添加uuidv4(客户端)传来的对话id
考虑到项目以后的功能,这边要加上一个功能,就是用于构建短期记忆和长期记忆区分conversation的id。
大概的感觉就是我做出的导图: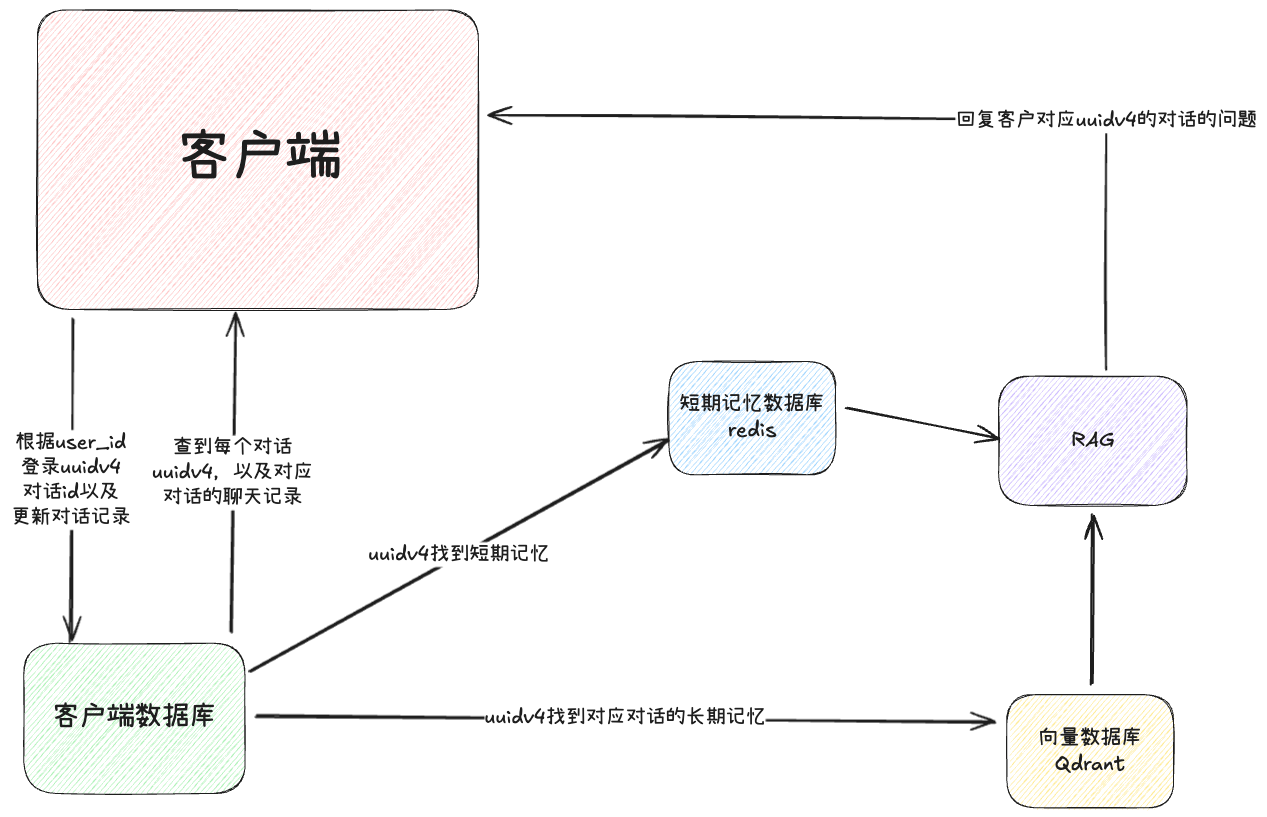
客户端与之对应的数据库都可以随便选择,我们之后再做,现在我们要看看如何在我们的demo里面添加uuidv4的参数并且做到让向量数据库根据uuidv4找到我们的长期记忆,以及让redis(实际项目里)找到对应的短期记忆,因为我们做的时候使用JSON本地文件来模拟的数据库,所以这里也一样用JSON,redis可以后续自行处理,也很简单。
