受限于常见LLM的上下文大小,比如GPT4的128K,我们很多时候都不能把完整的数据整个塞到对话的上下文里。
而且,就算数据源接近了LLM的上下文窗口,在读取数据的时候很容易出现“注意力”机制可能变得不够专注,从而影响输出的准确性或相关性。这种现象
所以说,我们需要对加载进来的数据进行切分,分成较为小的块,根据对话的内容,将最关联的数据塞给LLM的上下文里,强化LLM的输出的专注性和质量
对于分割来说,我们的目的是把文本切分为多个文档块,每个文档块的内部语义相关,并且和其他的块都各自具备独立性,能够独立的表达和阐述某个信息。非常的复杂,对于RAG特性来说,语义切分的质量就决定了对话的时候LLM获取信息的质量,同时也就决定了最后获取生成答案的质量。
So,TextSplitter的工作方式就很好解释了:
- 首先是根据预设的分块逻辑,把内容切分成好几块,每个块都是表达独立的语义。对于一般文本而言,可以理解为切分到句子这一级别,因为切分到词语的话,语义性就丧失了。
- 开始把这些块组装起来,一直到用户预设的块的大小限制
组装完一个块之后,会根据同样的逻辑去组另一块。在组装过程中,会根据用户设定的块之前的重叠大小,来给文档块添加与上下文档块重叠的部分。比如说:第一个块是AABBCC,第二个就是CCDDEE,第三个自然而然就是EEFFGG了。
重叠的理由很简单,为了防止语义的中断,主要是受限于自然语言的特殊性,我们要给切分块的加入与前后文档块重叠的部分。
切分逻辑理解之后,我们就抛出两个问题吧。当我们需要根据数据类型进行切分的时候,怎么选择切分器呢?
- 目标文档的类型是?
- 怎么衡量切分之后的文档块的大小?
从现在的LangChain提供的切分能力来看,仅我个人观点,根据文档类型选择切分工具是最重要的点。我罗列一下LangChain的切分工具:
| 切分方法 | 成本来源 | 直接金钱成本 | 计算成本 | 适用场景 |
|---|---|---|---|---|
| CharacterTextSplitter | 简单字符匹配,无复杂逻辑 | 无 | 极低 | 简单分割场景 |
| TokenTextSplitter | 标记器依赖库计算标记数量 | 无 | 低 | 精确控制标记数量的场景 |
| Markdown/HTML Splitters | 文档格式解析 | 无 | 低 | 处理结构化文档的场景 |
