前面的文章,我们搞定了数据加载和切分,接下来就不是小打小闹了,是RAG的精髓Embedding,也是我学下来,认为影响RAG上限和想象空间最关键的地方
这里我们会把之前切分的数据集构建出对应的embedding对象,然后把所有的embedding存储在Vector db里,尝试根据用户的提问,对db进行检索,找到和用户提问最关联的数据集
Embedding~
复用一下之前的代码,我们继续分割周树人先生的小说:
import { TextLoader } from "langchain/document_loaders/fs/text"
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter"
const loader = new TextLoader("data/孔乙己.txt");
const docs = await loader.load();
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 100,
chunkOverlap: 20,
});
const splitDocs = await splitter.splitDocuments(docs);
splitDocs这次我们把size和overlap都设置大一点,因为短篇小说总长度只有2000多字,情节也比较紧凑,这样切割出来的块比较小,而且会节约Embedding期间的花费
开始创建一个embedding模型,在使用任何OpenAI的工具时,一定要记得导入相关的env变量,如果你是用的Azure OpenAI,请参考我之前的文章,如果你和我一样使用的是第三方的OpenAI服务,那么就这样写:
import { load } from "dotenv"
const env = await load();
const process = {
env
}
import { TextLoader } from "langchain/document_loaders/fs/text"
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter"
import { OpenAIEmbeddings } from "@langchain/openai"
const embeddings = new OpenAIEmbeddings({
configuration: {
baseURL: process.env.OPENAI_API_URL,
}
});
const loader = new TextLoader("data/孔乙己.txt");
const docs = await loader.load();
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 100,
chunkOverlap: 20,
});
const splitDocs = await splitter.splitDocuments(docs);
const res = await embeddings.embedQuery(splitDocs[0].pageContent);注意:要在服务商的服务里添加对模型text-embedding-ada-002的许可,不然会令牌无效我们来看看embedding之后的样子:
[ 0.0174706, 0.0005322538, 0.01510008, -0.021458007, -0.0067655756, -0.010098692, -0.022348665, -0.005809831, -0.0074541224, -0.030282373, -0.009228587, 0.021745758, -0.013031012, 0.00335367, -0.01318859, 0.01832015, 0.006628551, 0.010297377, 0.02789815, -0.012811773, -0.031378567, 0.011064713, 0.0024064896, -0.0059160246, -0.026199048, 0.01853939, 0.020087764, -0.010749557, -0.001663989, 0.015963333, 0.00009875385, 0.002392787, -0.029953515, -0.015853712, -0.005128135, -0.002130728, -0.0001732073, -0.0028877873, 0.016251083, -0.0056796577, 0.00050570536, -0.0074541224, 0.014853436, 0.013764092, -0.014223124, 0.019525964, 0.0062174783, 0.013510597, -0.013990182, -0.0009745854, 0.0066765095, 0.008426995, -0.030337183, -0.008070732, -0.008584573, 0.0024082023, -0.003990833, 0.032200713, -0.0043882034, -0.033214692, -0.011181184, 