对于Embedding来说,用流行的Embedding模型和Vector Store就是够够的了(对于大部分应用来说)。对于应用侧有比较大的优化空间的就是Retriever了,如果用户提问的关键词缺少了什么,或者刚好和原文的关键词不一样,就容易导致retriever返回的文档质量不高,影响最终LLM的输出效果。
所以,这里会罗列一些常见的优化方法,提高返回的文档和用户提问的相关性和质量。
这里会继续用到qdrant,所以环境还是用的Nodejs。需要留意一下费用问题。真希望Nodejs官方能出一个Jupyter的Kernel支持。。
MultiQueryRetriever
MultiQueryRetriever的思路就是加入更多的LLM。倒不如说其他解决LLM的缺陷的思路都是这样。
这里说的MultiQueryRetriever是比较简单的那一类方法,使用LLM把用户的输入改成多个不同的写法,从不同的角度表达同一个意思,从而解决因为关键词或者细微措辞差异导致的检索结果不尽人意的问题。
我们直接上代码吧,对于代码的解释已经写在注释里了:
import { QdrantVectorStore } from "@langchain/qdrant";
import { ChatOpenAI, OpenAIEmbeddings } from "@langchain/openai";
import { QdrantClient } from "@qdrant/js-client-rest";
import { MultiQueryRetriever } from "langchain/retrievers/multi_query";
import "dotenv/config";
// 加载 Qdrant 中已存储的集合
const loadQdrant = async () => {
const client = new QdrantClient({ url: process.env.QDRANT_API_URL });
const embeddings = new OpenAIEmbeddings({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
});
const vectorStore = await QdrantVectorStore.fromExistingCollection(
embeddings,
{
client: client,
collectionName: "kong_yi_ji",
}
);
return vectorStore;
};
// 创建多查询检索器
const createMultiQueryRetriever = async () => {
const vectorStore = await loadQdrant();
const model = new ChatOpenAI({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
});
const retriever = MultiQueryRetriever.fromLLM({
// 传入的llm模型
llm: model,
// 传入的向量检索器retreiver,3表示最多返回3个检索结果
retriever: vectorStore.asRetriever(3),
queryCount: 3,
// 是否打印详细信息
verbose: true,
});
return retriever;
};
// 运行
const run = async () => {
const retriever = await createMultiQueryRetriever();
const res = await retriever.invoke("茴香豆是做什么的?");
console.log("检索结果", res);
};
run();
再对MultiQueryRetriever.fromLLM的四个参数做一下单独的解释吧:
- llm:传入的llm模型,因为Retriever需要用LLM进行改写,所以我们需要传入模型。请注意,这里的llm,以及后续方法里面需要传入模型的,都可以不限于OpenAI的模型。
- retriever:Vector store的retriever,因为MultiQueryRetriever会使用这个retriever去获取向量数据库里面的数据。我们创建的时候参数写的3,代表着检索三条数据,对于每个query来说。
- queryCount:3,就代表着对每条输入,都会用llm改写生成三条不同写法和措词,但是表示的意思是一样的query
- verbose:这是所有Langchain函数的内置参数,意思很简单,设置为true就代表会打印出来Chain内部的详细执行流程,方便我们debug
运行一下。因为开启了verbose,所以内容很多,可以自己运行一下看看结果,我这里取一些关键部分来说:
首先,MultiQueryRetriever会使用你传入的LLM生成三个query,其中的Prompt就是:
You are an AI language model assistant. Your task is\nto generate 3 different versions of the given user\nquestion to retrieve relevant documents from a vector database.\nBy generating multiple perspectives on the user question,\nyour goal is to help the user overcome some of the limitations\nof distance-based similarity search.\n\nProvide these alternative questions separated by newlines between XML tags. For example:\n\n<questions>\nQuestion 1\nQuestion 2\nQuestion 3\n</questions>\n\nOriginal question: 茴香豆是做什么的?它负责告诉LLM去从检索算法的角度找到用户提问的三个角度
输出结果:
"text": {
"lines": [
"What is the purpose of using fennel seeds?",
"What are fennel seeds commonly used for?",
"What dishes include the use of fennel seeds?"
]
}你会纳闷,为啥英文?这通常是因为我选用的模型比较便宜,比如3.5 trub。默认的提示模板是英文的,导致模型倾向于生成英文查询。如果我们想要自定义中文,我们可以自行根据这种提示词的规范来写一套中文的,然后传进去:
const customPrompt =
PromptTemplate.fromTemplate(`你是一个AI语言模型助手。你的任务是生成用户问题的三个不同版本的中文表达,用于从向量数据库中检索相关文档。通过从不同角度生成用户问题的多个版本,你的目标是帮助用户克服基于距离的相似性搜索的一些限制。
请提供这些不同版本的问题,每个问题之间用换行符分隔,并用XML标签包裹。例如:
<questions>
问题1
问题2
问题3
</questions>
原始问题:{question}`);
...
const retriever = MultiQueryRetriever.fromLLM({
// 传入的llm模型
llm: model,
// 传入的向量检索器retreiver,3表示最多返回3个检索结果
retriever: vectorStore.asRetriever(3),
queryCount: 3,
// 是否打印详细信息
verbose: true,
// 在这里添加自定义的提示词
prompt: customPrompt,
});我们就能看到新的中文结果了:
"text": {
"lines": [
"茴香豆有什么用途?",
" 茴香豆主要用于什么?",
" 茴香豆通常被用来做什么?"
