前面的所有内容都跟集齐七龙珠似的,我们终于凑齐了召唤RAG Bot的所有碎片:
- 使用了
Prompt Template构建复用的Prompt模板 - 根据私域数据的类型来对数据进行分块(splitter)
- 构建私域数据的Vector Database
- 根据相似性去查询Vector Database中最相关的上下文
如今,我们可算是可以连起来了,把所有的知识聚集到一起,来做一个RAG Bot的小demo。本章节,我们选择一本小说作为我们的私域数据集,做一个可以根据用户的问题查找原著中相关性最高的片段,然后基于该片段进行回答的Bot。
我选择的小说是新海诚导演的《天气之子》,也是我最喜欢的动画电影的原作,文章长度不算长,情节也挺丰富,可以提一些有依据性的问题。
先看最后结果:
好,让我们开始吧。
加载和切割原始数据
我们收集天气之子的原文数据,我用到的是最基本的txt文本格式
因为版权原因,数据库仅供本地测试和学习使用,如果要对外服务需要得到版权相关的授权才可以。提供大模型服务的时候,要随时注意版权问题。
首先,我们用Langchain的工具TextLoader来加载txt的数据。
const loader = new TextLoader("../data/天气之子.txt");
const docs = await loader.load();
加载出来的数据结构,显然是非常巨大的,明显超过了大部分LLM的上下文限制,所以我们需要对原文进行切分
const splitter = new RecursiveCharacterTextSplitter({
chunkSize:500,
chunkOverlap:100
});
const splitDocs = await splitter.splitDocuments(docs);
切分之后的数据格式如上,可以看到pageContent就是切分之后的文本结果,在metadata里面存储了关于切分的部分信息,方便后续的处理。
我们使用的是RecursiveCharacterTextSplitter,这个切分工具复习一下,作用就是根据内置的一些字符对原始文本进行递归的切分,保持相关的文本片段相邻,保证切分结果内部的语义相关。
在后续我们可以根据最终质量来决定要不要使用别的切分工具,或者,调整切分的参数,我们这里先设置的是500的size和100的重复lap。
从上面的图我们可以基本上看到,每一段基本上都在讲一段独立的故事,块之间也有一定的重合来让LLM能够理解上下文。
构建Vector store和Retriever
有了切割之后的数据,我们就要往数据库里面丢数据了,要把每个数据块都构建成Vector,然后存入Vector store里,我们使用之前提到的OpenAI的text-embedding-3-small模型来Embedding。
我们使用Langchain的OpenAIEmbeddings类来new一个Embedding模型:
const embeddings = new OpenAIEmbeddings({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
model: process.env.OPENAI_EMBEDDING_MODEL,
});然后我们就需要创建一个存储Embedding Vector的Vector store,也就是向量数据库,我们可以采用很多种线上数据库,或者自己的数据库。因为每次embedding都会花费一定的价格,所以最好是把embedding的结果永远存储在数据库里,这样可以方便在服务里使用,可以参考前面我提到过的qdrant,也可以用faiss之类的其他的数据库,但是要记住我提到过得,每个数据库的算法可能不一样,要选择最适合你需求的。
await QdrantVectorStore.fromDocuments(splitDocs, embeddings, {
