重构
思考了一下,将特定的功能交给不同层级的文件夹来管理,每一个ts文件都名为index.ts,这样做就是结合了模块化设计,并使用了文件夹和分层结构来组织代码。这是一种标准的项目结构:
重新整理了demo的结构之后,我们开始接下来的正题:
VectorStoreRetrieverMemory的一些延伸思考
如果只是使用VectorStoreRetrieverMemory会有一些潜在的问题。我这里经过个人的一些思考,有一些优化,当然,因为LCEL的便捷性,我们有很多方法可以尝试优化这个Memory。
向量数据库的局限性
- 因为依赖的是嵌入模型的语义能力,对于非语义相关性的问题(比如时间线相关的,我上次、我之前、我几个小时前)这一类问题的表现能力会比较弱
短期记忆的不足
- 没有单独管理的短期记忆,有可能会导致回答的不连贯
那我们要怎么处理这个问题呢?
我们可以配合多个LLM来完成很多优化,我这边方便演示都用同一个LLM了,实际项目里,我们可以把任务交给本地大模型来使用,比如Ollama
一切的前提:修改Prompt:
import { ChatPromptTemplate } from "@langchain/core/prompts";
export const createAnswerTemplate = () => {
const chatPrompt = `你是一个熟读了新海诚小说《天气之子》的读者,精通根据作品原文详细解释和回答问题,在回答问题的时候你会引用作品原文。
尽可能详细地回答用户的问题。如果问题与原文中没有相关性,你可以根据情况回答。如果实在是无法判断用户的问题,你可以回答不知道。
以下是原文中跟用户回答相关的内容:
{context}
以下是最近的聊天记录(短期记忆):
{short_term_memory}
以下是从历史中检索到的相关记忆(长期记忆):
{chat_history}
现在,你要基于原文、最近的聊天记录和历史记忆,回答以下问题:
{question}`;
const prompt = ChatPromptTemplate.fromTemplate(chatPrompt);
return prompt;
};
根据修改了之后的prompt,我们需要处理两段Memory:
- 短期记忆:
short_term_memory - 长期记忆:
chat_history
让我们开始吧!
第一步:添加短期记忆
短期记忆对于当前对话的连续性和连贯性非常的重要
我们来新建一个short-term-memory/index.ts
import * as fs from "fs";
import * as path from "path";
import { Memory } from "../qdrant-memory/save";
const filePath = path.resolve(__dirname, "./short-term-memory.json");
export const saveShortTermMemory = (
humanMessage: string,
aiMessage: string
) => {
let recentMessages: Memory[] = [];
if (fs.existsSync(filePath)) {
const data = fs.readFileSync(filePath, "utf-8");
recentMessages = JSON.parse(data);
}
// 保留最近5条对话
if (recentMessages.length > 5) {
recentMessages.shift();
}
recentMessages.push({ humanMessage, aiMessage });
fs.writeFileSync(filePath, JSON.stringify(recentMessages, null, 2), "utf-8");
};
export const getShortTermMemory = async () => {
if (fs.existsSync(filePath)) {
const data = fs.readFileSync(filePath, "utf-8");
return JSON.parse(data).map(
(item: Memory) => `Huamn: ${item.humanMessage}\nAI: ${item.aiMessage}`
);
}
return "";
};我们这里使用的是本地JSON写入来存储,这只是为了演示方便做的临时措施,在实际项目里,我的推荐是使用Redis来进行短期数据的管理,会好很多
在每次对话结束的时候,添加存储:
import { saveShortTermMemory } from "./memory/short-term-memory";
...
saveShortTermMemory(question, res);如此一来,我们在最后的lastRagChain里,就可以直接调用我们定义的Chain
short-term-memory-retriever-chain/index.ts
import { RunnableSequence } from "@langchain/core/runnables";
import { getShortTermMemory } from "../../../src/memory/short-term-memory";
export const getShortTermMemoryRetrieverChain = async () => {
return RunnableSequence.from([
(input) => input,
async () => {
const shortMemory = await getShortTermMemory();
return shortMemory;
},
]);
};
last-rag-chain/index.ts
import { getShortTermMemoryRetrieverChain } from "../short-term-memory-retriever-chain";
...
const shortTermMemory = await getShortTermMemoryRetrieverChain();
...