]
}注意:
如果你的模型的中文支持不好,也完全可以保持原样,让它用英文检索,也是可以的,没有啥问题。差距不大。
因为用户的输入是茴香豆是做什么的?,这个问题还是挺模糊的,也有一些歧义,他可能想要的答案是“茴香豆拿来下酒”,因为自然语言的特点,这有歧义。这个方法的意义就是找出这句问题所有可能的含义,然后用可能的意义去检索,避免歧义导致检索错误。
然后,MultiQueryRetriever会对每一个query调用Vector store的retriever,根据我们的参数,我们会生成3*3的结果,也就是九个,去掉重复的,返回结果。
总结一下,MultiQueryRetriever是在RAG中retriever的前期就引入LLM对于意义的理解能力,来解决纯粹的相似度搜索并不理解语义导致的问题。
这是最简单的优化方式
Document Compressor
Retriever还有一个问题就是,如果我们设置的每次检索文档返回的数量太小(queryCount: 3),因为自然语言的特殊性,可能相似度高的并不是我们想要的答案,就比如你用百度搜问题,高质量答案往往不是第一个发现的一样。。反过来,如果我们设置的太大,又容易撑爆LLM的上下文窗口。
那咋办?我们来观察一下上一段里的代码返回的值:
检索结果 [
Document {
pageContent: '有几回,邻居孩子听得笑声,也赶热闹,围住了孔乙己。他便给他们一人一颗。孩子吃完豆,仍然不散,眼睛都望着碟子。孔乙己着了慌,伸开五指将碟子罩住,弯腰下去说道,“不多了,我已经不多了。”直起身又看一看豆',
metadata: { source: '../data/孔乙己.txt', loc: [Object] },
id: '9d0db6de-7bfa-40c9-991e-52ceaf15d49a'
},
Document {
pageContent: '年前的事,现在每碗要涨到十文,——靠柜外站着,热热的喝了休息;倘肯多花一文,便可以买一碟盐煮笋,或者茴香豆,做下酒物了,如果出到十几文,那就能买一样荤菜,但这些顾客,多是短衣帮,大抵没有这样阔绰。只有',
metadata: { source: '../data/孔乙己.txt', loc: [Object] },
id: 'cd6d68db-7c2f-4add-b98f-0132dc8958a3'
}
]切割之后的Document并不全是有参考价值的内容,有很多和用户提问没有关系的内容,我们该怎么把这部分数据提出来作为Retriever返回的文档,提取出核心价值的内容,不让其他的无关废话占据上下文?
为了观察Chain内部发生的详细的事情,采用另一种debug的方案,我前面提到了