client: client,
collectionName: "ten_ki_no_ko",
});这一部分可能会运行蛮久的,因为需要对数据库里的每一个数据都调用embedding模型,再存储在内存的store里面。
来看看我们的API服务商的记录token:
然后我们就可以从VectorStore里面获取到一个Retriever实例:
- 先获取数据库:
import { QdrantVectorStore } from "@langchain/qdrant";
import { OpenAIEmbeddings } from "@langchain/openai";
import { QdrantClient } from "@qdrant/js-client-rest";
import "dotenv/config";
export const loadQdrant = async () => {
const client = new QdrantClient({ url: process.env.QDRANT_API_URL });
const embeddings = new OpenAIEmbeddings({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
model: process.env.OPENAI_EMBEDDING_MODEL,
});
// 加载 Qdrant 中已存储的集合
const vectorStore = await QdrantVectorStore.fromExistingCollection(
embeddings,
{
client: client,
collectionName: "ten_ki_no_ko",
}
);
return vectorStore;
};
使用Retriever优化策略获得一个最终优化的Retriever实例:
const vectorStore = await loadQdrant(); // 这里是模型的创建 const model = await createModel(); // 这里是多次查询的检索器,把用户的输入改成多个不同的写法 const multiQueryRetriever = MultiQueryRetriever.fromLLM({ llm: model, retriever: vectorStore.asRetriever(3), queryCount: 3, }); // 专门提取核心内容的Compressor const compressor = LLMChainExtractor.fromLLM(model); // 这里是上下文压缩检索器,把用户的输入压缩成一个问题 const compressionRetriever = new ContextualCompressionRetriever({ baseRetriever: multiQueryRetriever, baseCompressor: compressor, });这里产出的内容是这样的:
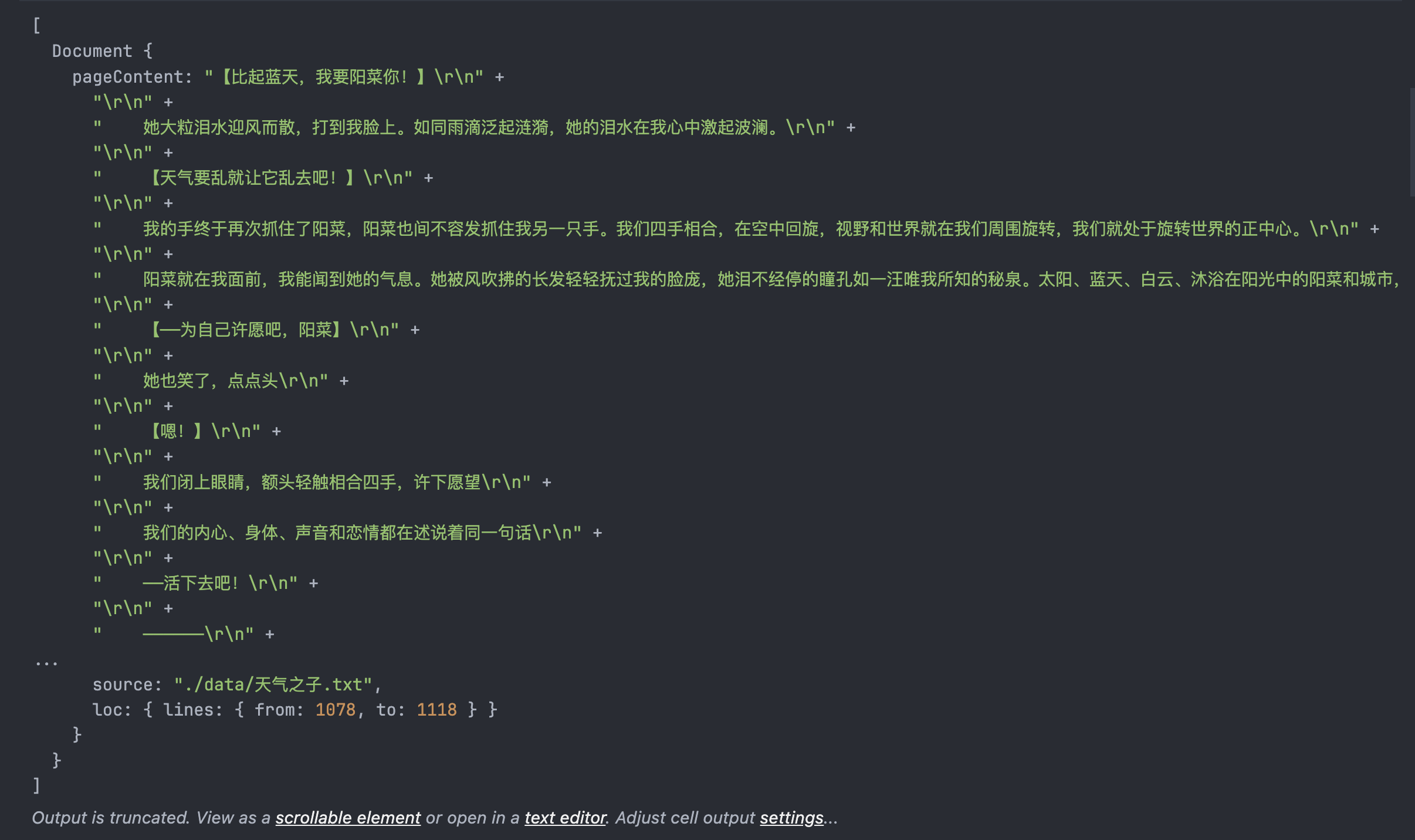
返回值是跟我的问题相关的数据,这种结构并不能直接交给LLM,我们加一下简单的处理函数来处理成文本:
const convertDocsToString = (documents: Document[]): string => {
return documents.map((doc) => doc.pageContent).join("\n");
};这个函数的作用就只是提取出结果里的pageContent,拼接到一起,用提行符分割
有了这些,我们就可以构建一个比较简单的获取数据库里相关的上下文的chain
import { RunnableSequence } from "@langchain/core/runnables";
...