- 我们先给lastRagChain加上uuid的传递参数:

- 长期和短期记忆都加上对应的参数做传递:

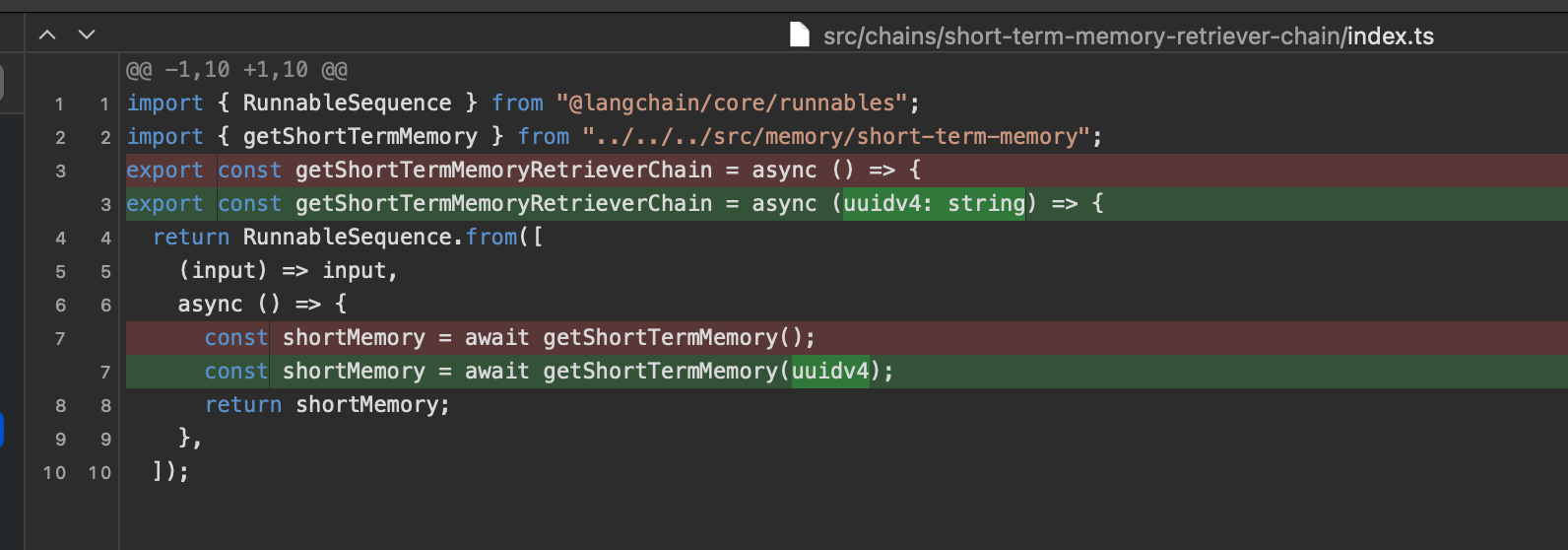
- 短期记忆的具体实现方法,存和取都加上uuid来处理:
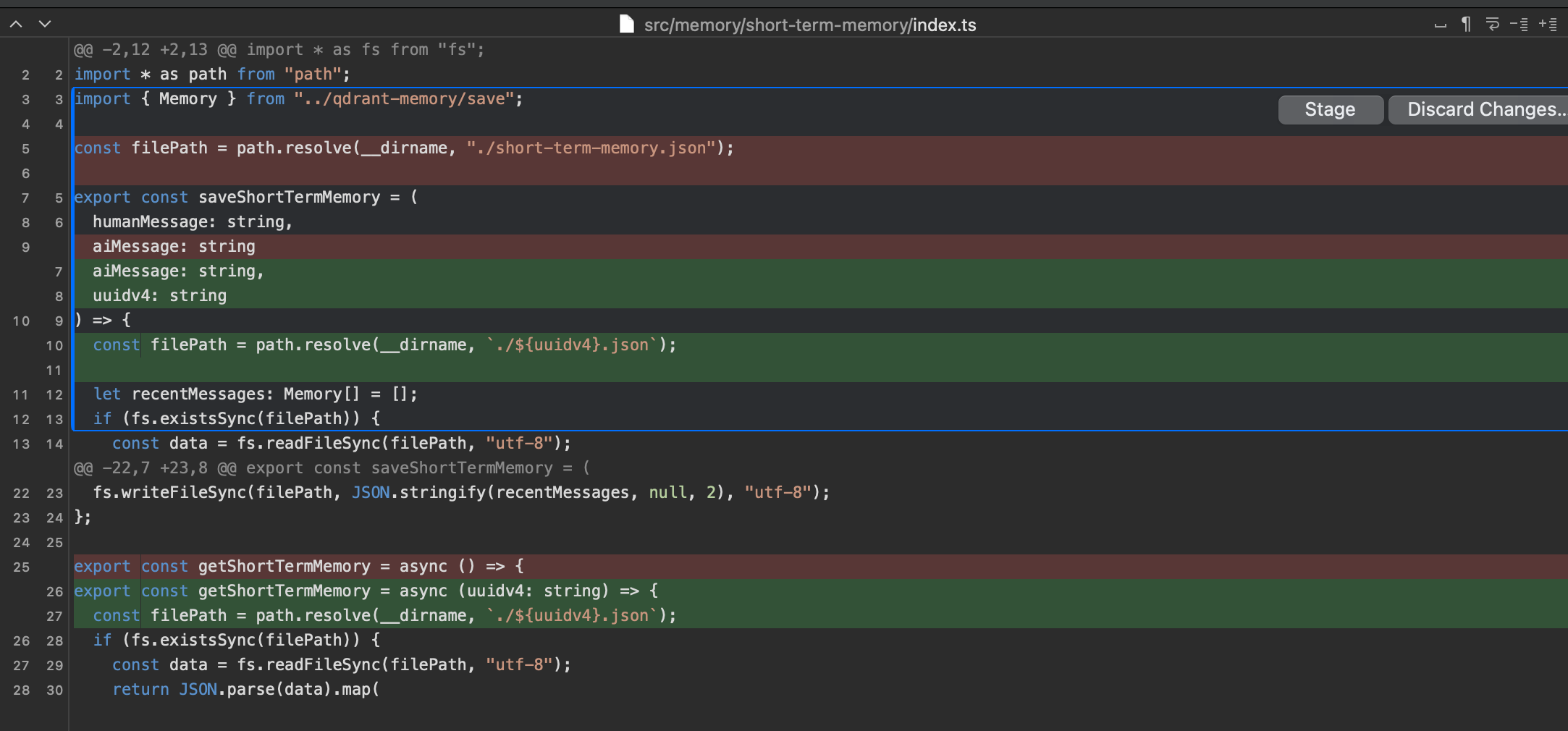
- 重点:长期记忆要怎么做?因为我们的长期记忆使用的是向量数据库,我们要把uuid加入到metadata里,方便存和取的时候有明显的索引值。存和取都只需要加上uuidv4的参数就行了,重点在于create的时候:
 如我们图里显示的一样,我们要在创建collection的时候,创建payload的index,然后在asRetriever的时候特别注明filter,这样我们就可以根据metadata里的值来筛选对话的记忆了。
如我们图里显示的一样,我们要在创建collection的时候,创建payload的index,然后在asRetriever的时候特别注明filter,这样我们就可以根据metadata里的值来筛选对话的记忆了。
得到的结果也很明显:
LLM改写提问
这个算是Retriever阶段更深入的优化了,因为chat bot面对的是普通用户的长对话,用户会自然而然的通过代词去指代前面的内容,比如:
Human:这个故事的主角是?