const ragChain = RunnableSequence.from([
{
context: contextRetrieverChain,
// 这里就是插入短期记忆的地方了
short_term_memory: shortTermMemory,
chat_history: memoryRetrieverChain,
question: (input) => input.question,
},
prompt,
model,
new StringOutputParser(),
]);我们尝试运行一下,在运行的时候,把Qdrant的存储逻辑暂时注释掉,因为我们要测试一下短期记忆是否成功加入了prompt:
运行了第一次: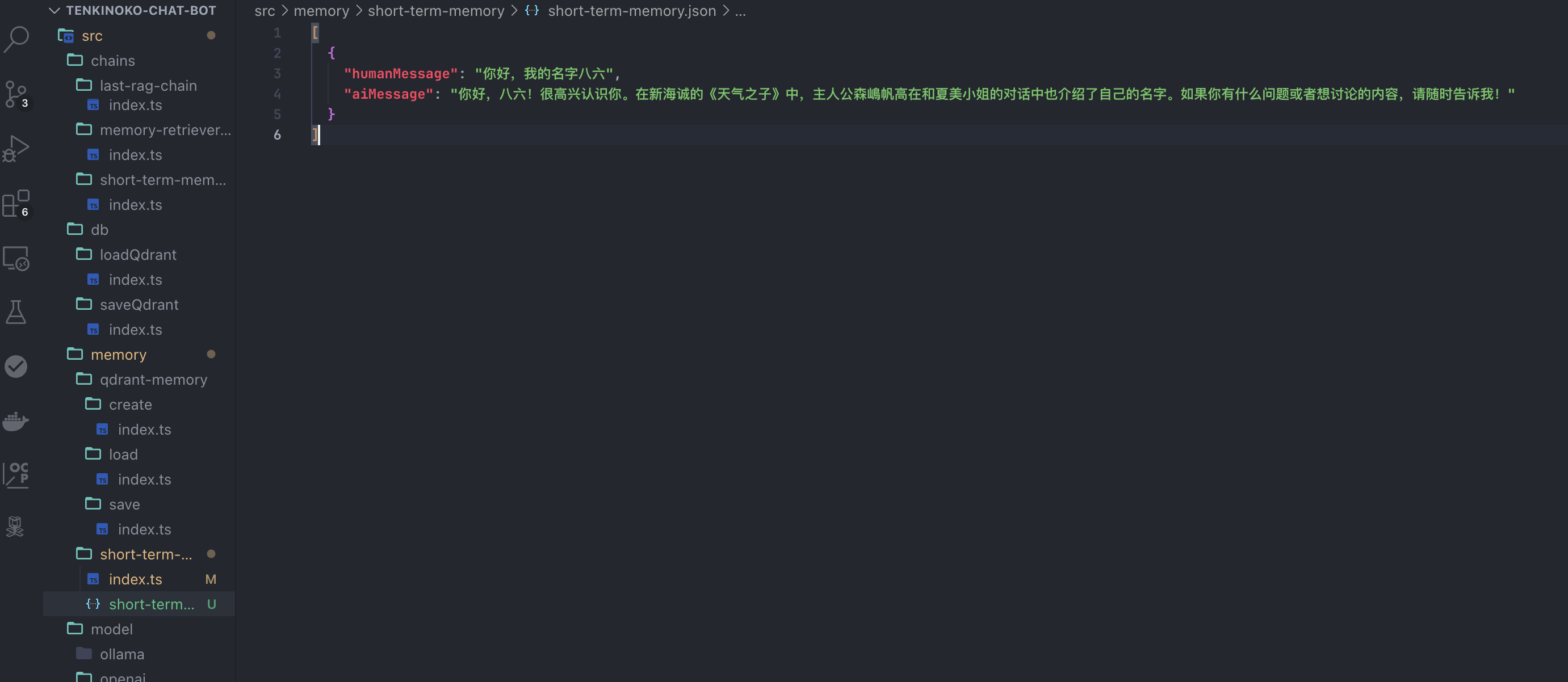
我们来提问第二次,看看它知不知道我是谁: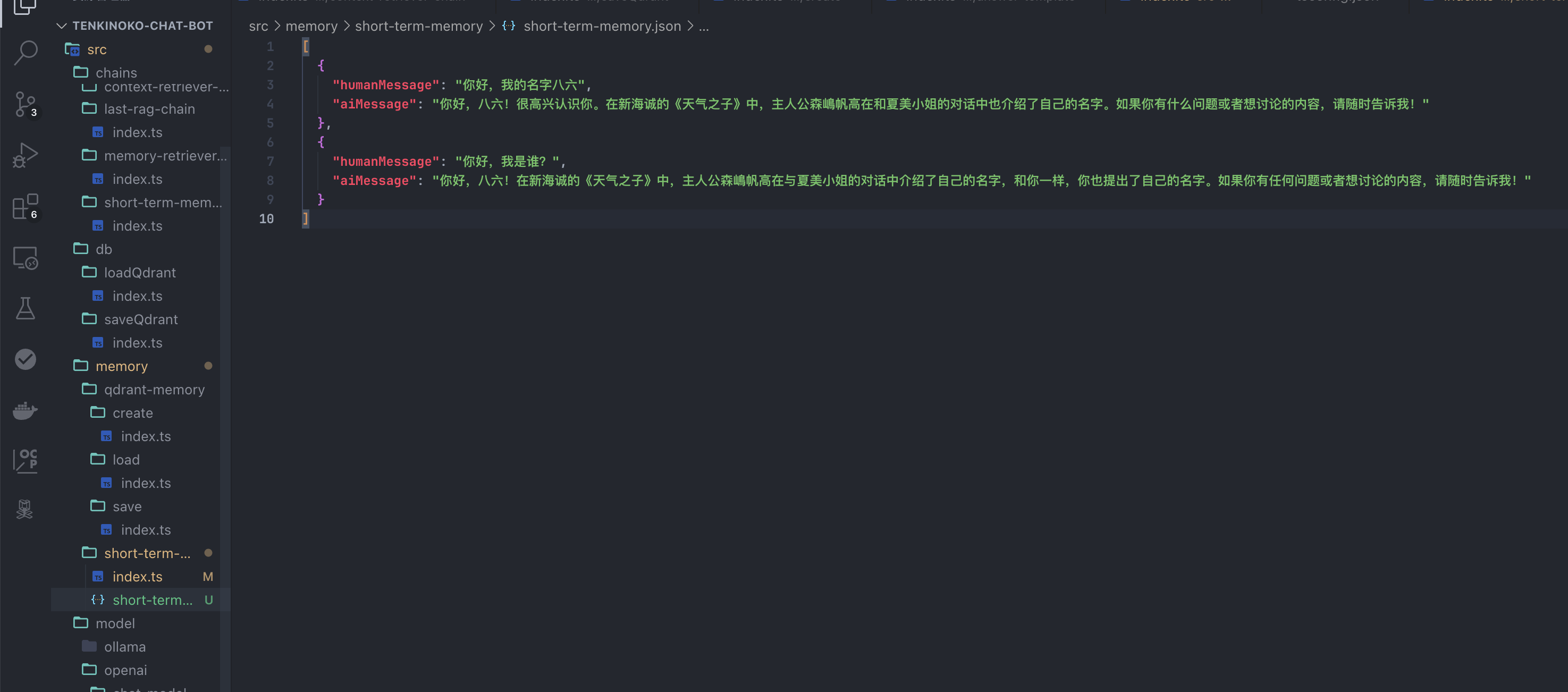
很顺利的,第二条消息也成功的回复了我的名字,并且写入了短期记忆里。
第二步:长期记忆
如何判断是不是应该把这次对话加入Qdrant数据库实现长期记忆?
那我加入LLM不就是了!
其实最后我们的对答bot的性能,都可以通过LLM来实现无限可能。
废话不多说,我们来实装吧!
首先我们需要一个新的Prompt来要求LLM根据我们的规定返回我们需要的结果,我们让AI来判断是不是该记住!