| CodeTextSplitter | 解析代码的语法规则 | 无 | 低 | 代码分割需求 |
| RecursiveCharacterTextSplitter | 递归计算分割块,深度增加会提高计算复杂度 | 无 | 中 | 需要保持上下文连贯性的文本 |
| SemanticChunker | 嵌入模型调用,语义分析,可能需要 API 费用 | 高 | 高 | 高语义要求的文本分割 |
| AI21SemanticTextSplitter | 调用 AI21 API 进行语义分析,依赖外部服务 | 高 | 高 | 高级语义分析和大规模文本场景 |
接下来我要分成两部分讲解
低成本
RecursiveCharacterTextSplitter
先来看看最常用的切分工具:RecursiveCharacterTextSplitter,根据内置的一些字符对原始文本进行递归切分,来维持相关的文本片段的相邻,保证切分结果内部的语义相关性
默认的分隔符列表是["\n\n", "\n", " ", ""],你可以理解为切割的逻辑是先把原文切分为段落,再把段落切分为句子,单词,根据我们定义的chunk的大小,尽可能放在一起,保证语义的连贯性和相关性
最最影响切分质量的有两个参数
ChunkSize定义了切分结果每个块的大小,这直接决定了LLM在每个块里能够获取到的上下文。需要根据数据源的内容类型来决定,如果太大,一个块有可能会包含过多的信息,导致LLM产生”注意力“不专注的问题,并且,这个结果会作为对话的上下文输入给LLM,导致Token增加,从而增加了成本。如果太小,一个块没有包含足够的信息,会影响输出的质量ChunkOverlap定义了块和块之间重叠部分的大小,因为在自然语言里,内容是连续的,分块的时候给予一定的重叠可以让文本不会在奇怪的地方被切割,让内容保持一定的上下文。比较大的ChunkOverlap可以保证文本不会被奇怪的分割,但是可能会导致重复提取信息,太小的话可以会减少重复提取信息的可能性,但是容易在奇怪的地方切割。
来试试切割《孔乙己》:
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter"
import { TextLoader } from "langchain/document_loaders/fs/text"