AI:森岛帆高和天野阳菜
Human:介绍他们俩的故事在正常的RAG逻辑里,我们会使用“介绍他们俩的故事”去检索向量数据库,但是这里的“他们俩”并没有检索的关键词“森岛帆高”和“天野阳菜”,很难正常检索到需要的资料。
所以,为了提高检索质量,我们要对用户的提问进行改写,使其成为一个独立的问题,包含检索的所有关键词,比如上面的例子我们就可以改成“介绍森岛帆高和天野阳菜的故事”,这样检索的时候就可以获得更相关的文档,从而得到高质量的回答
答案显而易见,我们还是继续用LLM来进行改写
所以,又回到了我们前面提到的,当做 LLM app 遇到问题时,我们通常会尝试加入更多的 LLM 来解决问题。
来看看怎么搞:
import {
ChatPromptTemplate,
MessagesPlaceholder,
} from "@langchain/core/prompts";
export const rephraseTemplate = () =>
ChatPromptTemplate.fromMessages([
[
"system",
"给定以下对话和一个后续问题,请将后续问题重述为一个独立的问题。请注意,重述的问题应该包含足够的信息,使得没有看过对话历史的人也能理解。",
],
new MessagesPlaceholder("history"),
["human", "将以下问题重述为一个独立的问题:\n{question}"],
]);给出一个Prompt,然后确定好LLM要怎么联系上下文,改写我们的提问。
把answer-template的内容也进行修改:
import { ChatPromptTemplate } from "@langchain/core/prompts";
export const createAnswerTemplate = () => {
const chatPrompt = `你是一个熟读了新海诚小说《天气之子》的读者,精通根据作品原文详细解释和回答问题,在回答问题的时候你会引用作品原文。
尽可能详细地回答用户的问题。如果问题与原文中没有相关的内容,你可以根据自己的见解进行回答。如果实在是无法判断用户的问题,你可以回答不知道。
如果用户要求你记住什么事情,你需要答应存储,后续有逻辑可以帮助你记住这些记忆。
以下是原文中跟用户回答相关的内容:
{context}
以下是最近的聊天记录(短期记忆):
{short_term_memory}
以下是从历史中检索到的相关记忆(长期记忆):
{chat_history}
现在,你要基于原文、最近的聊天记录和历史记忆,回答以下问题:
{standalone_question}`;
const prompt = ChatPromptTemplate.fromTemplate(chatPrompt);
return prompt;
};
修改点为:
- question => standalone_question
- 修改主要设定,让AI的回答不要太过于死板
紧接着,为了确保AI严格按照我们的Prompt来执行,我们需要对chatModel进行设定:
import { ChatOpenAI } from "@langchain/openai";
import "dotenv/config";
export const createChatModel = async (temperature?: number) => {
const model = new ChatOpenAI({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
model: process.env.OPENAI_MODEL,
temperature: temperature || 0.7,
verbose: true,
});