verbose:这是所有Langchain函数的内置参数
我们通过设置环境变量,让所有流程全部都打印出执行的过程吧:
LANGCHAIN_VERBOSE=true顺便一提,我做到现在发现如果是第三方服务的话,需要指定大模型,(我做着做着发现质量有点出奇的低所以看了一下发现调用的是3.5和002的embedding)
所以,为了确保最高的质量和最好的性价比,(如果你也是用的我推荐的三方服务)我们就在环境变量里加上这些内容:
OPENAI_MODEL=gpt-4o-mini
OPENAI_EMBEDDING_MODEL=text-embedding-3-small然后我们声明模型的时候要这么写:
const embeddings = new OpenAIEmbeddings({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
model: process.env.OPENAI_EMBEDDING_MODEL,
});
...
const model = new ChatOpenAI({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
model: process.env.OPENAI_MODEL,
});题外话结束,我们来看一下完整的代码流程:
import { ChatOpenAI, OpenAIEmbeddings } from "@langchain/openai";
import { QdrantClient } from "@qdrant/js-client-rest";
import { QdrantVectorStore } from "@langchain/qdrant";
import { LLMChainExtractor } from "langchain/retrievers/document_compressors/chain_extract";
import { ContextualCompressionRetriever } from "langchain/retrievers/contextual_compression";
import "dotenv/config";
const loadQdrant = async () => {
const client = new QdrantClient({ url: process.env.QDRANT_API_URL });
const embeddings = new OpenAIEmbeddings({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