const loader = new TextLoader("data/孔乙己.txt")
const docs = await loader.load()
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 64,
chunkOverlap: 0
})
const splitDoc = await splitter.splitDocuments(docs)
splitDoc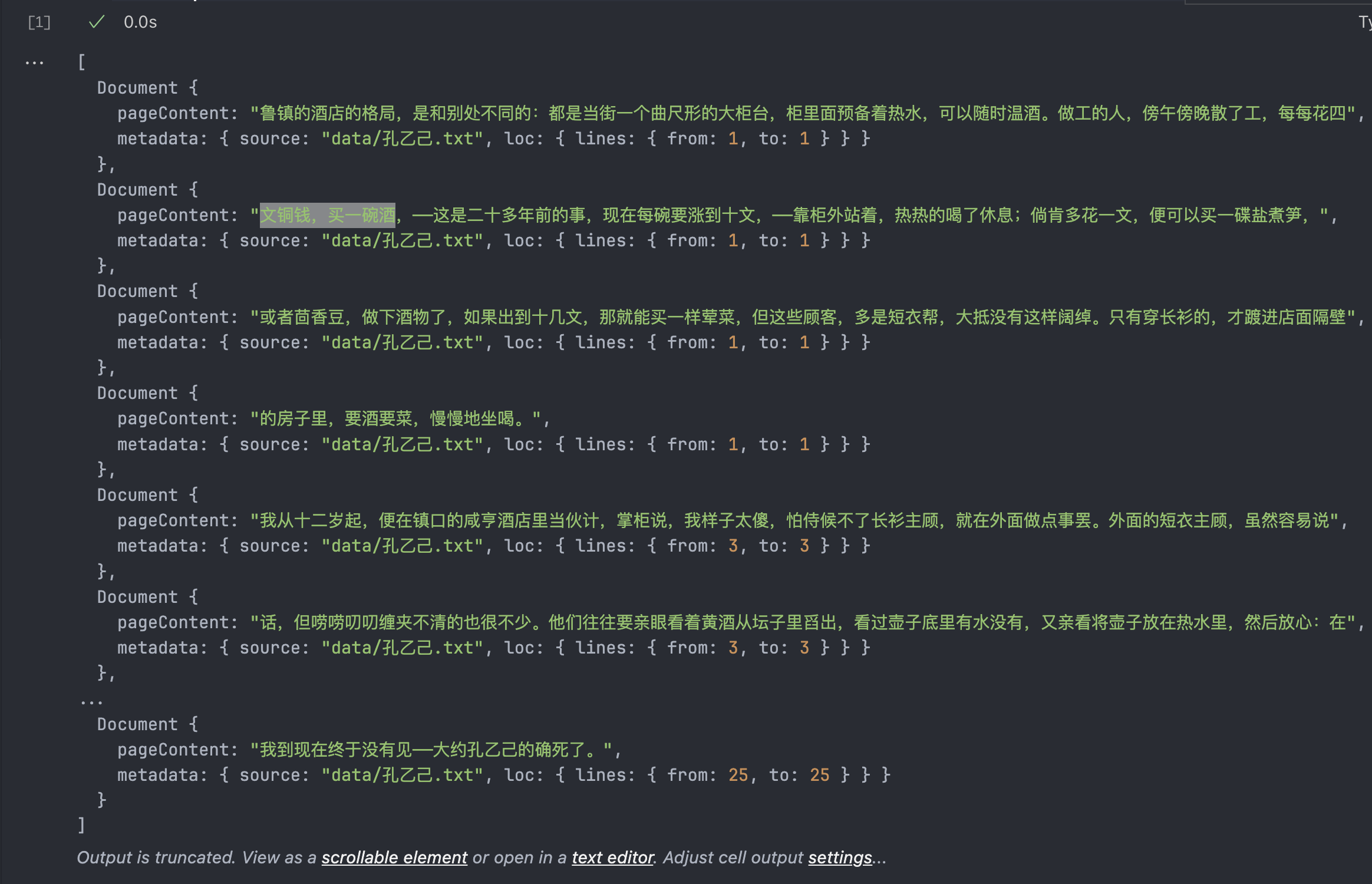
在原始数据里,一行就是一段,中间用的是空行进行分割,所有前几个Document的meta都是一样的从1到1。
实际代码上看不出什么名堂来,有一个网站可以可视化观察分割的效果:ChunkViz,让我们上传文件看看:

然后设置一下ChunkOverlap,文档之间的重叠是怎么设置和形成的: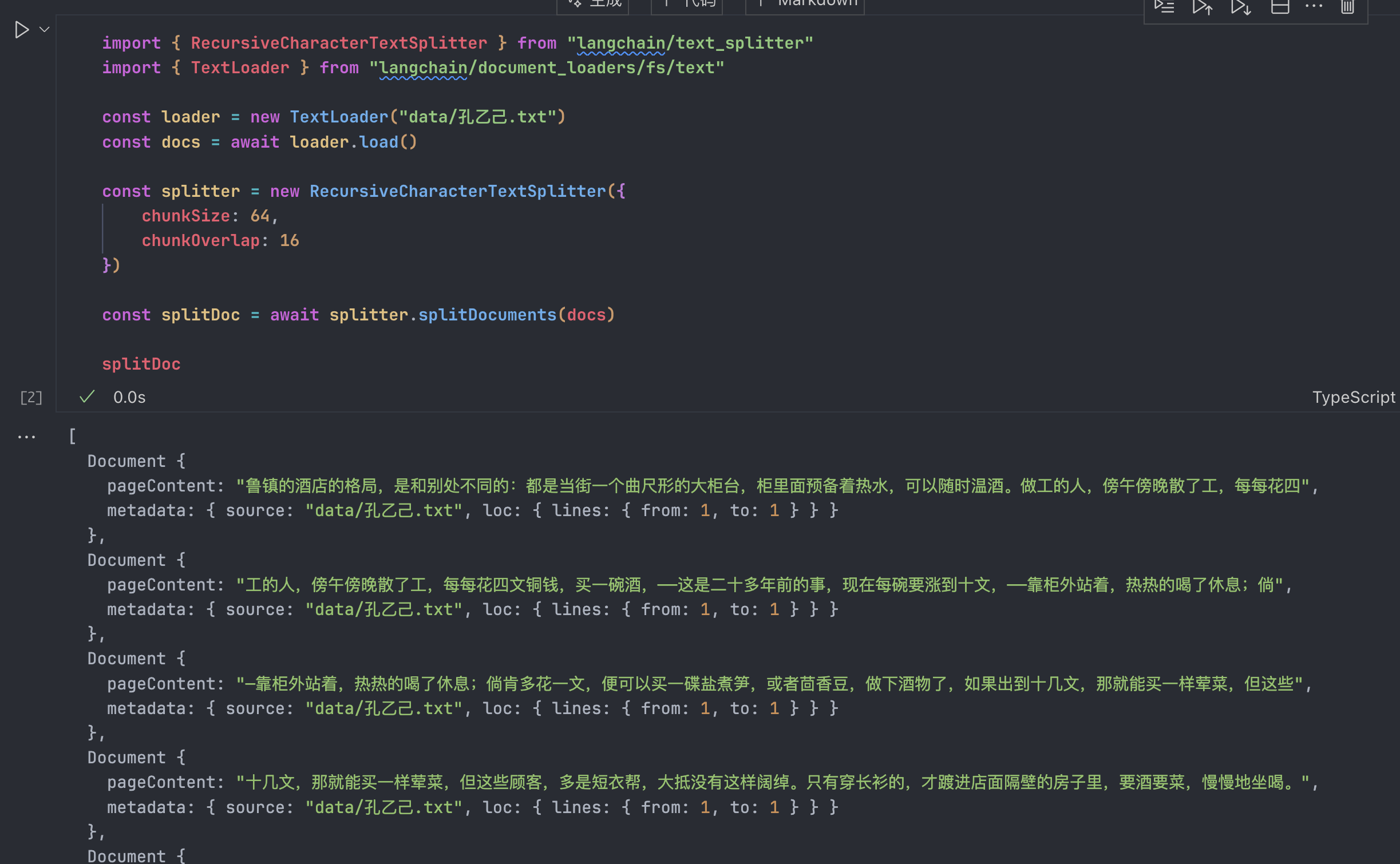
墨绿色的就是重叠部分了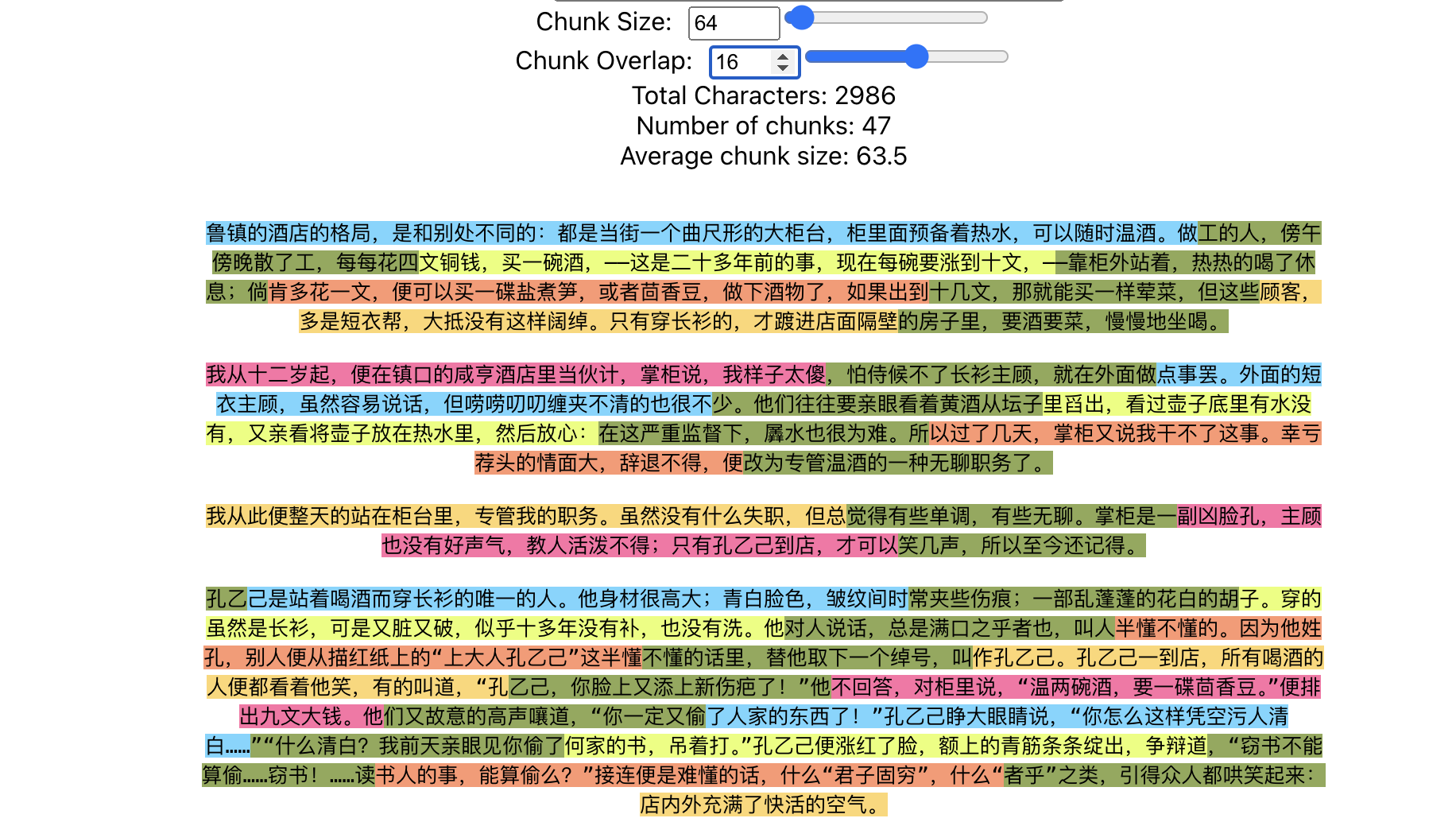
我大费周章的讲述这个方法,是因为这个方法是所有切分块的基础,理解了切分的行为模式之后,记住两个关键的参数,chunkSize和ChunkOverlap,在实现了完整的Chain之后,再回头来看切分函数是否影响了最终的质量,决定接下来是选择调整两个参数,还是选择其他的切分工具
我们的一般行为是:
- 对于这两个参数,先设定默认的1000和200,然后用刚刚的可视化网站检查部分结果是否符合预期
- 然后利用我们对于语义的理解,调整到一个合适的值
- 最后在Chain全部完成之后,根据最后结果的质量和生成过程中的log日志来看是哪部分影响了最终质量,再决定是否调整
- 因为自然语言的特殊性,在低成本方法里,其实是很难找到一个完美的参数值的,这是客观事实
CodeTextSplitter
因为LangChain支持的语言一直在变动,可以通过这个函数查询支持的语言
import { SupportedTextSplitterLanguages } from "langchain/text_splitter"
console.log(SupportedTextSplitterLanguages)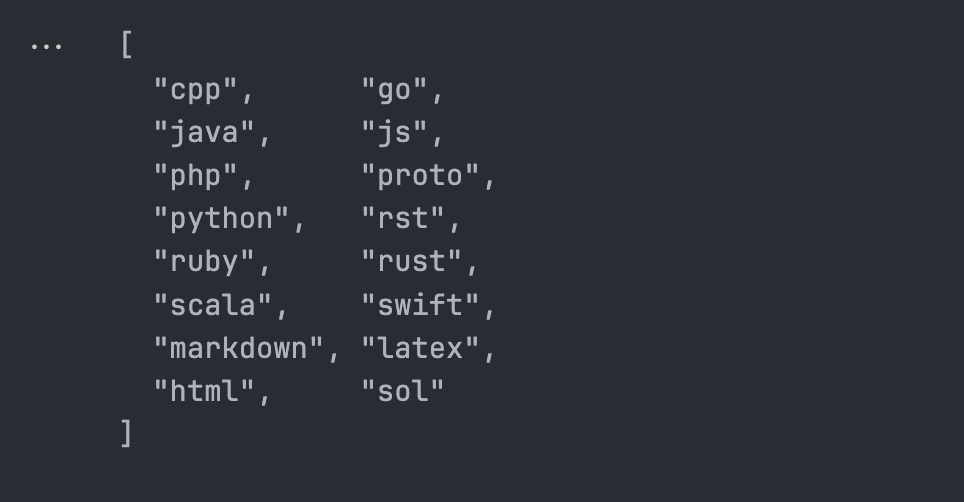