return model;
};
将temperature降低,但是只有我们改写提问的Chain用到特定的temperature的LLM,所以我们参数要加可选值,默认值为0.7,让AI可以自由发挥。
最后我们来书写Chain:
import {
RunnableSequence,
RunnablePassthrough,
} from "@langchain/core/runnables";
import { rephraseTemplate } from "../../prompt-template/rephrase-template";
import { createChatModel } from "../../model/openai/chat-model";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { getShortTermMemory } from "../../memory/short-term-memory";
export const getRephraseChain = async (uuidv4: string) => {
const short_memory = await getShortTermMemory(uuidv4);
const model = await createChatModel(0.2);
const rephraseChain = RunnableSequence.from([
(input) => input,
RunnablePassthrough.assign({
history: () => {
return !!short_memory ? short_memory : "暂无历史记录";
},
question: (input) => {
return input;
},
}),
rephraseTemplate(),
model,
new StringOutputParser(),
]);
return rephraseChain;
};
为了避免程序报错,我们要将读取到的短期记忆给判断是否为空,如果没有历史记录,我们要将其特别标注“暂无历史记录”
最后,我们在最后的RAG Chain里,将其一一调用:
const ragChain = RunnableSequence.from([
(input) => ({ question: input.question }), // 将输入映射为对象
RunnablePassthrough.assign({
standalone_question: rephraseChain,
}),
(output) => ({
standalone_question: output.standalone_question,
context: contextRetrieverChain.invoke(output.standalone_question), // 将 standalone_question 传递给 contextRetrieverChain
short_term_memory: shortTermMemoryChain.invoke(
output.standalone_question
),
chat_history: memoryRetrieverChain.invoke(output.standalone_question),
}),
prompt,
model,
new StringOutputParser(),
]);
这里要着重说明,因为我们改写提问的这个操作,对后续的所有链都有影响,所以我做成了把它的调用隔离开来,然后将out统一到另一组副作用里,分别赋值,这样可以确保流程完美,一直保持LCEL开发范式
最后,我们来看一下,从什么记忆都没有,到有对话记录的,然后生成内容的全过程:
import { getLastRagChain } from "./chains/last-rag-chain";
import { saveMemoryToQdrantWithFilter } from "./memory/qdrant-memory/save";
import { saveQdrant } from "./db/saveQdrant";
import { saveShortTermMemory } from "./memory/short-term-memory";
import { ruleBasedResponse } from "./pre-defined-res";
const run = async (uuidv4: string) => {
await saveQdrant();
const ragChain = await getLastRagChain(uuidv4);
const question = "这个故事的主角是?";
// Step 1: 规则引擎优先响应
const ruleResponse = ruleBasedResponse(question);
if (ruleResponse) {
console.log("规则引擎回答:", ruleResponse);
return; // 如果匹配规则,直接返回答案
}
// Step 2: 调用 RAG 模型
const res = await ragChain.invoke({
question,
});
console.log(res);
saveShortTermMemory(question, res, uuidv4);
await saveMemoryToQdrantWithFilter(
{
humanMessage: question,
aiMessage: res,
},
uuidv4
);
};
// 从前端传过来的uuid字符串,现在先模拟一下
run("9b1deb4d-3b7d-4bad-9bdd-2b0d7b3dcb6f");
让我们调用一下src/index.ts
在第一次调用之后,我们运行了一组对话,其聊天记录为:

接下来,再次提问:
const question = "介绍他们俩的故事";好,让我们来看看流程:
- 第一步:改写问题
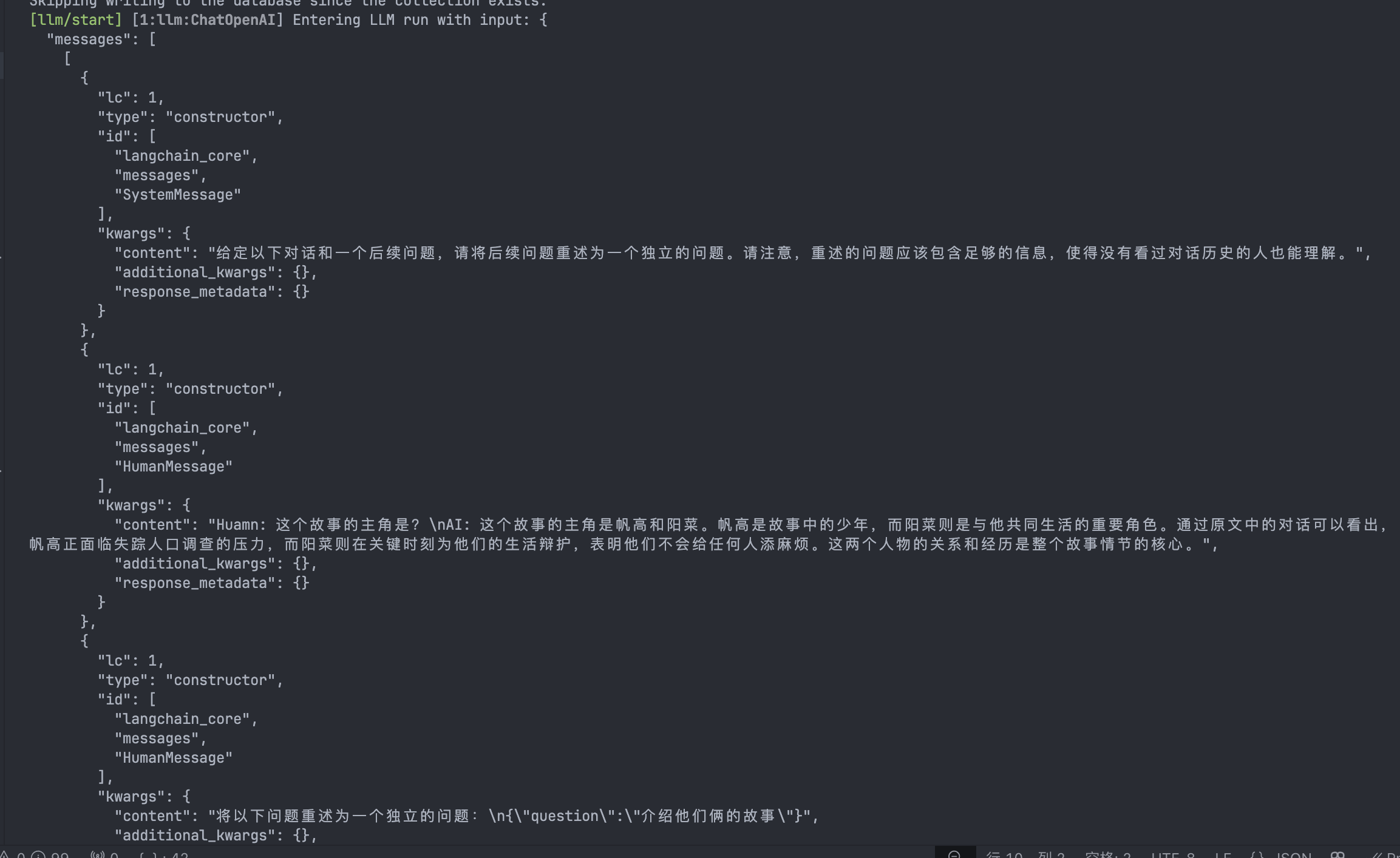
我们可以看到,第一个LLM开始处理我们的改写Chain,得到的结果是:
- 开始让context的Chain来生成三个类似的问题:
- 根据问题找到的向量数据库里有关联的内容,然后压缩成一段简介:

- 把记忆加入,加入问题,再加入context,进行回答:

- 判断这次对话是否需要存入记忆:
- 生成摘要,存入向量数据库:

最后,对话也成功地写入了数据库中:

这个流程我们可以用一个导图来形容: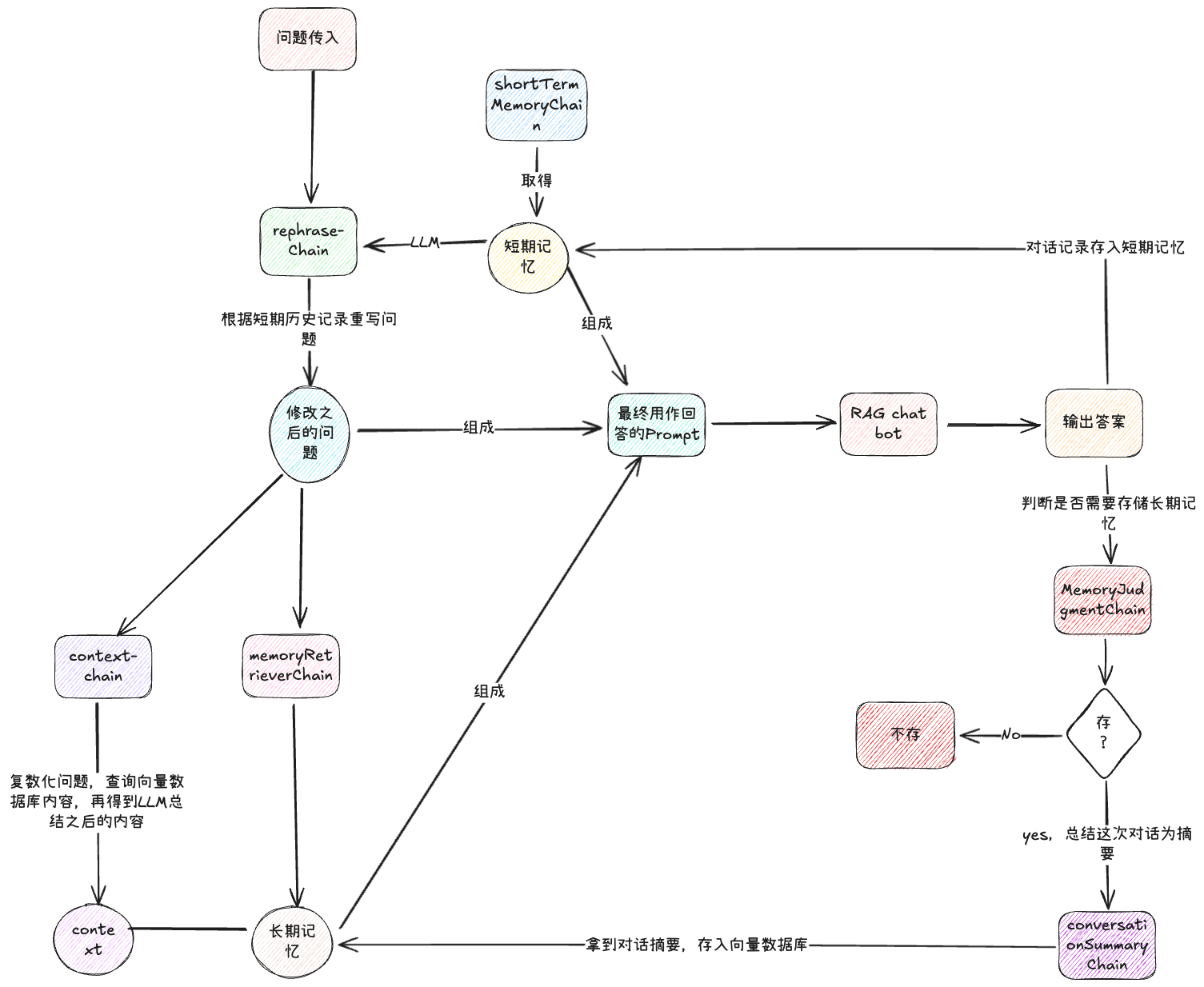
部署为API,并且尝试流式输出
我们使用Express来部署API,方便快捷。
先安装express和需要的依赖,以及他们的@types
npm install --save-dev @types/express @types/body-parser @types/corsnpm i express cors body-parser然后我们在index.ts的文件同级新建一个server.ts,用来暴露我们的接口
src/server.ts
import express, { Request, Response } from "express";
import bodyParser from "body-parser";
import cors from "cors";