const contextRetrieverChain = RunnableSequence.from([
(input) => input.question,
compressionRetriever,
convertDocsToString,
]);RunnableSequence的作用还没讲过,就是构建一个chain,传入一个数组,把第一个Runnable对象返回的结果自动输入给下一个Runnable对象
在这里,contextRetrieverChain,接受一个input对象作为输入,从里面获取到一个question,就是用户的问题,然后传递给compressionRetriever,通过这里返回的Document对象数组作为参数传递给了convertDocsToString处理为LLM可以读取的纯文本。
来试着调用一下,看一下得出的结果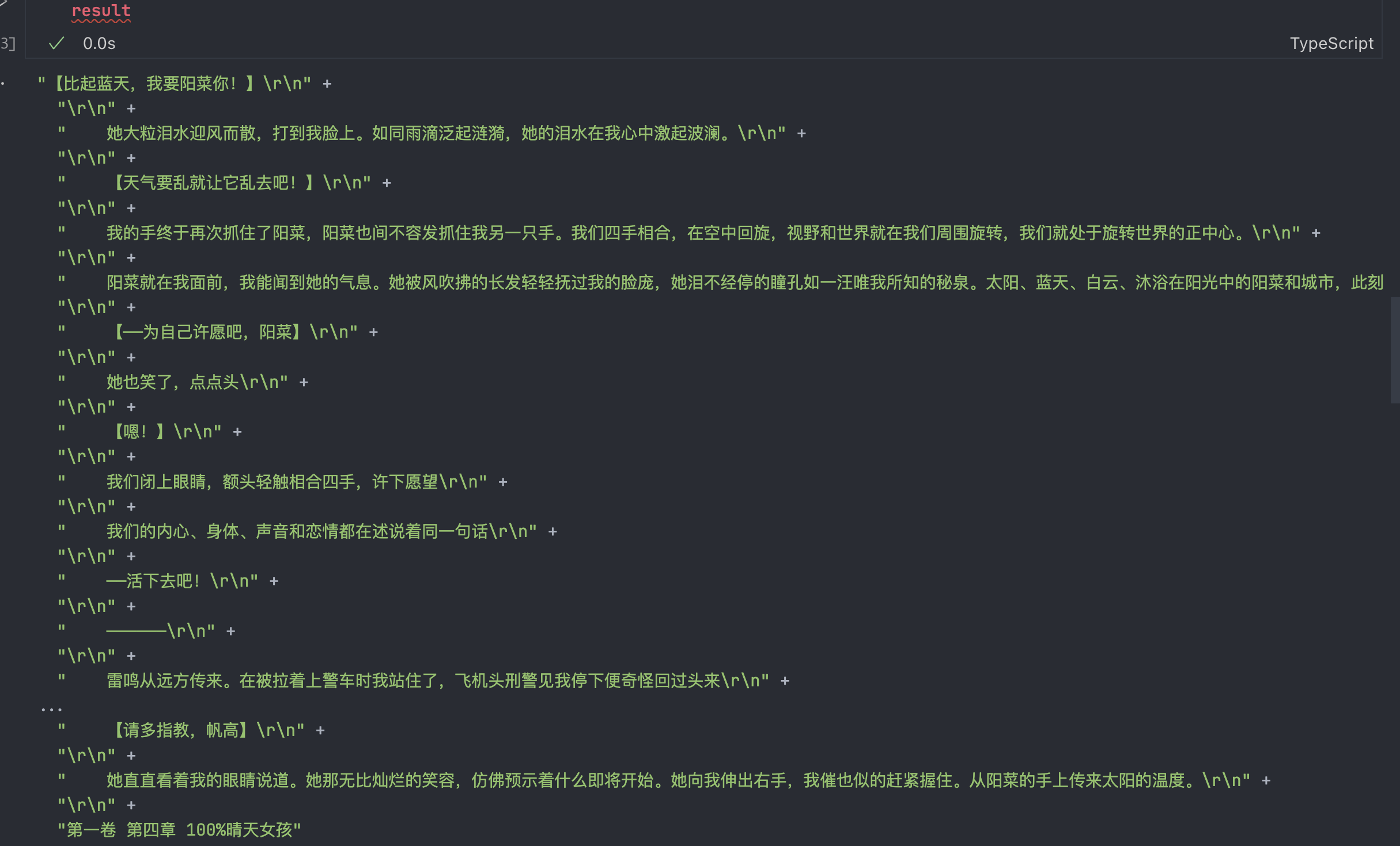
我们可以看到,根据用户的问题,获取到了原文相关性比较高的上下文了,并且还把它处理为了纯文本形式。
构建Template
再然后,我们来构建用户提问的Template,使用ChatPromptTemplate来构建,使用简单的Prompt技巧,在其中定义两个变量,一个是context(相关内容),一个是question(用户问题)
import { ChatPromptTemplate } from "@langchain/core/prompts";
export const createTemplate = () => {
const chatPrompt = `你是一个熟读了新海诚小说《天气之子》的读者,精通根据作品原文详细解释和回答问题,在回答问题的时候你会引用作品原文。
并且在回答的时候仅根据原文来回答,尽可能详细地回答用户的问题,如果原文里没有对应的相关内容,你可以回答“这个问题我不知道”。,
以下是原文中跟用户回答相关的内容
{context}
现在,你要基于原文,回答以下问题:
{question}`;
const prompt = ChatPromptTemplate.fromTemplate(chatPrompt);
return prompt;
};
在运行的时候,我们就可以只把对应的变量传递给Prompt,将Prompt的变量转为真实的值。
在设置Prompt的时候,遵循两个技巧:
- 回答谨遵原文 - 目的是固定LLM的回答只根据原文来
- 如果原文没有相关的内容,就回答“这个问题我不知道” -减少LLM幻想问题
实现完整的Chain
最后,我们把上述所有内容全部连在一起,实现完整的对话Chain:
import { ChatOpenAI } from "@langchain/openai";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { RunnableSequence } from "@langchain/core/runnables";
import { getContextRetrieverChain } from "./getContextRetrieverChain";
import { createTemplate } from "./creatTemplate";
export const getLastRagChain = async () => {
const model = new ChatOpenAI({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
model: process.env.OPENAI_MODEL,
});
const contextRetriverChain = await getContextRetrieverChain();
const prompt = createTemplate();
const ragChain = RunnableSequence.from([
{
context: contextRetriverChain,
question: (input) => input.question,
},
prompt,
model,
new StringOutputParser(),
]);
return ragChain;
};
多个方法导入之后得到一个最终的RagChain,其中,引入StringOutputParser,把LLM的输出转为普通文本。
来调用一下!