大多数常见的语言都在其中,我们用JS来作为例子看看切分的代码是什么效果:
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter"
import { TextLoader } from "langchain/document_loaders/fs/text"
const splitter = RecursiveCharacterTextSplitter.fromLanguage("js", {
chunkSize: 64,
chunkOverlap: 0
})
const loader = new TextLoader("./text.js")
const js = await loader.load()
const jsOutput = await splitter.createDocuments([js[0].pageContent])
jsOutput可以看到,对JS的分割本质上就是将js中常见的切分代码的特定字符传递给RecursiveCharacterTextSplitter,还是继续根据Recursive的逻辑进行切分,跟正常的text切分的逻辑是一样的。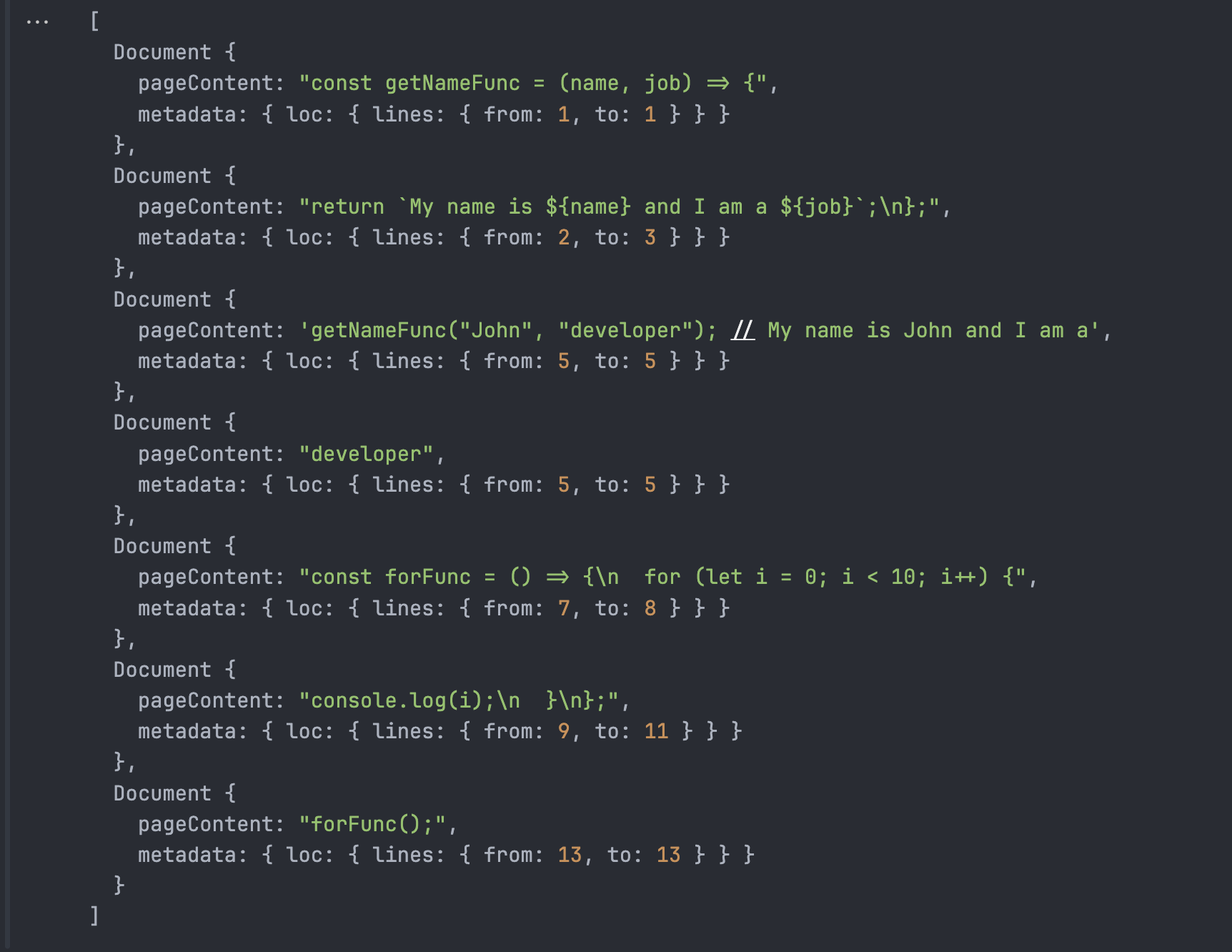
TokenTextSplitter
这个切分函数的使用场景并不多,因为切分的时候并不是根据各种符号来切分从而保持语义性的,而是根据Token的数量来进行切分,仅仅适合于Token敏感的场景,或者与其他的切分函数组合起来使用,其内部的chunkSize和chunkOverlap的逻辑和上面没有什么差别,这里我用两个方法分别打印结果出来看看具体差异在哪儿?
import { TokenTextSplitter, RecursiveCharacterTextSplitter } from "langchain/text_splitter"
const text = "This is a test sentence. This is another test sentence."
const tokenSplitter = new TokenTextSplitter({
chunkSize: 5,
chunkOverlap: 0
})
const recursiveSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 5,