import { runRAG } from "./index";
const app = express();
const port = 3000;
// 中间件
app.use(bodyParser.json());
app.use(cors());
app.post("/api/run-rag", async (req: Request, res: Response) => {
const { uuidv4, question } = req.body;
if (!uuidv4 || !question) {
res
.status(400)
.json({ error: "Missing uuidv4 or question in request body." });
return;
}
// 设置响应头,保持流式连接
res.setHeader("Content-Type", "text/plain");
res.setHeader("Transfer-Encoding", "chunked");
res.flushHeaders();
try {
await runRAG(
uuidv4,
question,
(chunk: string) => {
// 回调:每次有新数据时写入响应
res.write(chunk);
},
() => {
// 回调:流完成时关闭连接
res.end();
},
(error: Error) => {
// 回调:发生错误时记录错误并关闭连接
console.error("Error in RAG:", error);
res.write(`Error: ${error.message}`);
res.end();
}
);
} catch (error) {
console.error("Error initializing RAG:", error);
res.status(500).end("Internal server error.");
}
});
app.listen(port, () => {
console.log(`Server is running on http://localhost:${port}`);
});
同理,我们需要把运行方法暴露出来,并且修改一下我们之前的测试代码:
src/index.ts
import { getLastRagChain } from "./chains/last-rag-chain";
import { saveMemoryToQdrantWithFilter } from "./memory/qdrant-memory/save";
import { saveQdrant } from "./db/saveQdrant";
import { saveShortTermMemory } from "./memory/short-term-memory";
import { ruleBasedResponse } from "./pre-defined-res";
export const runRAG = async (
uuidv4: string,
question: string,
onData: (chunk: string) => void,
onComplete: () => void,
onError: (error: Error) => void
) => {
try {
await saveQdrant();
const ragChain = await getLastRagChain(uuidv4);
// Step 1: 规则引擎优先响应
const ruleResponse = ruleBasedResponse(question);
if (ruleResponse) {
onData(`规则引擎回答:${ruleResponse}\n`);
