之前讲解RAG的本质的时候提到过数据加载,实际上就是给Chat Bot外挂数个数据源,考虑到各种应用场景,数据源的形式也就是多种多样了。比如说:文件、网络数据、数据库、代码等等。
所以说,LangChain提供了一系列的loader来帮助开发者处理不同数据源的数据
Document对象
这个东西你可以简单理解成LangChain对于所有类型的数据的一个统一的抽象,其中有两个属性:
pageContent:文本内容,就是文档对象对应的文本数据metadata:元数据,文本数据对应的元数据,比如说 原始文档的标题,页数等信息,可以用于后面构建的向量数据库基于此进行筛选
它的Typescript的interface是这样的:

这个内容一般来说是由各种Loader自动创建的,我们也可以手动创建看看结果: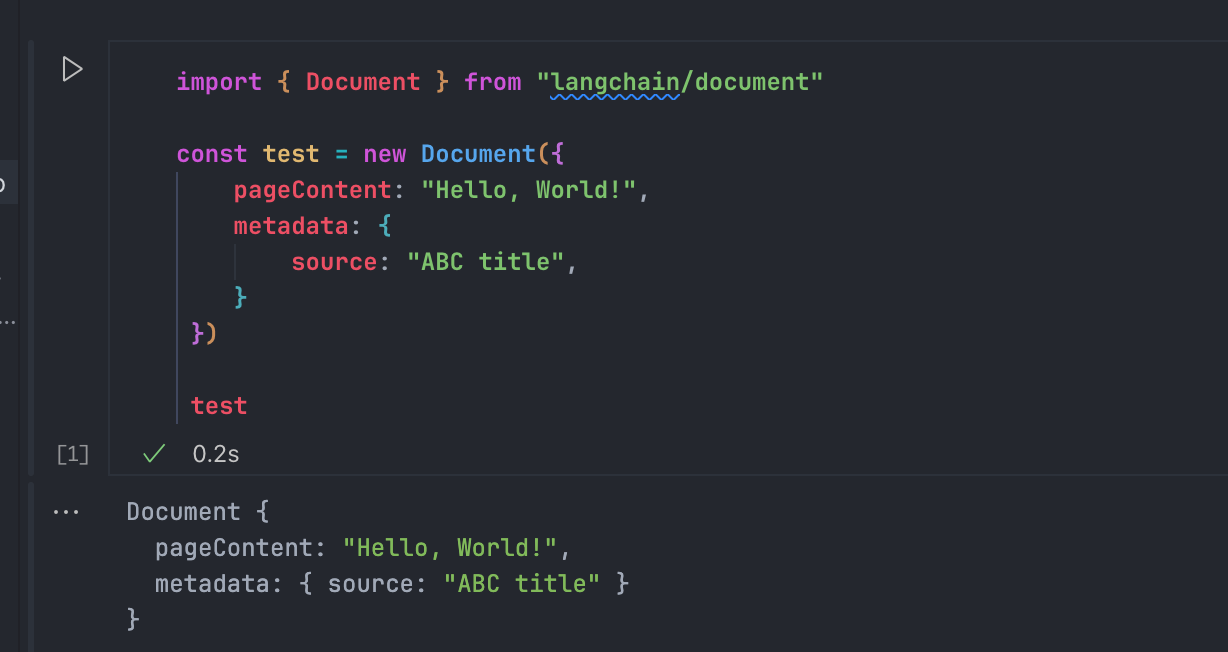
Loader
处理数据的第一步骤就是加载数据,正常来说,我们需要为目标的数据格式来寻找合适的库和编写加载的代码(比如JSON,CSV)这一类数据,但是当我们有了LangChain之后,内置了很多的数据文件的读取支持。下面来举几个例子
TextLoader
首先是最简单的TextLoader
import { TextLoader } from "langchain/document_loaders/fs/text"
const loader = new TextLoader("data/孔乙己.txt");
const docs = await loader.load();
docs输出的内容:
如同上面介绍Document对象一样,这个内容也是一样的,包含了pageContent和metadata。一个是文本原文,一个是元数据,在这里就是加载原始文件的文件名。
PDFLoader
PDF是一种非常常见的数据来源,很多chatbot都支持用户上传pdf作为外挂的数据库,从而让聊天的主题内容围绕着某个pdf周围。
但是在Deno的环境下,因为找不到pdf-parser这个依赖,不支持Deno环境,所以我们需要手动加入一下:
"pdf-parse": "npm:/pdf-parse/lib/pdf-parse.js"在deno.json中加入,并且install一下,让依赖缓存重新加载
import * as pdfParser from "pdf-parse"
import { PDFLoader } from "langchain/document_loaders/fs/pdf";
const loader = new PDFLoader("data/llm.pdf");
const pdfs = await loader.load()
pdfs打印出来的Document数组,每一个对象都对应了PDF里面的一页,这是PDFLoader的默认行为。可以配置关闭这个特性:
const loader = new PDFLoader("data/llm.pdf", { splitPages: false });这个时候打印出来的是一个不分页的单个对象: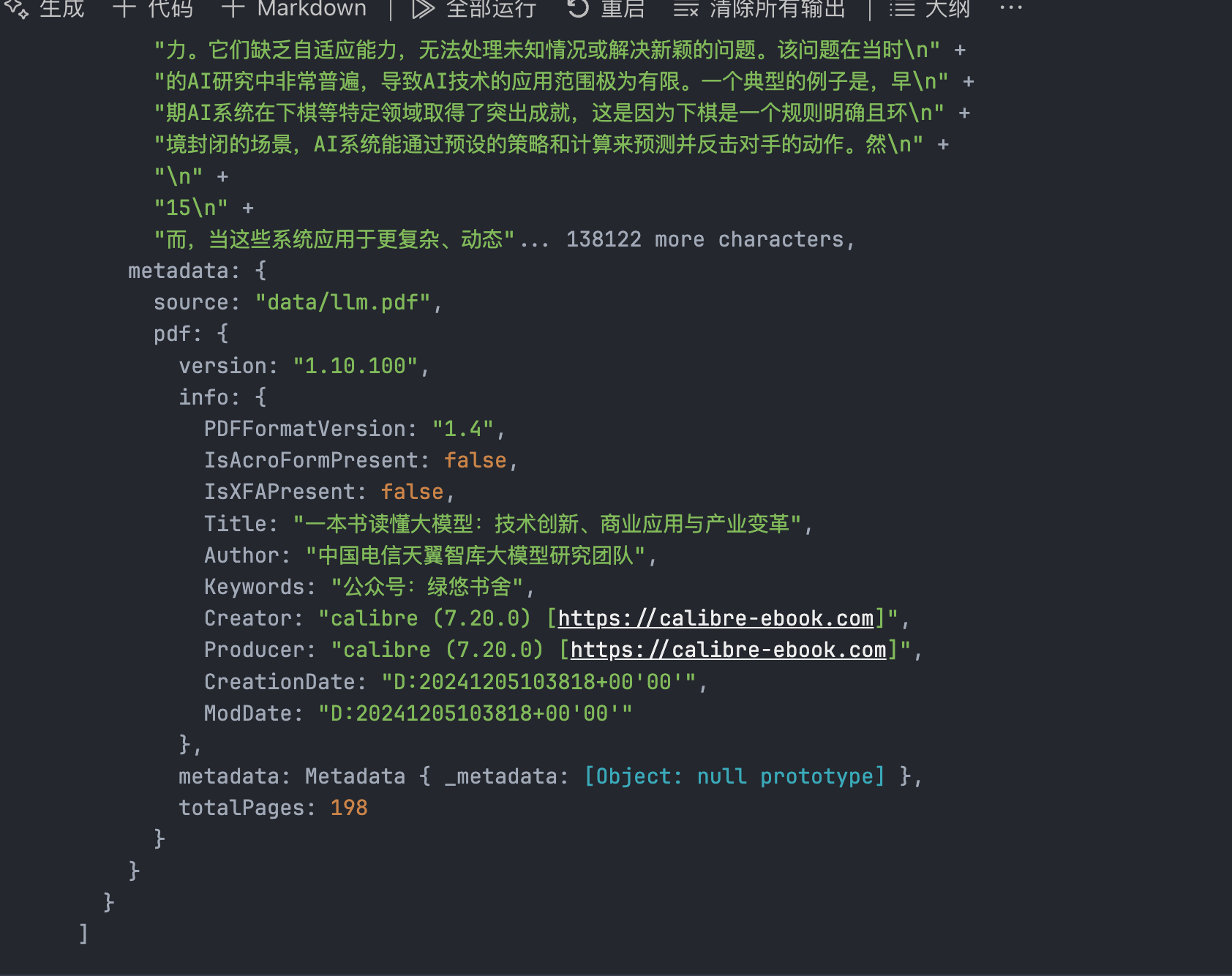