prompt-template/memory-judgment-template/index.ts
import { ChatPromptTemplate } from "@langchain/core/prompts";
export const createMemoryJudgmentTemplate = () => {
const judgmentPrompt = `你是一个负责分析对话内容的重要性和价值的助手。
请根据以下对话判断是否需要存储到长期记忆中。存储的标准如下:
1. 如果对话包含对后续对话有帮助的信息,或包含关键的核心意图,请存入长期记忆。
2. 如果对话是常见问题、无关的信息,或仅仅是寒暄性质的对话,请不要存入长期记忆。
3. 请重点根据Human后面的内容进行判断,用户如果提到了个人信息这种需要记住的信息,也请存入长期记忆。
对话内容如下:
Human: {human_message}
AI: {ai_message}
请完成以下任务:
1. 提取用户的核心意图。
2. 判断这次对话是否需要存储到长期记忆,并说明原因。
请使用以下格式输出:
核心意图:<这里写核心意图>
是否需要存入长期记忆:<是/否>
原因:<这里写存储或不存储的原因>`;
return ChatPromptTemplate.fromTemplate(judgmentPrompt);
};
紧接着,我们需要新建一个Chain,独立于最后需要集合到last-rag-chain的chains,它的作用只是提取出LLM基于这次对话判断的结果:
chains/memory-judgment-chain/index.ts
import { createMemoryJudgmentTemplate } from "../../prompt-template/memory-judgment-template";
import { RunnableSequence } from "@langchain/core/runnables";
import { createChatModel } from "../../model/openai/chat-model";
import { StringOutputParser } from "@langchain/core/output_parsers";
export const getMemoryJudgmentChain = async () => {
const model = await createChatModel();
const prompt = createMemoryJudgmentTemplate();
const judgmentChain = RunnableSequence.from([
{
human_message: (input) => input.humanMessage,
ai_message: (input) => input.aiMessage,
},
prompt,
model,
new StringOutputParser(),
]);
return judgmentChain;
};
关键点就是save的部分了,要如何存,要如何决定存不存?
在此之前我们先弄两个helper方法,分别用来:
parseJudgmentResult:处理LLM给出的结果,将其转为一些变量,方便调用isImportantMessage:直接在调用LLM之前,筛选掉一些很明显不需要存入记忆的内容(这个的标准不好说,可以根据需要自己界定范围)
helper/index.ts
export interface JudgmentResult {
coreIntent: string;
important: boolean;
reason: string;
}
export const parseJudgmentResult = (result: string): JudgmentResult => {
const intentLine = result.match(/核心意图:(.*)/)?.[1]?.trim();
const storageLine = result.match(/是否需要存入长期记忆:(.*)/)?.[1]?.trim();
const reasonLine = result.match(/原因:(.*)/)?.[1]?.trim();
return {
coreIntent: intentLine || "",
important: storageLine === "是", // 判断是否存储
reason: reasonLine || "",
};
};
export const isImportantMessage = (humanMessage: string) => {
// 如果用户输入是打招呼或常见问题,直接判断为不重要
const greetingKeywords = ["你好", "嗨", "您好", "早上好", "晚上好"];
const importanceKeywords = [
"重要",
"关键",
"核心",
"记住",
"我叫",
"我是",
"我要",
];
if (
greetingKeywords.some((kw) => humanMessage.includes(kw)) &&
!importanceKeywords.some((importanceKey) =>
humanMessage.includes(importanceKey)
)
) {
return false; // 直接排除寒暄性质的对话,除非用户提到了个人信息或者特别说明了很重要
}
// 如果有其他排除规则,也可以在这里添加
return true; // 否则认为是重要的
};
然后我们重新设计了save的方法:
/memory/qdrant-memory/save/index.ts
import { parseJudgmentResult, isImportantMessage } from "../../../helper";