onComplete();
return;
}
// Step 2: 调用 RAG 模型
const streamResult = await ragChain.stream({ question });
let res = "";
// 流式处理每个数据块
for await (const chunk of streamResult) {
res += chunk;
onData(chunk); // 逐块传递数据
}
// 完成流式传递
onComplete();
// 保存记忆
await saveShortTermMemory(question, res, uuidv4);
await saveMemoryToQdrantWithFilter(
{
humanMessage: question,
aiMessage: res,
},
uuidv4
);
} catch (error) {
if (error instanceof Error) {
// 明确将 error 类型传递给 onError
onError(error);
} else {
// 如果 error 不是 Error 类型,创建一个新的 Error 实例
onError(new Error(String(error)));
}
}
};
我们修改package.json。使用npm 的方法启动项目:
"scripts": {
"start:server": "cd src && ts-node server.ts"
},写一个测试脚本,来试试能否成功运行:
./test.js
const port = 3000;
async function fetchStream() {
const response = await fetch(`http://localhost:${port}/api/run-rag`, {
method: "POST",
headers: {
"content-type": "application/json",
},
body: JSON.stringify({
question: "我的名字是?",
uuidv4: "test",
}),
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
console.log(decoder.decode(value));
}
console.log("Stream has ended");
}
fetchStream();
效果如图:
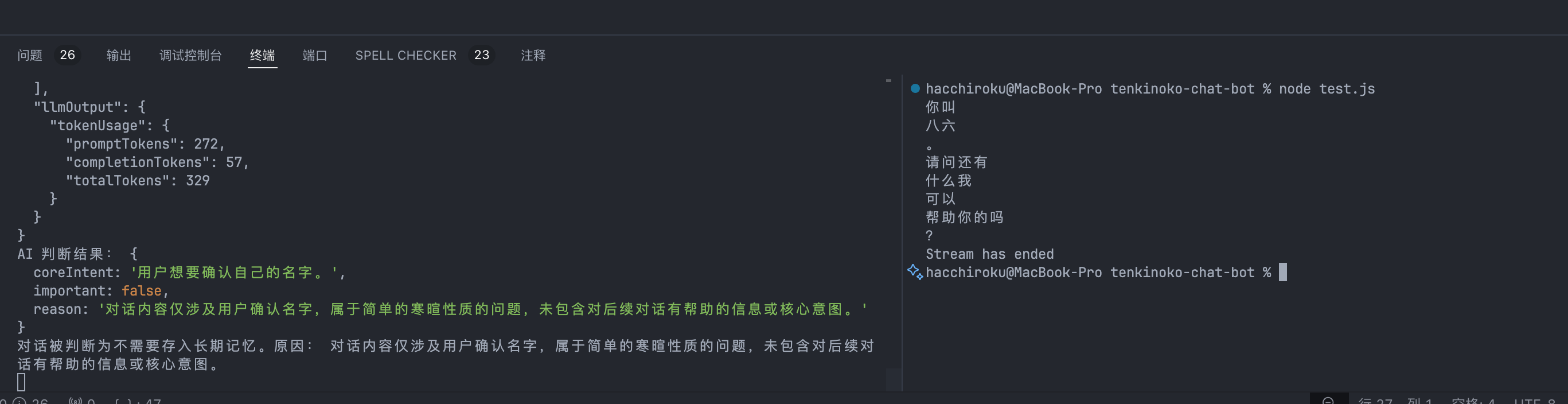
这样我们就算完成了,可以给其他的业务提供服务的RAG Bot可以部署上线啦!
总结
这样一来,我们经历了这么久的学习,联合了前面所有的知识点,从0开始部署了一个Rag Chain。
学习了大量的Retriever,Memory等策略,在实际工程中,其实这些东西不一定都是需要的,要取决于业务的情况。比如说,给内部文档做简单的查询bot,就如同我在Calendar里提到的公司内部查询bot,就不需要聊天记录,也不需要改写提问之类的需求,每次提问都是独立的。
如果做的是复杂的Bot,就需要衡量一下成本和效果的权衡,加入完整的history就意味着对LLM的上下文压力就会大起来,Token也会变多,如果我们不需求质量,就可以保留少量记录,主要辅助用户进行问题重写。
另外值得一说的是,Langchain内部工具的Prompt都是英文,LLM本身也有很好的跨语言能力,但是不代表我们就不需要自己写好中文的Prompt,因为我们需要更好的语义环境的效果
前期不要过早地陷入优化陷阱,因为这个我对这篇文章真是改了又改,先做,再看效果,再来优化!
本文这次的项目源代码:地址
可以参考上述地址的源代码进行学习??