chunkOverlap: 0
})
const tokenOutput = await tokenSplitter.createDocuments([text])
const recursiveOutput = await recursiveSplitter.createDocuments([text])
console.log('token:', tokenOutput)
console.log('recursive', recursiveOutput)token: [
Document {
pageContent: "This is a test sentence",
metadata: { loc: { lines: { from: 1, to: 1 } } }
},
Document {
pageContent: ". This is another test",
metadata: { loc: { lines: { from: 1, to: 1 } } }
},
Document {
pageContent: " sentence.",
metadata: { loc: { lines: { from: 1, to: 1 } } }
}
]
recursive [
Document {
pageContent: "This",
metadata: { loc: { lines: { from: 1, to: 1 } } }
},
Document {
pageContent: "is a",
metadata: { loc: { lines: { from: 1, to: 1 } } }
},
Document {
pageContent: "test",
metadata: { loc: { lines: { from: 1, to: 1 } } }
},
Document {
pageContent: "sent",
metadata: { loc: { lines: { from: 1, to: 1 } } }
},
Document {
pageContent: "ence.",
metadata: { loc: { lines: { from: 1, to: 1 } } }
},
Document {
pageContent: "This",
metadata: { loc: { lines: { from: 1, to: 1 } } }
},
Document {
pageContent: "is",
metadata: { loc: { lines: { from: 1, to: 1 } } }
},
Document {
pageContent: "anot",
metadata: { loc: { lines: { from: 1, to: 1 } } }
},
Document {
pageContent: "her",
metadata: { loc: { lines: { from: 1, to: 1 } } }
},
Document {
pageContent: "test",
metadata: { loc: { lines: { from: 1, to: 1 } } }
},
Document {
pageContent: "sent",
metadata: { loc: { lines: { from: 1, to: 1 } } }
},
Document {
pageContent: "ence.",
metadata: { loc: { lines: { from: 1, to: 1 } } }
}
]看出来了吧,token是严格按照限制来执行的。这里科普一下token的内容:
Token 是语言模型的最小处理单元:
- 对于英语,完整的单词(如 "apple")通常是一个 token。
- 短语标点(如 "isn't")可能被拆成多个 token:
["is", "n't"]。 - 中文通常每个汉字是一个 token,例如 "你好" 会被分解成两个 token:
["你", "好"]。
- 标记器(Tokenizer)负责将文本转化为 token 列表。
- 在
TokenTextSplitter中,chunkSize控制每个块中最多包含多少个 token。 - 比如例子里面的This is a test sentence. This is another test sentence. Token 化结果:
["This", "is", "a", "test", "sentence", ".", "This", "is", "another", "test", "sentence", "."]
