为年龄可能是没有的,避免LLM瞎搞一个。通过对整个Object添加describe来让LLM对整个对象有一个更多的理解。
随后,基于这个来构建一个更加上层的Schema,从信息里提取到更多的复杂信息:
const relationExtractionSchema = z.object({
people: z.array(personalExtractionSchema).describe("提取所有人"),
relation: z.string().describe("人与人之间的关系,简洁描述"),
})
const schemaParams = zodToJsonSchema(relationExtractionSchema)复用了personalExtractionSchema来构建数组的Schema,提取信息里多人的信息,并且提取文本中人物之间的关系。
得益于LLM的良好语言能力,我们只需要简单的给出Prompt就可以让LLM在信息提取任务上有出色的表现。
看一下schemaParams的值:
{
type: "object",
properties: {
people: {
type: "array",
items: {
type: "object",
properties: { name: [Object], age: [Object] },
required: [ "name" ],
additionalProperties: false,
description: "从文本中提取个人信息"
},
description: "提取所有人"
},
relation: { type: "string", description: "人与人之间的关系,简洁描述" }
},
required: [ "people", "relation" ],
additionalProperties: false,
"$schema": "http://json-schema.org/draft-07/schema#"
}构建Chain:
const modelExtract = chatModel.bind({
tools: [
{
type: "function",
function: {
name: "extractRelation",
description: "从文本中提取人与人之间的关系",
parameters: schemaParams
}
}
],
tool_choice: {
type: "function",
function: {
name: "extractRelation",
}
}
})
const prompt = ChatPromptTemplate.fromMessages([
["system", "仔细思考,你有充足的时间进行严谨的思考,然后提取文中的相关信息,如果没有明确提供,请不要猜测,可以仅提取部分信息"],
["human", "{input}"]
])
const chain = prompt.pipe(modelExtract).pipe(new JsonOutputToolsParser())我们继续用“自我反思”的提示词去增强输出的质量,然后用if else的方式来让LLM知道,如果没有明确提供,不要猜测,可以只提取部分信息,来减少LLM的幻想。
await chain.invoke({
input: "李雷和韩梅梅是一对情侣"
})测试一组简单的任务:
[
{
type: "extractRelation",
args: { people: [ { name: "李雷" }, { name: "韩梅梅" } ], relation: "情侣" }
}
]这里我没有提及两人的年龄,LLM也就没有返回了。
再来测试一下,并不直白的表达内容的情况:
await chain.invoke({
input: "八六今年25岁,是个程序员,我和A,B,C是好朋友,大家年龄都一样"
})得到的结果:
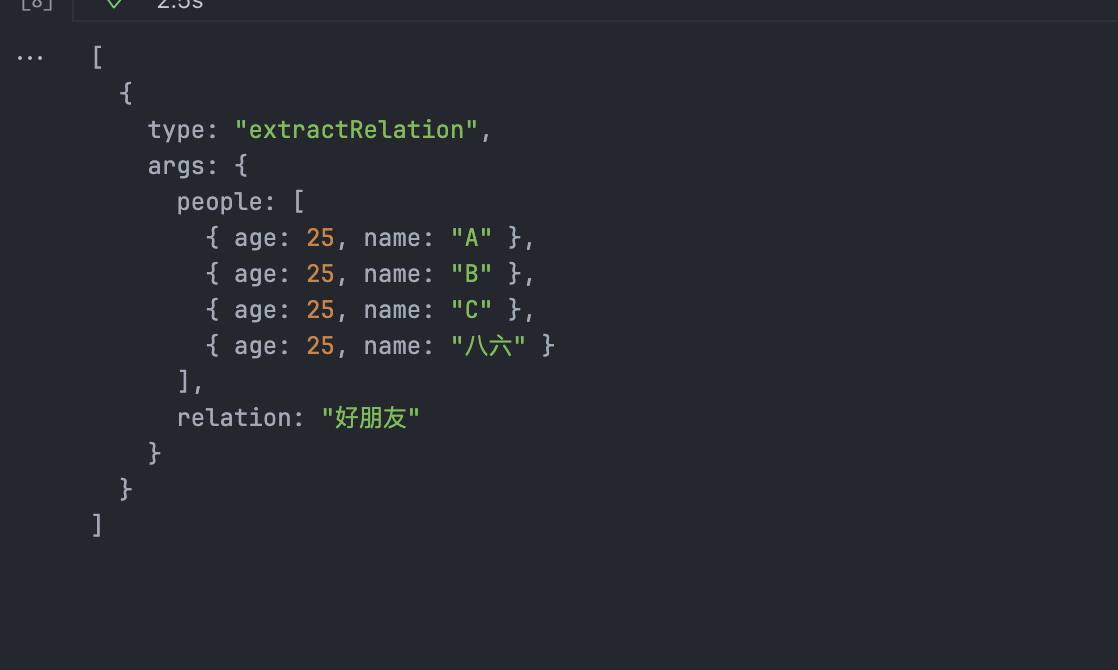
这就是LLM对语言有理解能力,而不是依靠正则表达式这种传统的匹配规则,所以在语义中隐含的信息也可以提取出来。
对于边缘情况,也有比较好的处理:
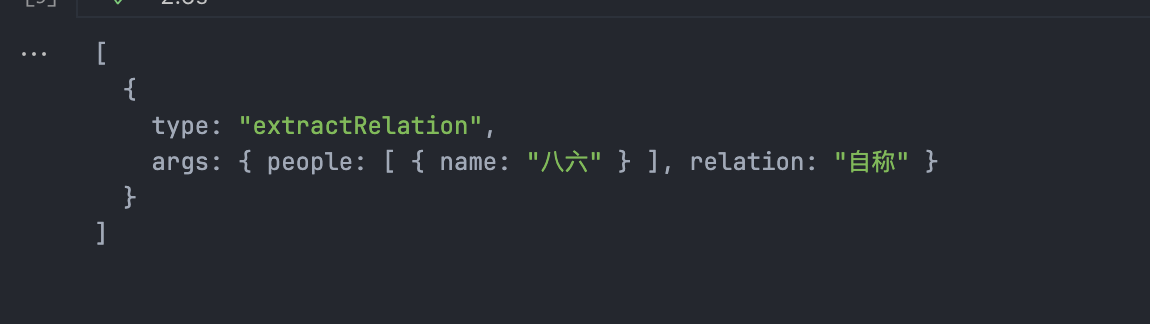
await chain.invoke({
input: "我是八六"
})
总结
在这里,我提及了Langchain里面使用OpenAI tools的情况,通过zod减少了编写Schema的繁琐。
学习了使用tools来给数据打标签,以及提取数据。
LLM不仅仅是chatbot,也可以处理日常的很多任务,解决传统编码中,要复杂编码才可以解决的问题!