0.007974815, -0.047903698, 0.013633919, -0.0063373744, 0.008495508, -0.019251917, -0.006505229, 0.024719186, 0.0003048791, 0.0332421, 0.048945084, 0.008235161, -0.009050456, 0.028912129, -0.023828527, -0.026623825, -0.005963983, -0.010845474, 0.00828997, 0.009598553, -0.036284037, -0.009509487, 0.0063990355, 0.016881395, 0.022006104, -0.0075363372, 0.039928883, 0.000784036, -0.030090539, -0.007289693, 0.0021632714, 0.022622714, 0.018361257, -0.00020628583, 0.009098414, 0.030501612, 0.018580496, 0.008509209, -0.020416623, ... 1436 more items ]Embedding的原理之前在RAG的文章里讲过了,本质上就是用一个向量来表达文本。
创建MemoryVectorStore
Vectored Store提供的是存储向量和原始文档,并且提供了基于向量进行相关性检索的能力。LangChain提供了用于测试的在内存中构建的向量数据库,且支持多种常见的相似性度量方式
请注意,因为Embedding向量需要一定的花费,所以仅仅在学习和测试的时候我们使用MemoryVectorStore,而在真实的项目里,我们是需要搭建其他的向量数据库的,或者云数据库。
这里可以不用跟着做,节约开销
我们先创建MemoryVectorStore的实例,传入需要Embeddings的模型,在上文,这个模型就是embeddings变量。调用添加文档的addDocuments函数,然后LangChain的MemoryVectorStore就会自动帮助我们完成对每个文档请求embeddings的模型,随后存入数据库的操作
import { MemoryVectorStore } from "langchain/vectorstores/memory"
const vectorStore = new MemoryVectorStore(embeddings);
await vectorStore.addDocuments(splitDocs);然后,我们创建一个retriever,这也可以从vector store的实例中自动生成,我们传入了参数2,代表着对应每个输入,我想要返回两个相似度最高的文本内容
const retriever = vectorStore.asRetriever(2);再来,我们就可以使用retriever获取文档,比如说:
const results = await retriever.invoke("茴香豆是做什么的?");[
Document {
pageContent: "有喝酒的人便都看着他笑,有的叫道,“孔乙己,你脸上又添上新伤疤了!”他不回答,对柜里说,“温两碗酒,要一碟茴香豆。”便排出九文大钱。他们又故意的高声嚷道,“你一定又偷了人家的东西了!”孔乙己睁大眼睛说",
metadata: { source: "data/孔乙己.txt", loc: { lines: { from: 7, to: 7 } } }
},
Document {
pageContent: "有几回,邻居孩子听得笑声,也赶热闹,围住了孔乙己。他便给他们一人一颗。孩子吃完豆,仍然不散,眼睛都望着碟子。孔乙己着了慌,伸开五指将碟子罩住,弯腰下去说道,“不多了,我已经不多了。”直起身又看一看豆",
metadata: { source: "data/孔乙己.txt", loc: { lines: { from: 15, to: 15 } } }
}
]就提取出一些和茴香豆有关系的内容了,提取的时候,是根据相似度进行度量的,所以说,如果用户问的很简洁,没有关键词,就会出现提取到错误信息的问题,像这样:
const resWr1 = await retriever.invoke("下酒菜是一般是什么?");
resWr1返回内容是:
[
Document {
pageContent: "顾客,多是短衣帮,大抵没有这样阔绰。只有穿长衫的,才踱进店面隔壁的房子里,要酒要菜,慢慢地坐喝。",
metadata: { source: "data/孔乙己.txt", loc: { lines: { from: 1, to: 1 } } }
},
Document {
pageContent: "有喝酒的人便都看着他笑,有的叫道,“孔乙己,你脸上又添上新伤疤了!”他不回答,对柜里说,“温两碗酒,要一碟茴香豆。”便排出九文大钱。他们又故意的高声嚷道,“你一定又偷了人家的东西了!”孔乙己睁大眼睛说",
metadata: { source: "data/孔乙己.txt", loc: { lines: { from: 7, to: 7 } } }
}