这里面咱们可以清晰地看到,metadata的内容更加的丰富了,包含了从PDF读取到的一系列信息,能够帮我们后续对Document对象做出一些处理
DirectoryLoader
当我们需要加载一个文件夹下面多个格式的文件,就可以使用DirectoryLoader,我们需要预先定义对该文件夹不同文件类型的Loader。
import { DirectoryLoader } from "langchain/document_loaders/fs/directory"
const loader = new DirectoryLoader(
"./data",
{
".pdf": (path) => new PDFLoader(path, { splitPages: false }),
".txt": (path) => new TextLoader(path)
}
);
const docs = await loader.load();
docs如此这样就可以直接批处理你指定的文件夹下面的所有的数据文件,有多少种文件就可以加入多少种Loader。到时候返回的也是一个由Document对象组成的数组。
如此这般,可以看到,在LangChain里,各种繁琐的文件都被规范化处理了,我们需要做的只有按照需求去寻找相应的Loader即可
Web Loader
上面主要讲的是从文件里加载数据,而对于一个chat bot的应用来说,比较重要的数据源也包含了网络数据,比方说最近出的chatgpt 4o网络搜索,根据需求去互联网爬取的数据,然后根据上下文做回答
Github Loader
基于 某个开源项目构建数据库,根据用户的提问寻找与此相关的代码片段,并且回答用户的问题,这是开发过程中最想要的工具了。现在我们可以让LLM去寻找和理解某个开源项目的源代码,速度比我们人快很多
import { GithubRepoLoader } from "langchain/document_loaders/web/github"
import ignore from "ignore"
const loader = new GithubRepoLoader(
"https://github.com/ArisaTaki/Shader-Template",
{
branch: "main",
recursive: false,
unknown: "warn",
ignorePaths: ["*.md", "*.json"],
// accessToken: env['GITHUB_ACCESS_TOKEN'],
}
)
const repo = await loader.load();
repo注意,这里需要加一个新的包ignore,它是一个工具性依赖,帮助 GitHubRepoLoader 更加高效和灵活地处理文件加载任务。
添加
"ignore": "npm:/ignore"到deno.json,重新install一下就行。
我来解释一下这些参数都是什么:
branch:爬取的代码仓库的目标分支recursive:是否递归访问文件夹内部的内容,如果这里是为了测试效果的话建议关闭,请求量会很大。ignorePaths:使用的是git ignore的语法,忽略掉一些特定格式的文件,这里我是把项目比较大的json和说明文件md忽略了accessToken:是github API的accessToken,如果没有设置,也是可以访问的,但是有频率的限制,怎么获取可以参考这里