import { getMemoryJudgmentChain } from "../../../chains/memory-judgment-chain";
import { createMemoryFromQdrant } from "../create";
export interface Memory {
humanMessage: string;
aiMessage: string;
}
export const saveMemoryToQdrantWithFilter = async (messages: Memory) => {
const judgmentChain = await getMemoryJudgmentChain();
if (!isImportantMessage(messages.humanMessage)) {
console.log(
"对话被判断为不需要存入长期记忆。原因:寒暄或常见问题,已被提前筛除。"
);
return;
} else {
// 调用判断链
const judgmentResult = await judgmentChain.invoke({
humanMessage: messages.humanMessage,
aiMessage: messages.aiMessage,
});
const result = parseJudgmentResult(judgmentResult);
console.log("AI 判断结果:", result);
// 判断是否需要存入长期记忆
if (result.important) {
const memory = await createMemoryFromQdrant();
await memory.saveContext(
{ input: messages.humanMessage },
{ output: messages.aiMessage }
);
console.log("重要对话已存入长期记忆。原因:", result.reason);
} else {
console.log("对话被判断为不需要存入长期记忆。原因:", result.reason);
}
}
};
看代码就知道了,我们先根据预设的一些直接不需要存入的内容,直接确认不存。节省Token。如果判断之后,根据AI的判断来决定是否存入:
来点例子:
你好,我是八六
你好
这样,我们就实现了一个长期记忆存入的初步判断逻辑。
理论上,只要完成了前两步就已经足够对记忆有一个好的处理了,下面的第三步和第五个可以视情况是否添加,第四步可以着重做一下
第三步:根据问题复杂度调整检索结果数量
这一步可以做也可以不做,如果业务复杂了,就可以做这一步,在例子中我并没有这样做,因为暂时也没有必要,但是还是需要提一下
我们再加一个Prompt Template,来专门让LLM处理需要几条检索结果,来处理对应复杂度的问题:
import { ChatPromptTemplate } from "@langchain/core/prompts";
export const createComplexityAnalysisPrompt = () => {
const prompt = `你是一个负责分析问题复杂度的助手。
请根据用户的问题,判断问题的复杂度和所需的上下文检索条目数量。
用户的问题如下:
{question}
输出格式:
问题类型:<简单/复杂/模糊>
检索条目数量:<数量>`;
return ChatPromptTemplate.fromTemplate(prompt);
};我们就可以把这个Prompt加到
const memory = new VectorStoreRetrieverMemory({
vectorStoreRetriever: vectorStore.asRetriever(1),
memoryKey: "ten_ki_no_ko_history",
});替换掉这个1,另外,得到的结果也需要更正一下。不难,这里就不赘述了。
第四步:在存储前生成摘要,减少存储冗余
这一步,我们经常干了,主要目的也是为了节省之后的Memory调用消耗掉的Token。
一样的,添加LLM来处理问题:
先生成Prompt:
prompt-template/conversation-summary-template/index.ts
import { ChatPromptTemplate } from "@langchain/core/prompts";
export const createSummaryPrompt = () => {
const prompt = `你是一个负责生成对话摘要的助手。
请根据以下对话生成简短且概括的摘要,保留对话的核心信息。
对话内容如下:
Human: {human_message}
AI: {ai_message}
输出格式:
对话摘要:<这里写摘要>`;
return ChatPromptTemplate.fromTemplate(prompt);
};然后按照我设计的结构,下一步是新建chain,专门处理Summary的内容:
chains/conversation-summary-chain/index.ts
import { createSummaryPrompt } from "../../prompt-template/conversation-summary-template";
import { RunnableSequence } from "@langchain/core/runnables";
import { createChatModel } from "../../model/openai/chat-model";
import { StringOutputParser } from "@langchain/core/output_parsers";