model: process.env.OPENAI_EMBEDDING_MODEL,
});
const vectorStore = await QdrantVectorStore.fromExistingCollection(
embeddings,
{
client: client,
collectionName: "kong_yi_ji",
}
);
return vectorStore;
};
const createDocumentCompressor = async () => {
const model = new ChatOpenAI({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
model: process.env.OPENAI_MODEL,
});
return LLMChainExtractor.fromLLM(model);
};
const createContextualCompressionRetriever = async () => {
const compressor = await createDocumentCompressor();
const vector = await loadQdrant();
const vectorRetriever = vector.asRetriever(2);
console.log("retriever:", vectorRetriever);
const retriever = new ContextualCompressionRetriever({
baseCompressor: compressor,
baseRetriever: vectorRetriever,
});
return retriever;
};
const run = async () => {
const retriever = await createContextualCompressionRetriever();
const result = await retriever.invoke("茴香豆是做什么的?");
console.log(result);
};
run();主要的核心操作就是下面我总结的步骤:
- 像往常一样,加载Vector store。
- 创建一个专门用于从Document里提取核心内容的
Compressor(这个是要和LLM交互的) - 最后我们创建一个
ContextualCompressionRetriever,这是专门负责对上下文进行压缩的Retriever
对于最后我们使用的压缩用的ContextualCompressionRetriever,有两个参数要讲解一下:
- baseCompressor:在压上下文的时候会调用的Chain,这里接收的是任何符合Runnable Interface的对象,这里的内容你可以随意实现(比如我做的就是和LLM交互的Compressor,我拜托它做的就是提取核心的内容这件事)
- baseRetriever:检索的时候用到的retriever
最后我们调用run函数,直接跑了一遍,因为我之前加了verbose的参数,所以我们会拿到大量的运行时日志,我们来挑一些关键的地方讲讲:
- 首先会调用传入的
baseRetriever来根据query进行检索,因为我们传入了的retriever的k值等于2,所以可以返回两个Document对象: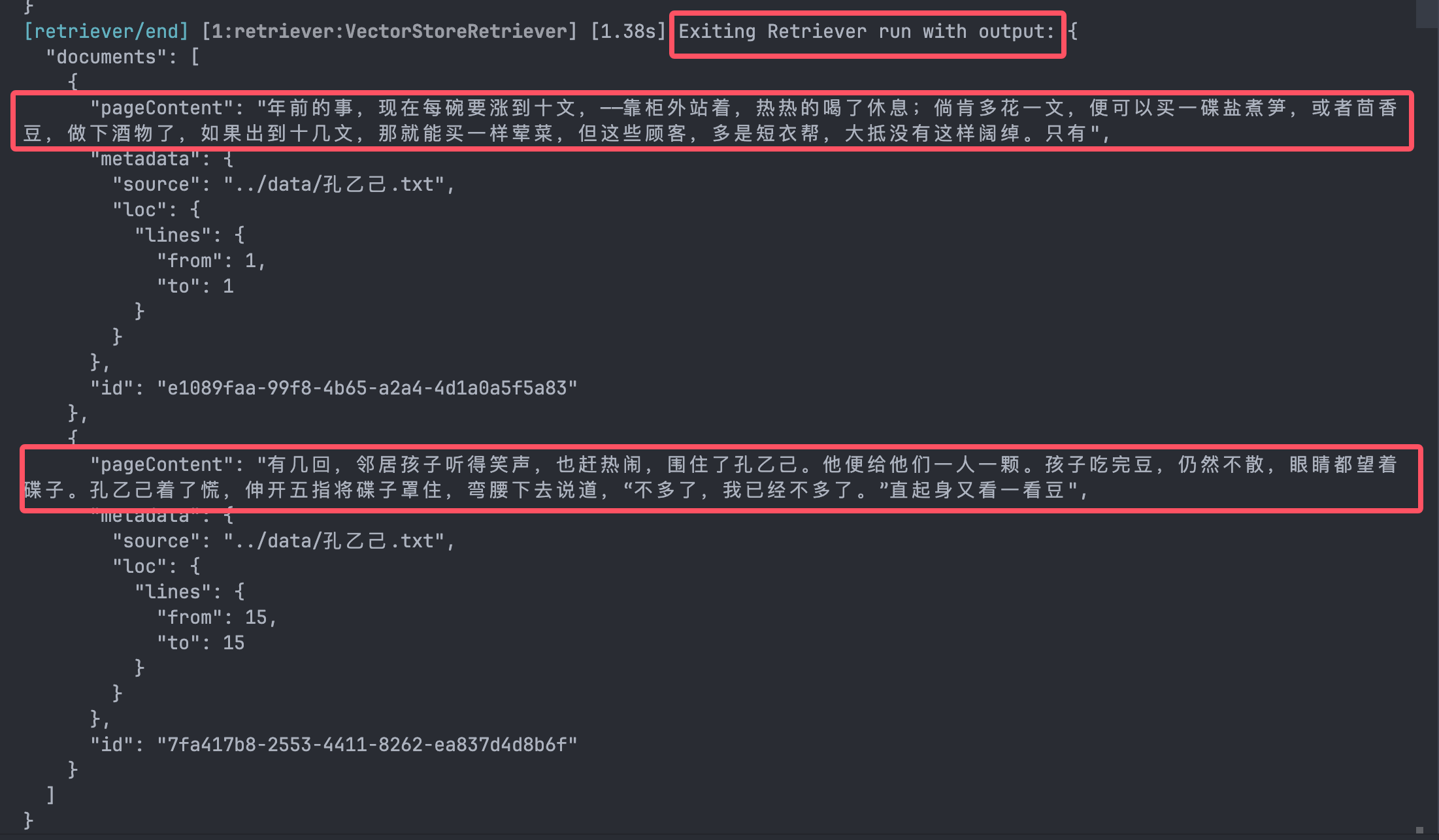
- 紧接着,走到chain的步骤,设定好question和context:

- 然后,会调用传入的
baseCompressor根据用户的问题和Document对象的内容,通过LLM进行核心内容的提取: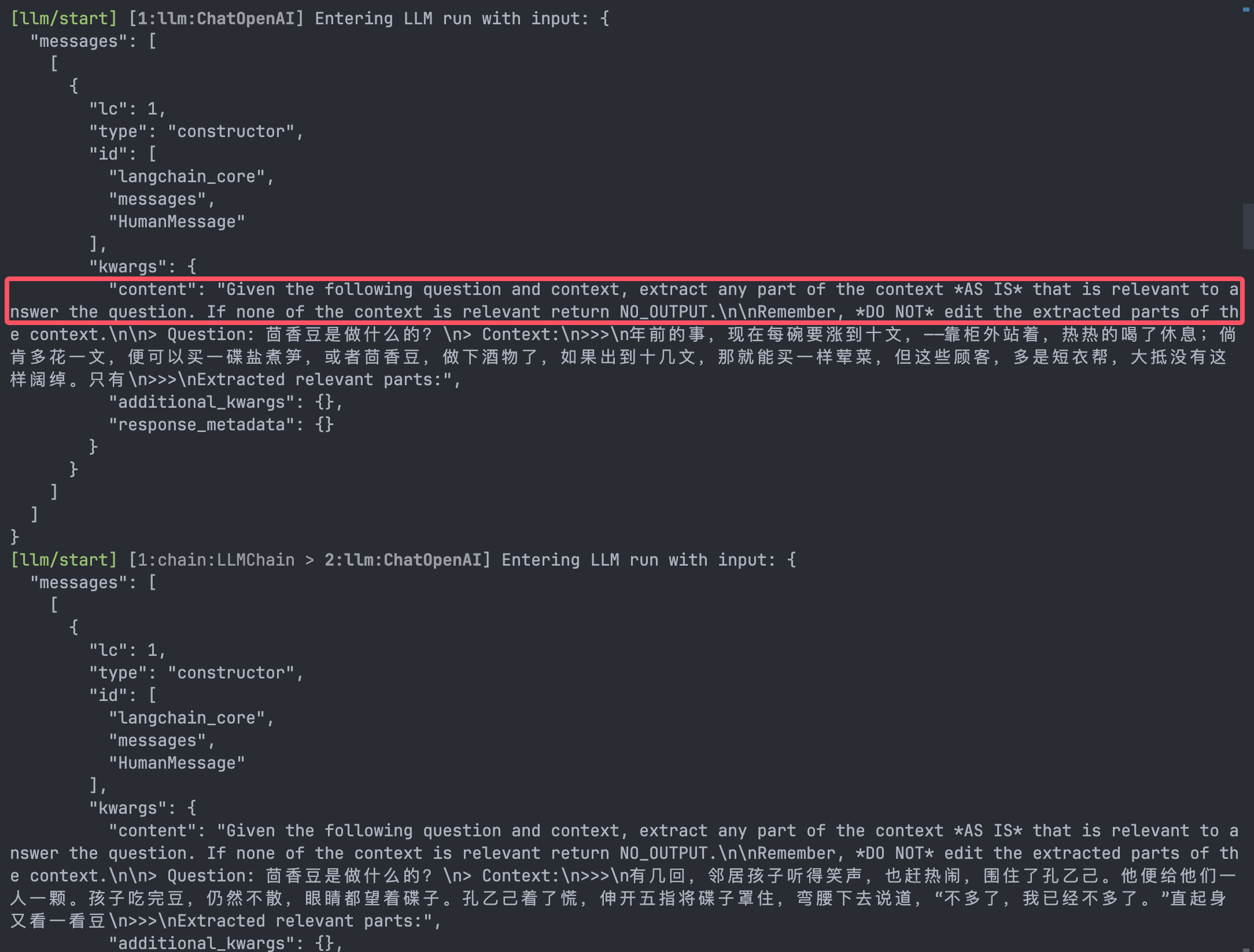
在我勾起来的地方,就是Prompt的content部分,在这里,Langchain会给LLM指定规则,要求根据用户的提问,从文档中提取出最相关的部分,并且强调不要修改提取出来的部分,避免LLM自己发挥、幻想改动原文。我之前调用asRetriever的时候参数用了2,也就是说说要从向量数据库里拿出两个Document对象,然后给LLM执行两次。可以从你的API服务看到你的使用记录,我们可以清晰地看到两次调用: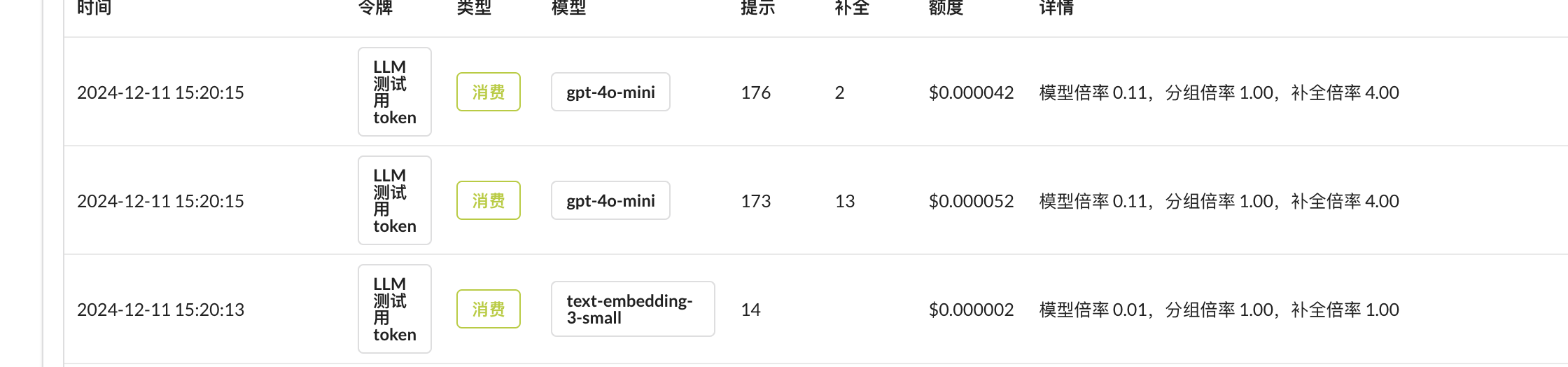
- 最后,生成结果,让我们来看看:
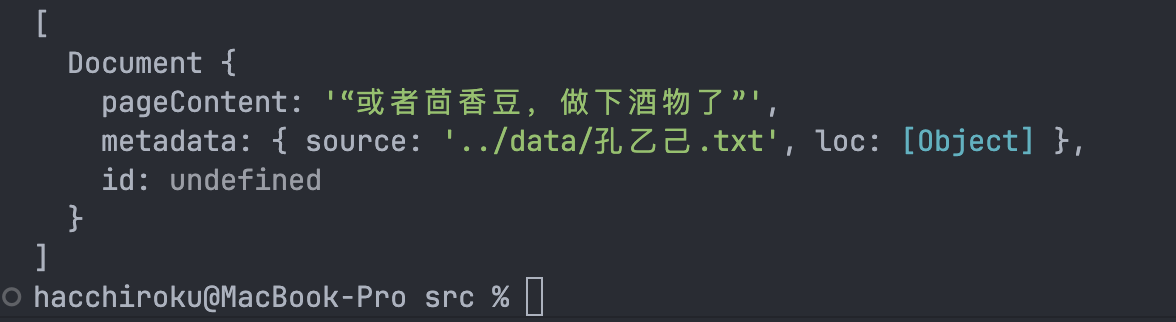
就只剩下一条了,为什么?我们来看看溯源过程,对于第二条数据,LLM返回的是NO_OUTPUT: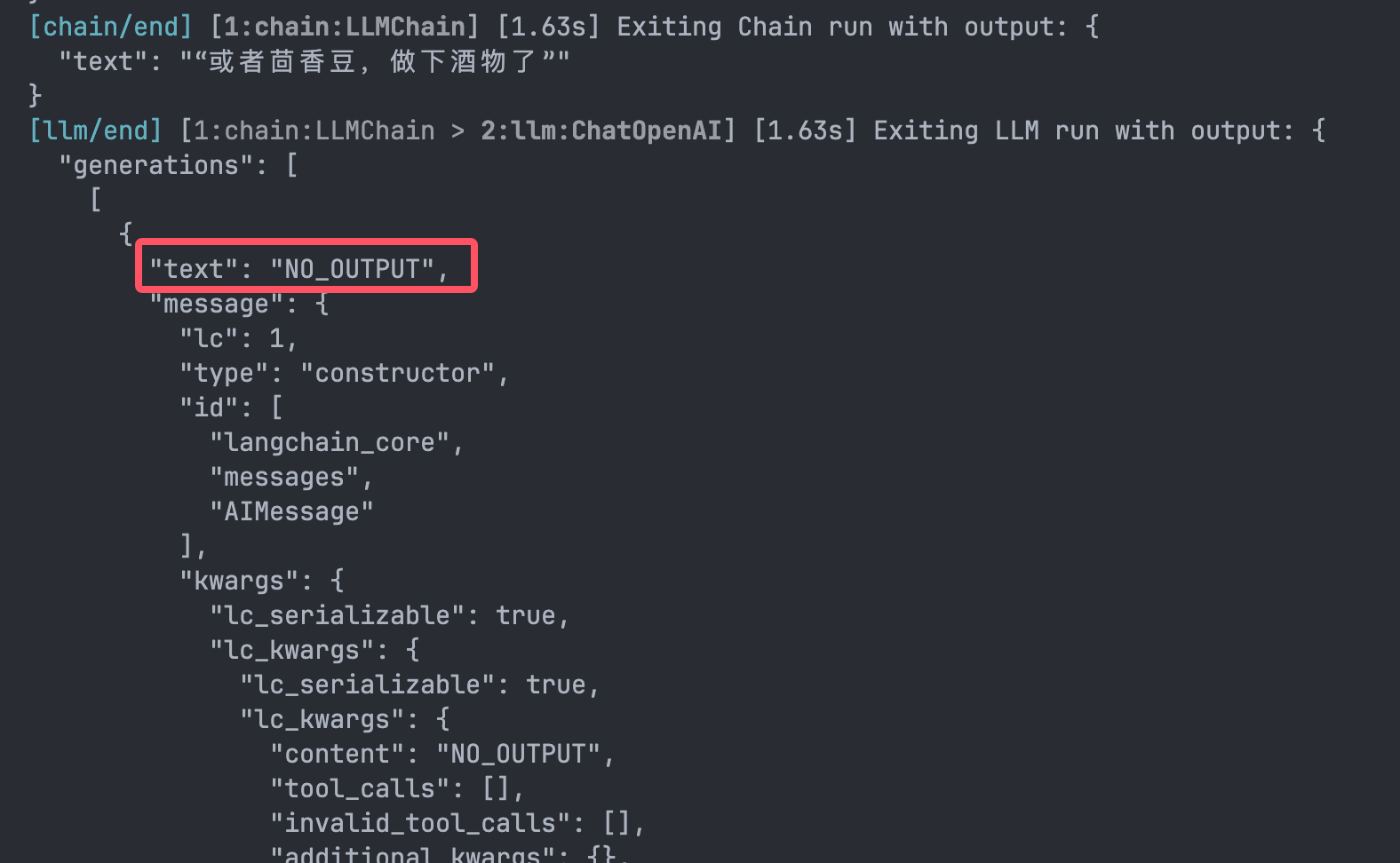
也就是说LLM认为这里没有跟上下文有关系的信息。所以最后只压缩成了最后一个Document。
综上所述,经过ContextualCompressionRetriever处理,减少了最终输出的文档的内容长度,给上下文留下了更大的空间。
ScoreThresholdRetriever
前面说了,提高retriever质量的办法就是加入更多的LLM,那么抛出问题:
const vectorRetriever = vector.asRetriever(2);这里的代码,为什么是2?是根据什么,我才设置的2?