Markdown/HTML Splitters
这个其实就不多说了,跟code是一样的,直接概括吧:
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter"
import { TextLoader } from "langchain/document_loaders/fs/text"
const mdSplitter = RecursiveCharacterTextSplitter.fromLanguage("markdown", {
chunkSize: 64,
chunkOverlap: 0
})
const htmlSplitter = RecursiveCharacterTextSplitter.fromLanguage("html", {
chunkSize: 64,
chunkOverlap: 0
})
const mdLoader = new TextLoader("./text.md")
const htmlLoader = new TextLoader("./text.html")
const md = await mdLoader.load()
const html = await htmlLoader.load()
const mdOutput = await mdSplitter.createDocuments([md[0].pageContent])
const htmlOutput = await htmlSplitter.createDocuments([html[0].pageContent])
console.log('md:', mdOutput)
console.log('html:', htmlOutput)几乎一样的返回结结构: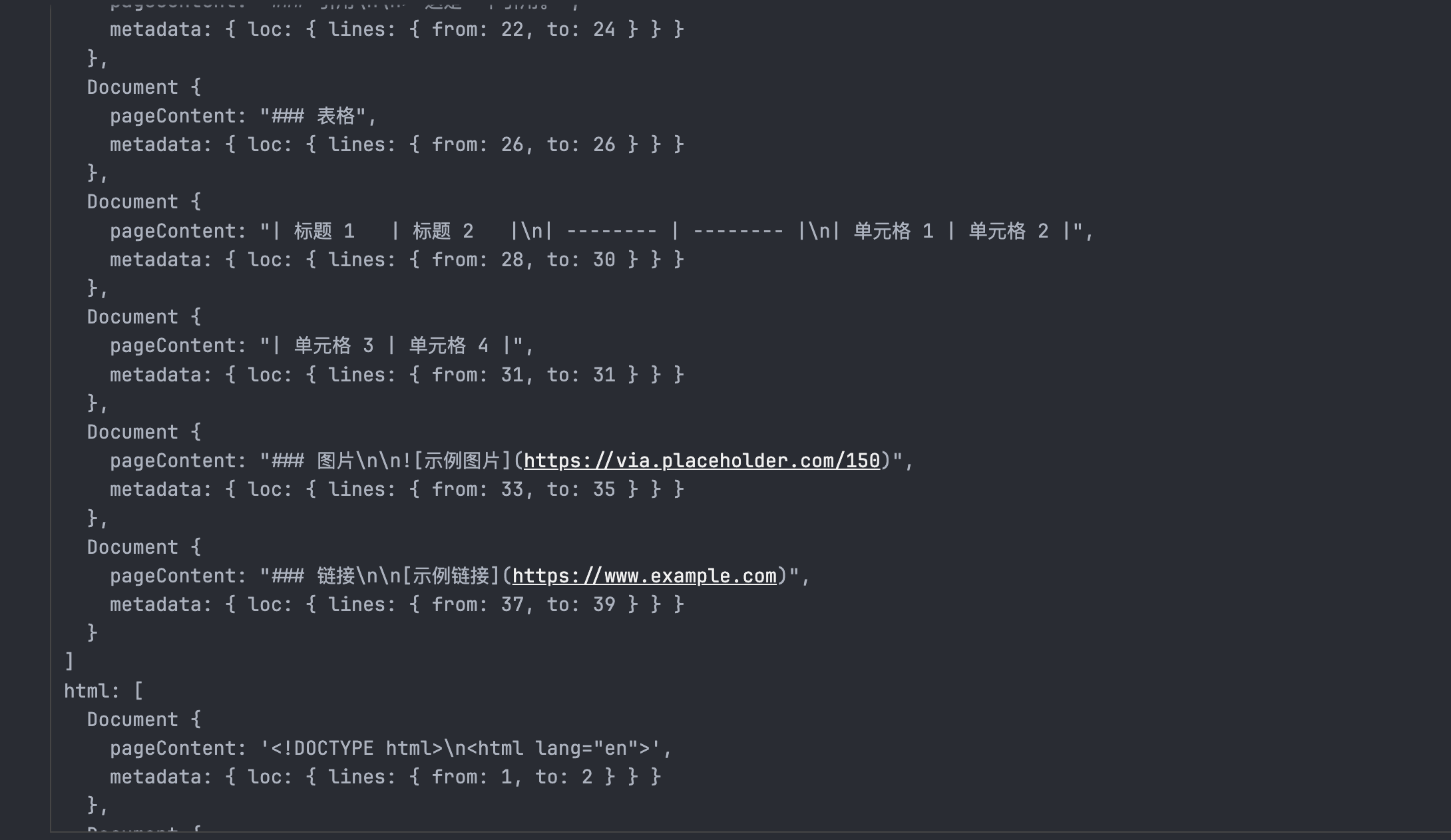
高成本
目前LangChainJS暂时没有实装这两个方法,不过Python版本已经实装了,我们在这里提一下,以后JS版本也实装了的话可以即开即用:
SemanticChunker
利用嵌入模型(如 OpenAI 的嵌入模型)计算句子之间的语义相似性,根据相似度确定切分点,将语义相关的内容聚合在一起。
- 语义连贯性:通过分析句子间的语义关系,确保切分后的文本块在内容上保持连贯,减少因机械切分导致的上下文断裂。
自适应性:无需手动设置 ChunkSize 和 ChunkOverlap,切分过程根据文本的语义结构自动调整,更加智能。