export const getConversationSummaryChain = async () => {
const model = await createChatModel();
const prompt = createSummaryPrompt();
const conversationSummaryChain = RunnableSequence.from([
{
human_message: (input) => input.humanMessage,
ai_message: (input) => input.aiMessage,
},
prompt,
model,
new StringOutputParser(),
]);
return conversationSummaryChain;
};
修改save的逻辑:
// 判断是否需要存入长期记忆
if (result.important) {
const summaryChain = await getConversationSummaryChain();
const summaryRes = await summaryChain.invoke({
humanMessage: messages.humanMessage,
aiMessage: messages.aiMessage,
});
const summary = summaryRes.match(/对话摘要:(.*)/)?.[1]?.trim();
const memory = await createMemoryFromQdrant();
await memory.saveContext(
{ summary: summary },
{ aiMessage: messages.aiMessage }
);
console.log("重要对话已存入长期记忆。原因:", result.reason);
} else {
console.log("对话被判断为不需要存入长期记忆。原因:", result.reason);
}
}我们来看看效果:
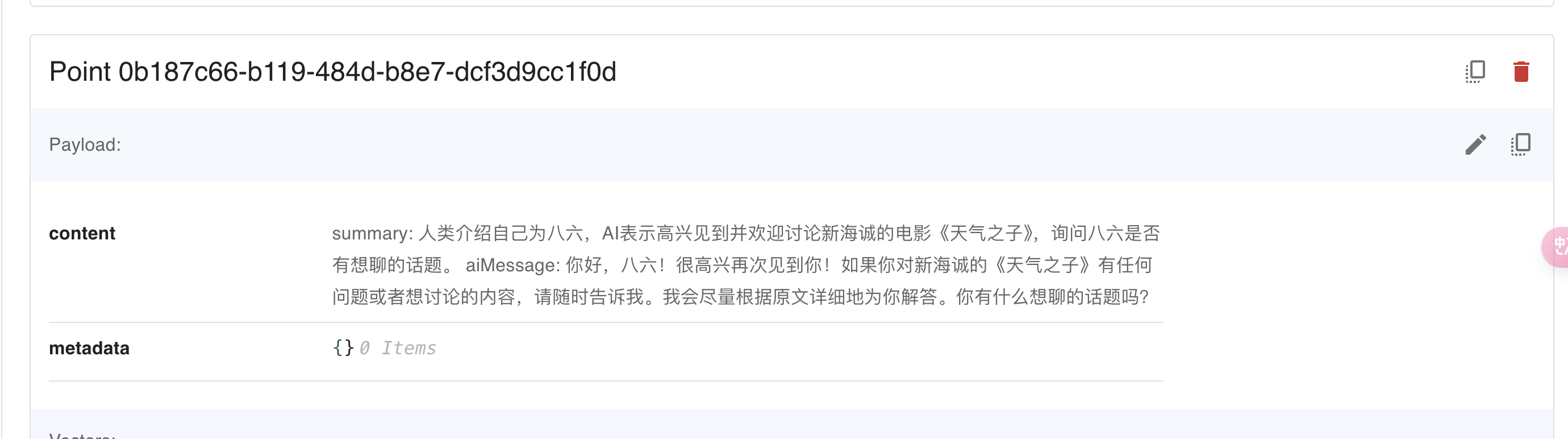
这样我们就很好的处理了摘要,提高了精准性和匹配度,在有一些对话内容很长的场合还可以节省Token
第五步:规则引擎:快速响应简单或固定问题
并不是任何问题都需要调用LLM来回答,就像我之前开发QQ Bot一样,我们只对特定的内容做出回复,速度很快。在chat Bot里面也是一样可以的。
将常见问题和固定回答定义为一个规则列表、
随后我们实现规则引擎、
作用就是根据用户的输入,来匹配规则
/pre-defined-res/index.ts
const predefinedRules = [
{
pattern: /你好|您好|嗨/i,
response: "你好!很高兴见到你,有什么我可以帮助的吗?",
},
{
pattern: /《天气之子》是关于什么的/i,
response: "《天气之子》是一部由新海诚执导的电影,讲述了少年帆高和拥有天气操控能力的少女阳菜之间的故事。",
},
{
pattern: /导演是谁/i,
response: "《天气之子》的导演是新海诚。",
},
];
export const ruleBasedResponse = (question) => {
for (const rule of predefinedRules) {
if (rule.pattern.test(question)) {
return rule.response;
}
}
return null; // 如果没有匹配规则,返回 null
};整合到主流程:
import { getLastRagChain } from "./chains/last-rag-chain";
import { saveMemoryToQdrantWithFilter } from "./memory/qdrant-memory/save";
import { saveQdrant } from "./db/saveQdrant";
import { saveShortTermMemory } from "./memory/short-term-memory";
import { ruleBasedResponse } from "./pre-defined-res";
const run = async () => {
await saveQdrant();
const ragChain = await getLastRagChain();
const question = "《天气之子》是关于什么的?";
// Step 1: 规则引擎优先响应
const ruleResponse = ruleBasedResponse(question);
if (ruleResponse) {
console.log("规则引擎回答:", ruleResponse);
return; // 如果匹配规则,直接返回答案
}
// Step 2: 调用 RAG 模型
const res = await ragChain.invoke({
question,
});
console.log(res);
saveShortTermMemory(question, res);
await saveMemoryToQdrantWithFilter({
humanMessage: question,
aiMessage: res,
});
};
run();
最后的结果就是:

这样也可以提高反应速度,不需要调用Token来处理一些很简单的问答。
总结
这就是Memory的叠加使用,我思考了很久要怎么做到最好,但是当需求越来越涌现的时候,我意识到,LLM APP的可行性和可玩性实在是太多了,所以我干脆就只是抛砖引玉,在特定的环境下,我们能做的事情也就不一样了,希望这篇文章能够帮助你有更多的灵感来处理独属于你的IDEA而诞生的LLM APP,将它做到更好。
这一节的仓库分支链接