实际上,这个参数是非常难设置的,继续来说孔乙己这个文章,我们问的是“茴香豆是做什么的?”,原文中和茴香豆这个词语有关系的情节也就2个左右,那我设置为2就是合理的,但是如果,我问的是“孔乙己是谁?做的什么工作?”,我这个设置2,就没有足够的参考下性了,咋办?
这个时候我们就需要定义另一种方式来决定返回参考文档数量,而不能局限于自己去定义。
于是,我们可以用ScoreThresholdRetriever!来试试:
import { OpenAIEmbeddings } from "@langchain/openai";
import { QdrantClient } from "@qdrant/js-client-rest";
import { QdrantVectorStore } from "@langchain/qdrant";
import { ScoreThresholdRetriever } from "langchain/retrievers/score_threshold";
import "dotenv/config";
const loadQdrant = async () => {
const client = new QdrantClient({ url: process.env.QDRANT_API_URL });
const embeddings = new OpenAIEmbeddings({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
model: process.env.OPENAI_EMBEDDING_MODEL,
verbose: true,
});
const vectorStore = await QdrantVectorStore.fromExistingCollection(
embeddings,
{
client: client,
collectionName: "kong_yi_ji",
}
);
return vectorStore;
};
const getScoreThresholdRetriever = async () => {
const vectorStore = await loadQdrant();
const retriever = ScoreThresholdRetriever.fromVectorStore(vectorStore, {
minSimilarityScore: 0.3,
maxK: 5,
kIncrement: 1,
});
return retriever;
};
const run = async () => {
const retriever = await getScoreThresholdRetriever();
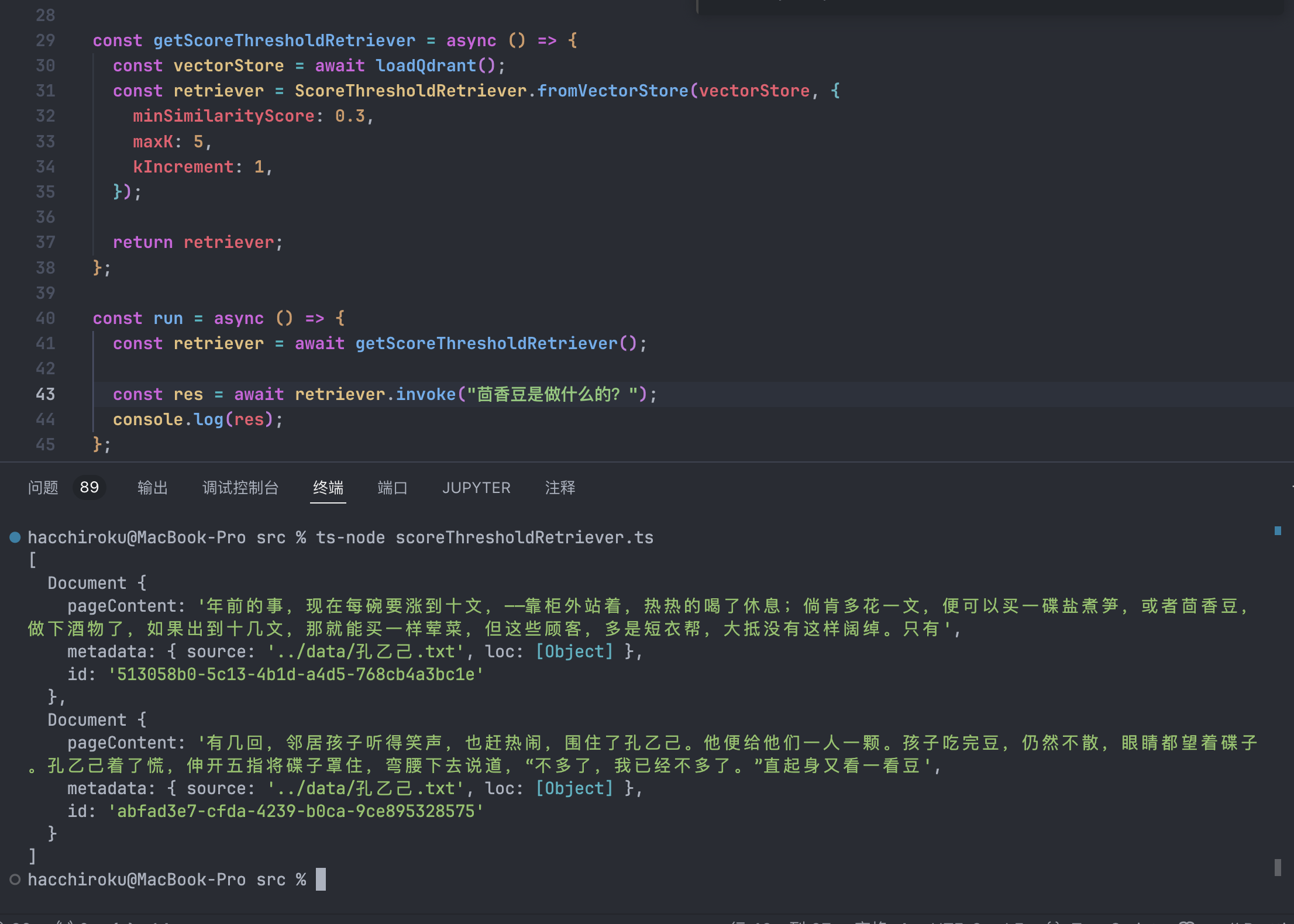
const res = await retriever.invoke("茴香豆是做什么的?");
console.log(res);
};
run();- minSimilarityScore, 定义了最小的相似度阈值,也就是文档向量和 query 向量相似度达到多少,我们就认为是可以被返回的。这个要根据你的文档类型设置,一般是 0.4 左右,严格一点可以设置为0.8
- maxK,一次最多返回多少条数据,这个主要是为了避免返回太多的文档造成 token 过度的消耗。
- kIncrement,定义了算法的布厂,你可以理解成 for 循环中的 i+k 中的 k。其逻辑是每次多获取 kIncrement 个文档,然后看这 kIncrement 个文档的相似度是否满足要求,满足则返回。
我们稍微把相似度的下限给低一点,经过调查qdrant的相似度对于中文的计算比较严苛(或许是适配性不好)得到的结果是:
插曲:Faiss-node
因为Faiss-node的github热度挺高,并且它是Facebook发布的向量数据库,而且支持本地导出数据库文件。所以尝试使用了一下。
创建数据库:
// createFaissDatabase.ts
import { TextLoader } from "langchain/document_loaders/fs/text";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { OpenAIEmbeddings } from "@langchain/openai";
import { FaissStore } from "@langchain/community/vectorstores/faiss";
import "dotenv/config";
import "faiss-node";
const run = async () => {
const loader = new TextLoader("../data/孔乙己.txt");
const docs = await loader.load();
const splitter = new RecursiveCharacterTextSplitter({