示例代码:from langchain_experimental.text_splitter import SemanticChunker from langchain_openai.embeddings import OpenAIEmbeddings # 初始化嵌入模型 embeddings = OpenAIEmbeddings() # 创建 SemanticChunker 实例 semantic_chunker = SemanticChunker(embeddings) # 分割文本 documents = semantic_chunker.create_documents([your_text])这个切分器的成本集中在下面这些内容:
嵌入模型的调用成本
- SemanticChunker 使用嵌入模型(如 OpenAI 的 text-embedding-ada-002)计算文本的语义嵌入。
- 每次生成嵌入都会消耗 API 调用额度或付费,具体费用取决于使用的模型和提供商(如 OpenAI)。
- 以 OpenAI 的嵌入 API 为例,text-embedding-ada-002 每 1000 tokens 大约花费 $0.0004。
对于大规模文本或批量任务,调用嵌入模型可能带来较高的费用。
AI21SemanticTextSplitter
借助 AI21 的语义分析 API,对文本进行深度语义理解,根据内容的语义结构智能地确定切分点。
- 深度语义理解:利用 AI21 强大的语义分析能力,确保切分后的文本块在主题和内容上具有高度一致性。
减少人工调整:通过自动化的语义切分,降低对 ChunkSize 和 ChunkOverlap 等参数的依赖,减少人工调整的复杂性。
from langchain_ai21 import AI21SemanticTextSplitter # 设置 AI21 API 密钥 import os os.environ["AI21_API_KEY"] = 'your_api_key' # 创建 AI21SemanticTextSplitter 实例 semantic_text_splitter = AI21SemanticTextSplitter() # 分割文本 chunks = semantic_text_splitter.split_text(your_text)更多详细的内容可以参考这里
这个切分器的成本则主要是依赖 AI21 API
API 调用成本:
- AI21SemanticTextSplitter 需要调用 AI21 的 API 来进行语义分析和文本切分。
- AI21 提供的 API 是按调用量或生成内容的 token 数量计费的,具体费用可以在 AI21 Labs 的官网 查询。
- 每次 API 调用都需要消耗额度,这对大规模文本处理可能带来显著成本。
额外的网络延迟:
- 由于需要通过 API 请求进行处理,处理时间可能受到网络延迟影响。
总结
总的来说,大规模数据的预处理主要的逻辑就是把长文档分成长度合适,语义相关的模块,在控制成本的场景中,最重要的是理解chunkSize和ChunkOverlap。