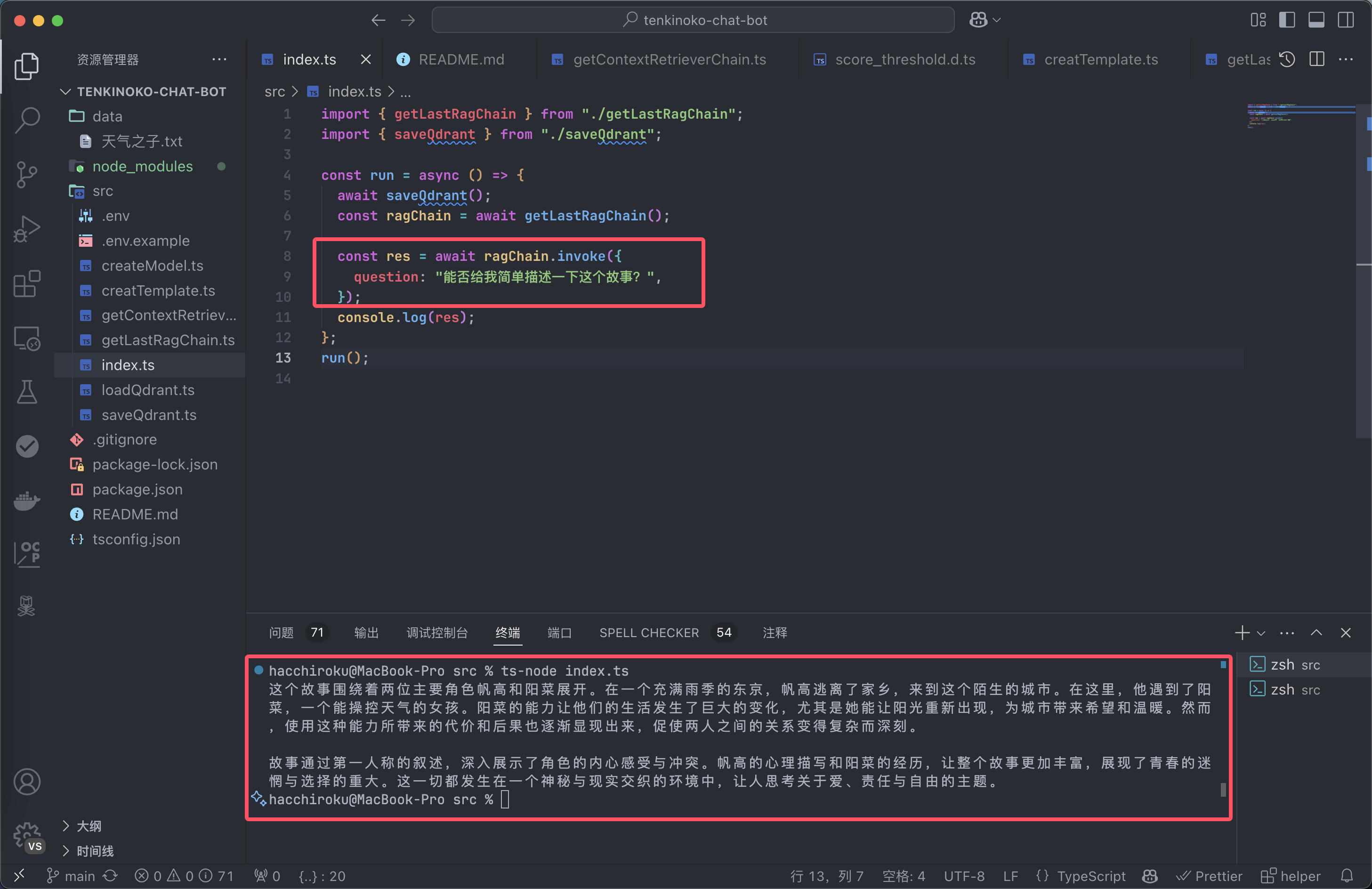
import { getLastRagChain } from "./getLastRagChain";
const run = async () => {
const ragChain = await getLastRagChain();
const res = await ragChain.invoke({
question: "什么是晴女?",
});
console.log(res);
};
run();

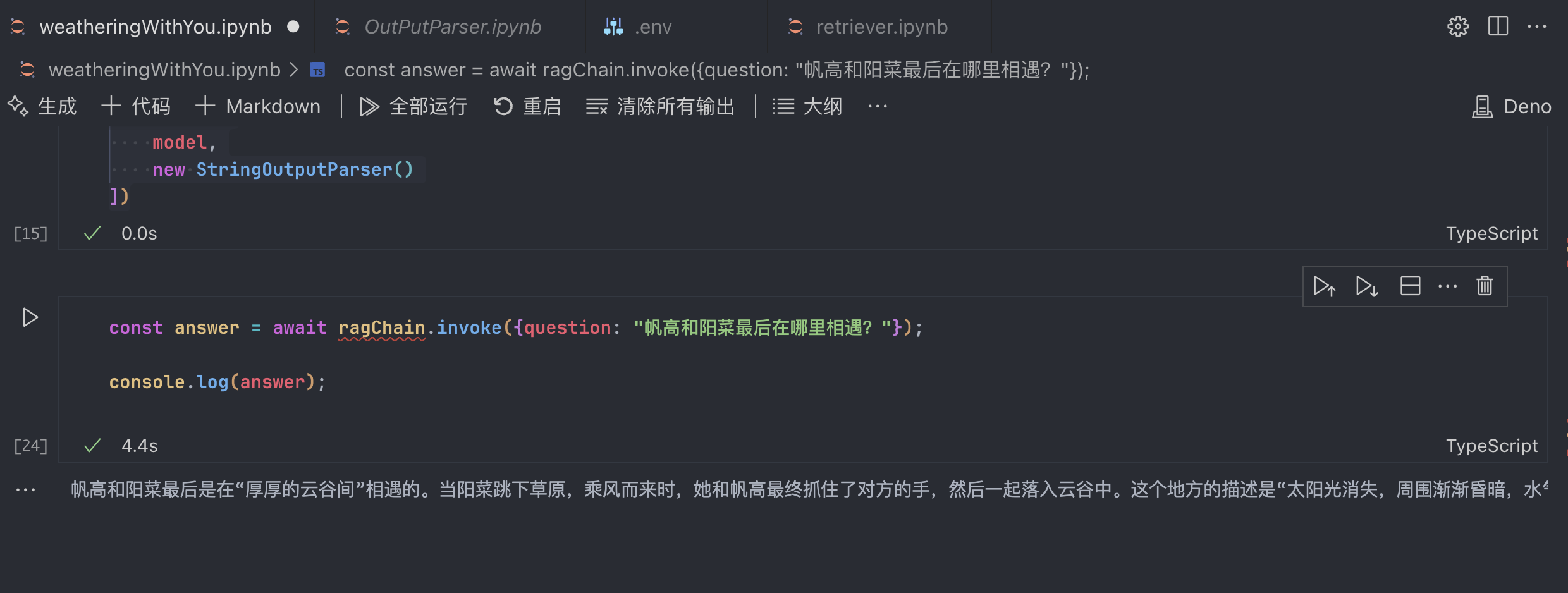
import { getLastRagChain } from "./getLastRagChain";
const run = async () => {
const ragChain = await getLastRagChain();
const res = await ragChain.invoke({
question: "东京最后的结局怎么样了?",
});
console.log(res);
};
run();

总结
Demo 源码地址:
https://github.com/ArisaTaki/tenkinoko-chat-bot
就是这样,学会了Chain的总体思路之后,实际上LLM应用的搭建就是这么轻松,当然,这只是一个Demo,有很多可以优化的地方。
我们把之前的知识全部糅合到了一起,就有了基于任何私域数据库来构建rag chatbot的能力,方便我们将LLM应用到任何公司内部已经有的数据集中(基于数据安全性,我们可以考虑一些本地大模型,Ollama的英文能力支持很不错,不亚于GPT4o mini),构建私域数据的对话机器人。
当然,我们现在还是没有实现拥有对话记录的chat,接下来就要学习一下Memory类了,拥有记忆的chatbot,很好玩吧!