chunkOverlap: 20,
chunkSize: 100,
});
const splitDocs = await splitter.splitDocuments(docs);
const embeddings = new OpenAIEmbeddings({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
model: process.env.OPENAI_EMBEDDING_MODEL,
});
const vectorStore = await FaissStore.fromDocuments(splitDocs, embeddings);
const dir = "../db/kong_yi_ji";
await vectorStore.save(dir);
};
run();
读取数据库:
const loadFaiss = async () => {
const dir = "../db/kong_yi_ji";
const embeddings = new OpenAIEmbeddings({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
model: process.env.OPENAI_EMBEDDING_MODEL,
});
const vectorStore = await FaissStore.load(dir, embeddings);
return vectorStore;
};然后我们写一份相似度查询代码:
import { FaissStore } from "@langchain/community/vectorstores/faiss";
import { OpenAIEmbeddings } from "@langchain/openai";
import "dotenv/config";
import "faiss-node";
const loadFaiss = async () => {
const dir = "../db/kong_yi_ji";
const embeddings = new OpenAIEmbeddings({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
model: process.env.OPENAI_EMBEDDING_MODEL,
});
const vectorStore = await FaissStore.load(dir, embeddings);
return vectorStore;
};
const retrieveWithScores = async (query: any) => {
const vectorStore = await loadFaiss();
console.log("vectorStore", vectorStore);
const results = await vectorStore.similaritySearchWithScore(
query,
5 // 设置要返回的最大文档数量
);
console.log("results", results);
// 将相似度分数添加到每个文档的元数据中
const documentsWithScores = results.map(([doc, score]) => {
doc.metadata = { ...doc.metadata, similarity_score: score };
return doc;
});
return documentsWithScores;
};
const run = async () => {
const results = await retrieveWithScores("茴香豆是做什么的?");
results.forEach((doc, index) => {
console.log(`Result ${index + 1}:`);
console.log(`Content: ${doc.pageContent}`);
console.log(`Similarity Score: ${doc.metadata.similarity_score}`);
console.log(`Metadata: ${JSON.stringify(doc.metadata)}`);
console.log("---");
});
};
run();
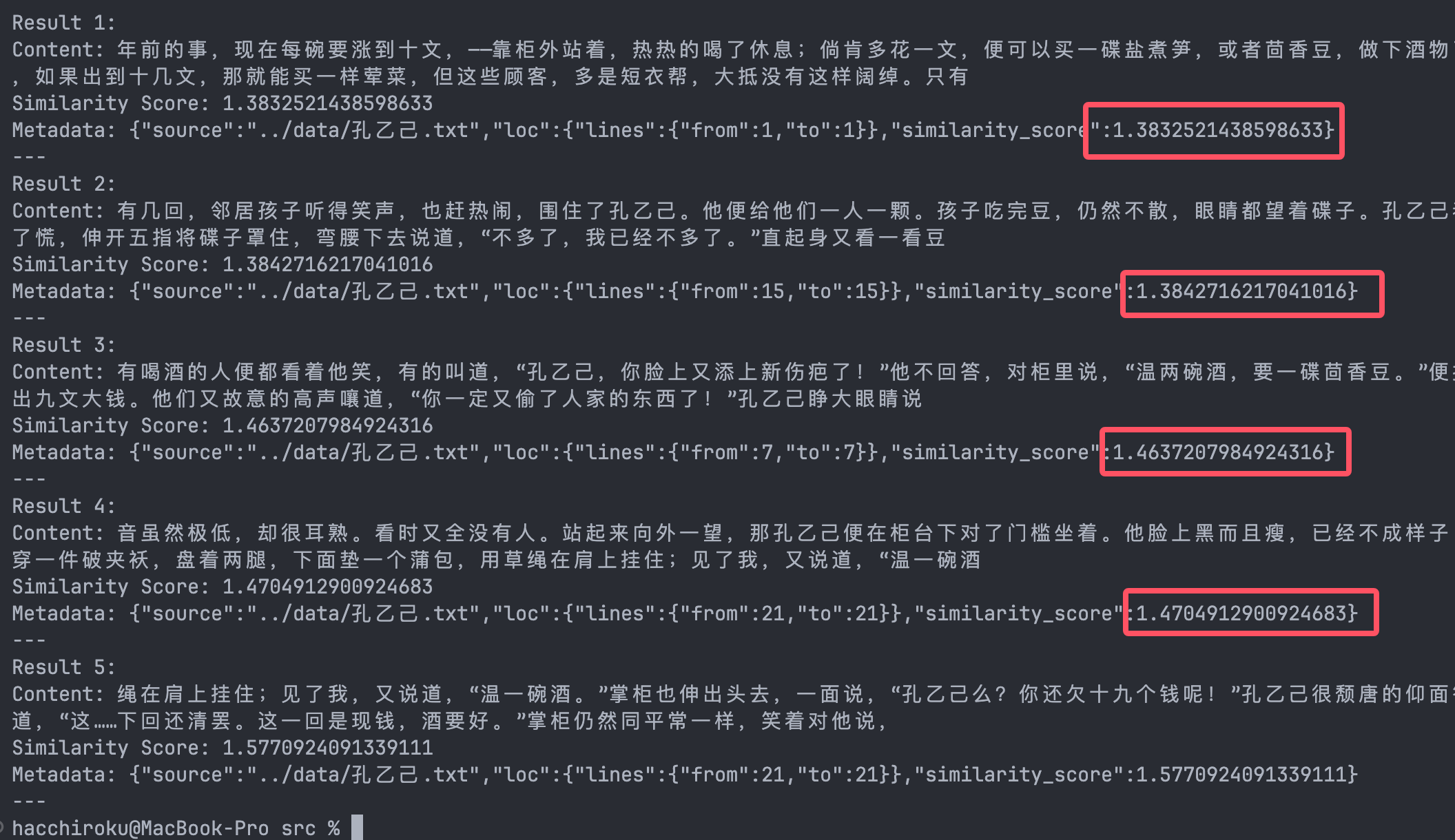
发现了吗。远远超出了我们之前的ScoreThresholdRetriever设定的阈值,我查询了一下文献,得到的答案是:
- Faiss-node的默认算法是
欧氏距离(L2 距离),衡量的是向量之间的距离,表示距离越小,表示向量越相似。 - ScoreThresholdRetriever 是假设向量存储返回的分数越高,表示相似度越高。