]这里的第一个数据源和下酒菜有关系,但是我们的答案在第二个数据源里,是茴香豆。所以,一般来说为了提高回答的质量,返回更多的数据源是具有价值的。
但如果,要涉及到很多语义才能理解并且构建出联系的情况就很难说了,比如说:
const resWr2 = await retriever.invoke("孔乙己靠什么维持生计?");
resWr2[
Document {
pageContent: "孔乙己是这样的使人快活,可是没有他,别人也便这么过。",
metadata: { source: "data/孔乙己.txt", loc: { lines: { from: 17, to: 17 } } }
},
Document {
pageContent: "自此以后,又长久没有看见孔乙己。到了年关,掌柜取下粉板说,“孔乙己还欠十九个钱呢!”到第二年的端午,又说“孔乙己还欠十九个钱呢!”到中秋可是没有说,再到年关也没有看见他。",
metadata: { source: "data/孔乙己.txt", loc: { lines: { from: 23, to: 23 } } }
}
]这样的问题,很难依靠比对相似度来查找正确的数据源,需要多层语义的转换才可以找到合适的数据源,这样的情况怎么解决,放在后面的内容,慢慢一步步来。
构建本地Vector store
因为对数据生成embedding需要开销,所以我们更希望把Embedding的结果给持久化掉,这样可以在应用中持续复用。因为JS本身也不是一个面向后端和机器学习的语言,所以原生的Vector store并不多,大多数还是支持Python为主。
就目前而言,有像 lanceDB 原生支持 js 的,但毕竟是少数。
就工程方面而言,JavaScript作为一个面向应用和用户的语言,并不擅长做数据库相关的处理,在实际工作里,js是对接的由其他语言管理的向量数据库,或者直接对接云数据库,来隔离复杂度,让js把更多的关注点放在应用和业务逻辑上。
所以我们将使用 Qdrant 向量数据库,是向量数据库中非常流行的开源解决方案。选择这个的原因是其可以将向量数据库导出成文件,并且提供了 nodejs 的处理方式。
在未来的实际开发中,我们有两种方法可以选择
- 用JS进行Embedding和持久化存储,后续用JS读取持久化的向量数据库进行使用
- 用Python进行embedding并且持久化储存为文件,然后用JS读取和使用。
如果未来某天,我们对于可靠性的需求量变大,可以容易地把数据库内容导出到其他数据库或者云上。
现在Deno和qdrant有兼容问题,所以我们暂时切换到正常的node来实现这部分的功能。
值得一提的是,我们使用Jupyter Lab + deno来做测试和开发。如果有好的项目需要落地,还是可以考虑更加成熟的Nodejs。
创建一个正常的Nodejs + TS的项目:
然后运行:
yarn add dotenv @qdrant/js-client-rest langchain @langchain/qdrant我们来安装一下docker容器 qdrant/qdrant:latest
可以在desktop上直接安装,之后启动,会给出一个地址,能够看到这个向量数据库的欢迎页面:
就代表安装好了。
我们再进入创建好的TS nodejs项目,书写:
import { QdrantClient } from "@qdrant/js-client-rest";
import { TextLoader } from "langchain/document_loaders/fs/text";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { OpenAIEmbeddings } from "@langchain/openai";
import { QdrantVectorStore } from "@langchain/qdrant";
import "dotenv/config";
const run = async () => {
const loader = new TextLoader("../data/孔乙己.txt");
const docs = await loader.load();
const splitter = new RecursiveCharacterTextSplitter({
chunkOverlap: 20,
chunkSize: 100,
});
const client = new QdrantClient({ url: process.env.QDRANT_API_URL });
const splitDocs = await splitter.splitDocuments(docs);
const embeddings = new OpenAIEmbeddings({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
});
await QdrantVectorStore.fromDocuments(splitDocs, embeddings, {
client: client,
collectionName: "kong_yi_ji",
});
};
run();
qdrant的默认地址是:
QDRANT_API_URL=http://localhost:6333/运行这个代码之后,我们可以在下面的地址里找到我们新创建的向量数据库:
http://localhost:6333/dashboard#/collections/kong_yi_ji
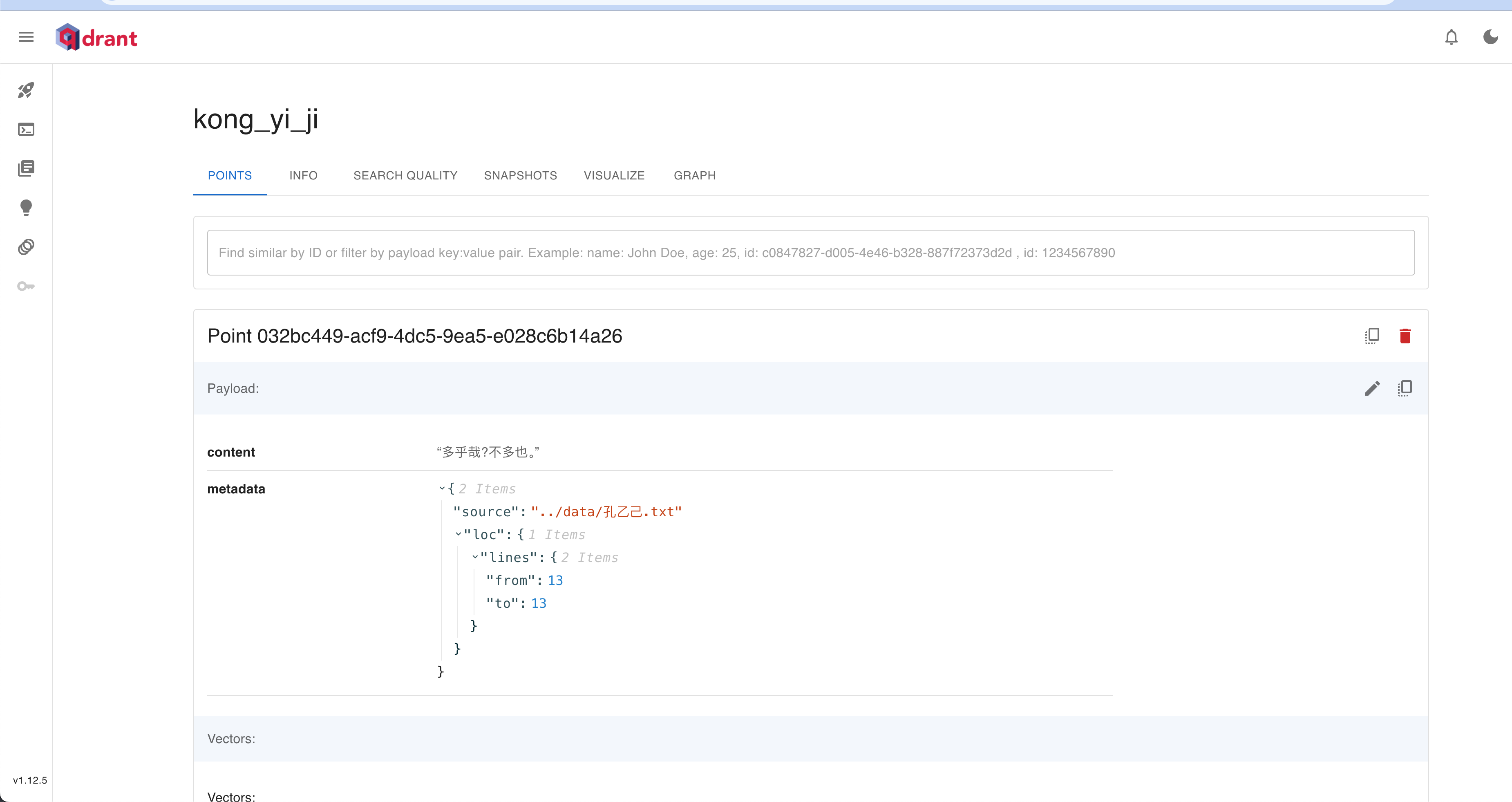
我们这样从向量数据库里获取到值:
import { QdrantVectorStore } from "@langchain/qdrant";
import { OpenAIEmbeddings } from "@langchain/openai";
import { QdrantClient } from "@qdrant/js-client-rest";
import "dotenv/config";
const loadStoredVectors = async () => {
const client = new QdrantClient({ url: process.env.QDRANT_API_URL });
const embeddings = new OpenAIEmbeddings({
configuration: {
baseURL: process.env.OPENAI_API_URL,
},
});
// 加载 Qdrant 中已存储的集合
const vectorStore = await QdrantVectorStore.fromExistingCollection(
embeddings,
{
client: client,
collectionName: "kong_yi_ji",
}
);
return vectorStore;
};
const askQdrant = async () => {
const vectorStore = await loadStoredVectors();
const retriever = vectorStore.asRetriever(2);
const res = await retriever.invoke("茴香豆是做什么的?");
console.log("检索结果", res);
};
askQdrant();
[
Document {
pageContent: '有喝酒的人便都看着他笑,有的叫道,“孔乙己,你脸上又添上新伤疤了!”他不回答,对柜里说,“温两碗酒,要一碟茴香豆。”便排出九文大钱。他们又故意的高声嚷道,“你一定又偷了人家的东西了!”孔乙己睁大眼睛说',
metadata: { source: '../data/孔乙己.txt', loc: [Object] },
id: '6fffaa81-69c6-4093-a4d2-7ad2e0dbb843'
},
Document {
pageContent: '有喝酒的人便都看着他笑,有的叫道,“孔乙己,你脸上又添上新伤疤了!”他不回答,对柜里说,“温两碗酒,要一碟茴香豆。”便排出九文大钱。他们又故意的高声嚷道,“你一定又偷了人家的东西了!”孔乙己睁大眼睛说',
metadata: { source: '../data/孔乙己.txt', loc: [Object] },
id: '77e96474-4762-4e7d-a325-28c5f406edd7'
}
]检索出来的内容跟我们使用 MemoryVectorStore 创建的 vector store 的返回值是很相似的,因为数据库的效果各自差距不大。
顺带提一下:qdrant的备份和提取也非常的简单:
在SNAPSHOTS的tab里点击take:
导入的话也很容易:
总结
Vector Store是RAG与LLM APP非常核心的内容,关于这一篇文章的内容,我有很多要总结的话要说。首先,最好是在Vector Store上面用retriever用不同的方式提问,切实感受相似性搜索的原理。
因为这个文集主要是讲的LangChainJS,本人也是端侧程序员,在我的观点看来,不需要了解LLM深层次的原理,但是必须要对embedding和相似性搜索有一个切实的感觉,大概理解原理和应用的效果。
多尝试retriever,就跟和LLM交互的原理是差不多的了。你需要在Prompt里提取到最合适的关键词,比如:
- "帮我使用网盘实现数据共通"
- "帮我使用alist+网盘的方案实现多端数据共通"
LLM根据这两句话返回的内容是完全不一样的,这就是Prompt engineering的底层逻辑,通过最重要的关键词促使LLM找到对应的知识。这些定性的感受都可以从你多次尝试retriever中获得理解。
再次回到Vector Store的选择问题上,现在市面上有五花八门的号称地表最强的向量数据库,让人不知道如何抉择,那么干脆就不要这么快陷入优化陷阱,发展的问题可以随着发展来解决。实际上在上面的例子中,MemoryVectoreStore和qdrant得到的结果有很大的重叠部分,对于小规模的应用,不同的向量数据库效果差距并不大。哪怕是以后真的遇到了问题,也是可以很轻松的把数据迁移。
JavaScript确实不是适合面向数据库的语言,但是也不用为此就转为Python,因为JS + qdrant的方案也很简单,如果JS解决不了,到时候切换Python也不迟,LangChain的两种语言,py和js的API都是非常的相似,切换起来成本很低。
LLM APP,先跑起来!