所以两者的排序规则是完全相反了,如果要满足ScoreThresholdRetriever的计算方式,我们可以把faiss-node的算法改成内积,或者尝试归一化。
改成内积算法
import faiss from 'faiss-node';
const createInnerProductIndex = async (embeddings) => {
// 创建内积索引
const dimension = embeddings[0].length;
const index = new faiss.IndexFlatIP(dimension);
// 添加向量到索引
index.add(embeddings);
return index;
};
const searchWithInnerProduct = async (index, queryVector, topK) => {
// 查询时直接使用原始向量
const [distances, indices] = index.search(queryVector, topK);
return { distances, indices };
};
// 示例用法
const embeddings = [[0.1, 0.2, 0.3], [0.4, 0.5, 0.6], [0.7, 0.8, 0.9]];
const queryVector = [0.1, 0.2, 0.3];
(async () => {
const index = await createInnerProductIndex(embeddings);
const { distances, indices } = await searchWithInnerProduct(index, queryVector, 5);
console.log('Distances:', distances);
console.log('Indices:', indices);
})();归一化
import faiss from 'faiss-node';
const normalizeVectors = (vectors) => {
vectors.forEach((vector) => faiss.normalize_L2(vector));
};
const createNormalizedIndex = async (embeddings) => {
// 归一化向量
normalizeVectors(embeddings);
// 创建内积索引
const dimension = embeddings[0].length;
const index = new faiss.IndexFlatIP(dimension);
// 添加归一化后的向量到索引
index.add(embeddings);
return index;
};
const searchWithNormalizedVectors = async (index, queryVector, topK) => {
// 对查询向量进行归一化
faiss.normalize_L2(queryVector);
const [distances, indices] = index.search(queryVector, topK);
return { distances, indices };
};
// 示例用法
const embeddings = [[0.1, 0.2, 0.3], [0.4, 0.5, 0.6], [0.7, 0.8, 0.9]];
const queryVector = [0.1, 0.2, 0.3];
(async () => {
const index = await createNormalizedIndex(embeddings);
const { distances, indices } = await searchWithNormalizedVectors(index, queryVector, 5);
console.log('Distances:', distances);
console.log('Indices:', indices);
})();对比一下两种方法的效果:
| 方法 | 优点 | 缺点 |
|---|---|---|
| 使用内积 | 简单直接,符合 ScoreThresholdRetriever 的分数逻辑,无需额外处理。 | 如果需要余弦相似度结果,需要额外计算。 |
| 使用归一化 | 符合余弦相似度的意义,结果直观且更常用于语义搜索场景。 | 需要在数据处理和查询时额外进行归一化处理。 |
结束这个faiss-node的小插曲之后,我们总结一下这个ScoreThresholdRetriever方法:
如果对于宽松度挺低的应用,建议相似度设置低一点,对于法律文书之类的查询的,建议相似度设置高一点,自适应嘛。
总结
Retriever在RAG是非常重要的内容,也有足够的优化空间,引入LLM进行优化的效果也是最好的,得益于langchain的模块化和自由度,这些优化都是容易做到的,就是要多尝试。