来分析一下这个方法的返回: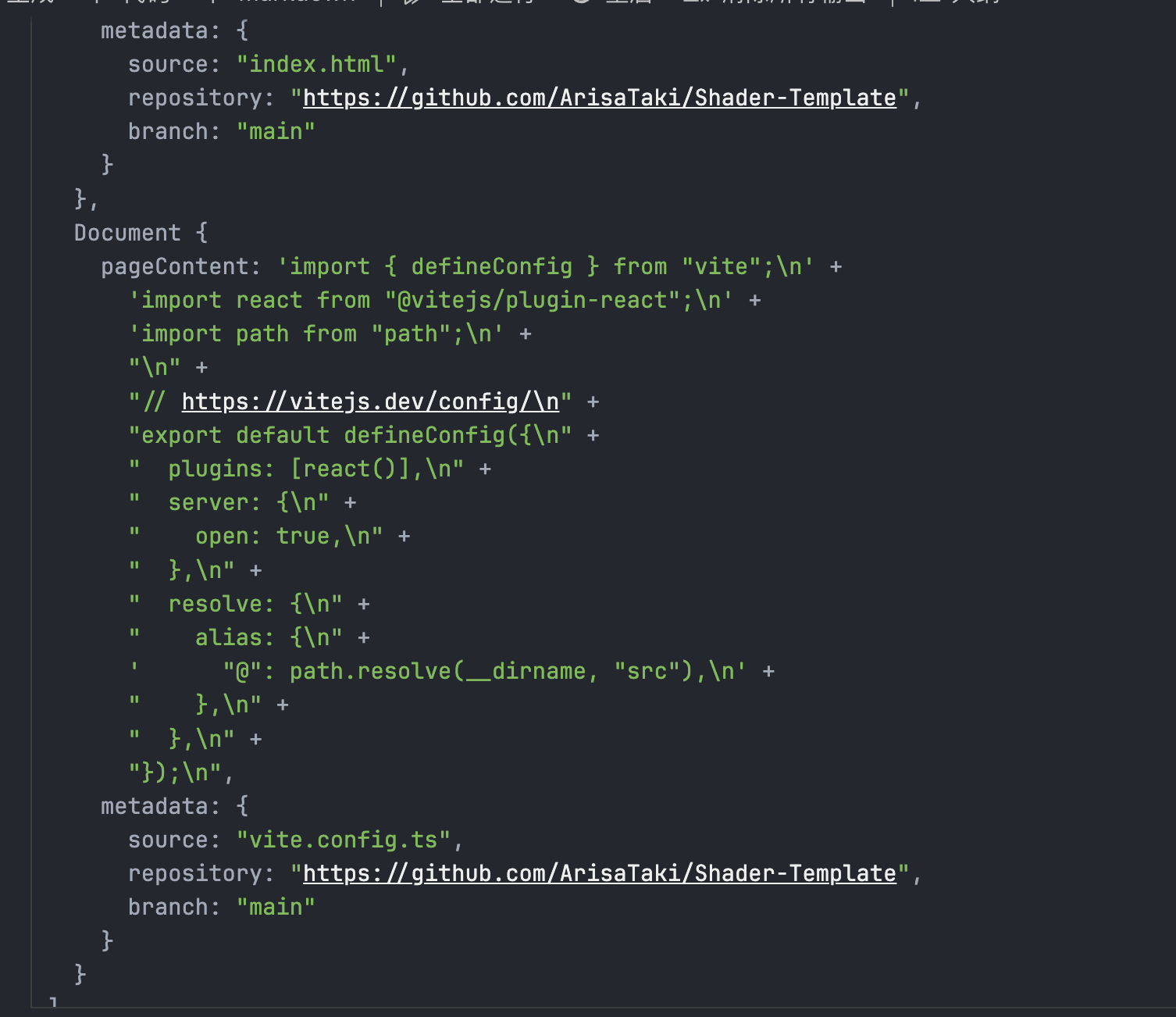
这个Loader会在爬取的时候自行记录下相关的metadata,方便后续的调用,在这张图里可以看到文件名,仓库地址,还有分支。
CheerioWebBaseLoader
对于LLM而言所需要提取的信息是网页中的信息时,一般使用Cheerio提取与处理HTML内容,有点类似于python里的BeautifulSoup。这两个都针对于静态的HTML,无法运行JS,但是这样能提取HTML内容的已经能够应对绝大多数的场景了
import "cheerio"
import { CheerioWebBaseLoader } from "langchain/document_loaders/web/cheerio"
const loader = new CheerioWebBaseLoader("https://blog.fufubest.com/index.php/archives/526/")
const docs = await loader.load();
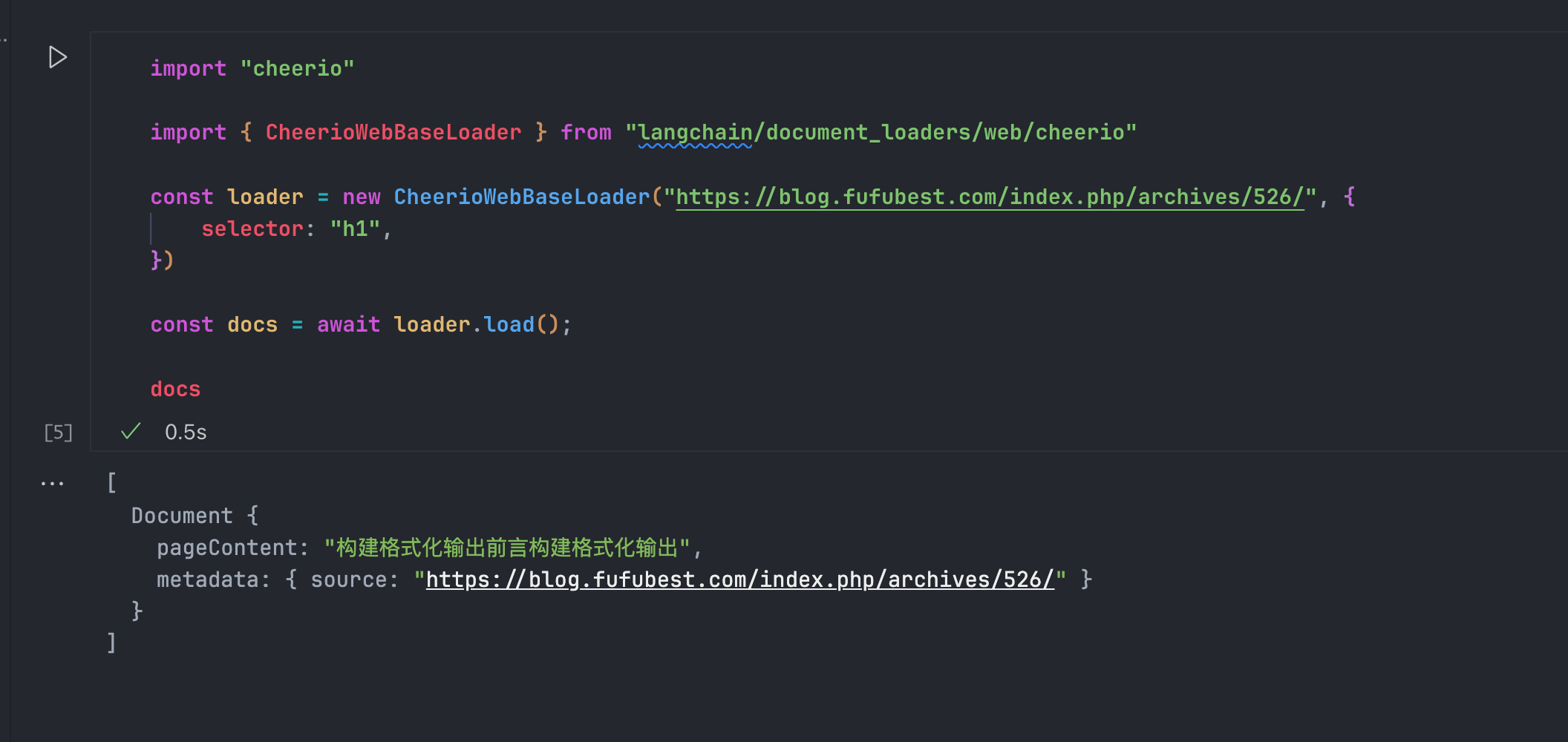
docs打印出来的效果很明显地能看出来是纯文本,我们看不到HTML标签: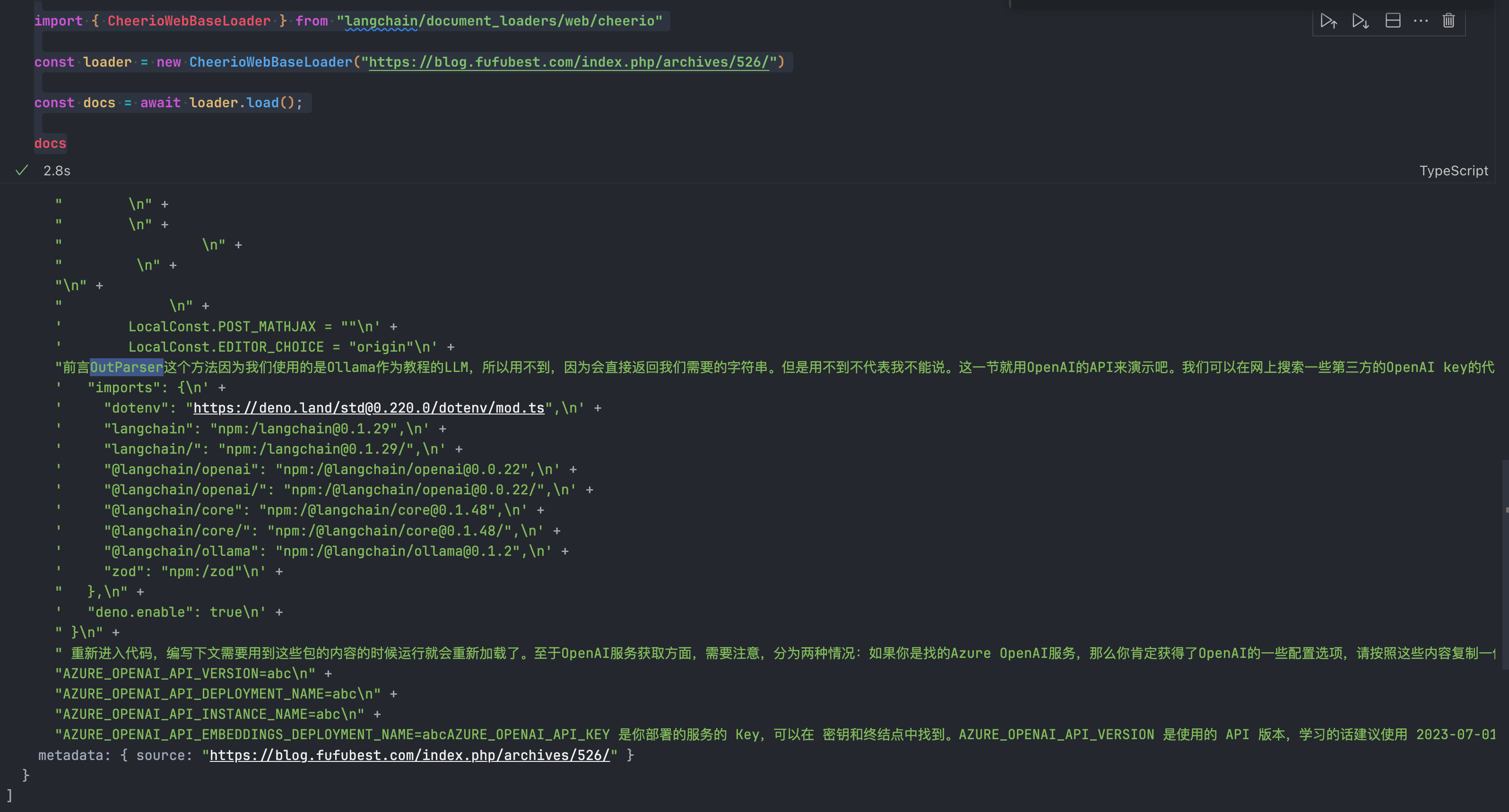
当然,我们也可以对HTML里面的元素进行选择和过滤:
const loader = new CheerioWebBaseLoader("https://blog.fufubest.com/index.php/archives/526/", {
selector: "h1",
})
Search API
如果要给chat Bot接入网络支持,那么这个API就是最重要的API。对于LangChainJS来说,最常用的就是SearchApiLoader和SerpAPILoader。这两个都是给提供的接入搜索的能力,免费计划都是每个月100次检索的能力,支持Google,Baidu,bing等常用引擎。我们取一个来试试:SerpAPILoader
咱们先去官方网站上注册一个免费计划:
在这里看你的API Key:
然后在你的.env文件里写上你的API Key,随后写下代码:
import { load } from "dotenv"
import { SerpAPILoader } from "langchain/document_loaders/web/serpapi"
const env = await load()
const process = {
env
}
const apiKey = process.env.SERP_API_KEY
const question = "什么是LLM?"
const loader = new SerpAPILoader({ q: question, apiKey });
const docs = await loader.load();
docs结果显示如下: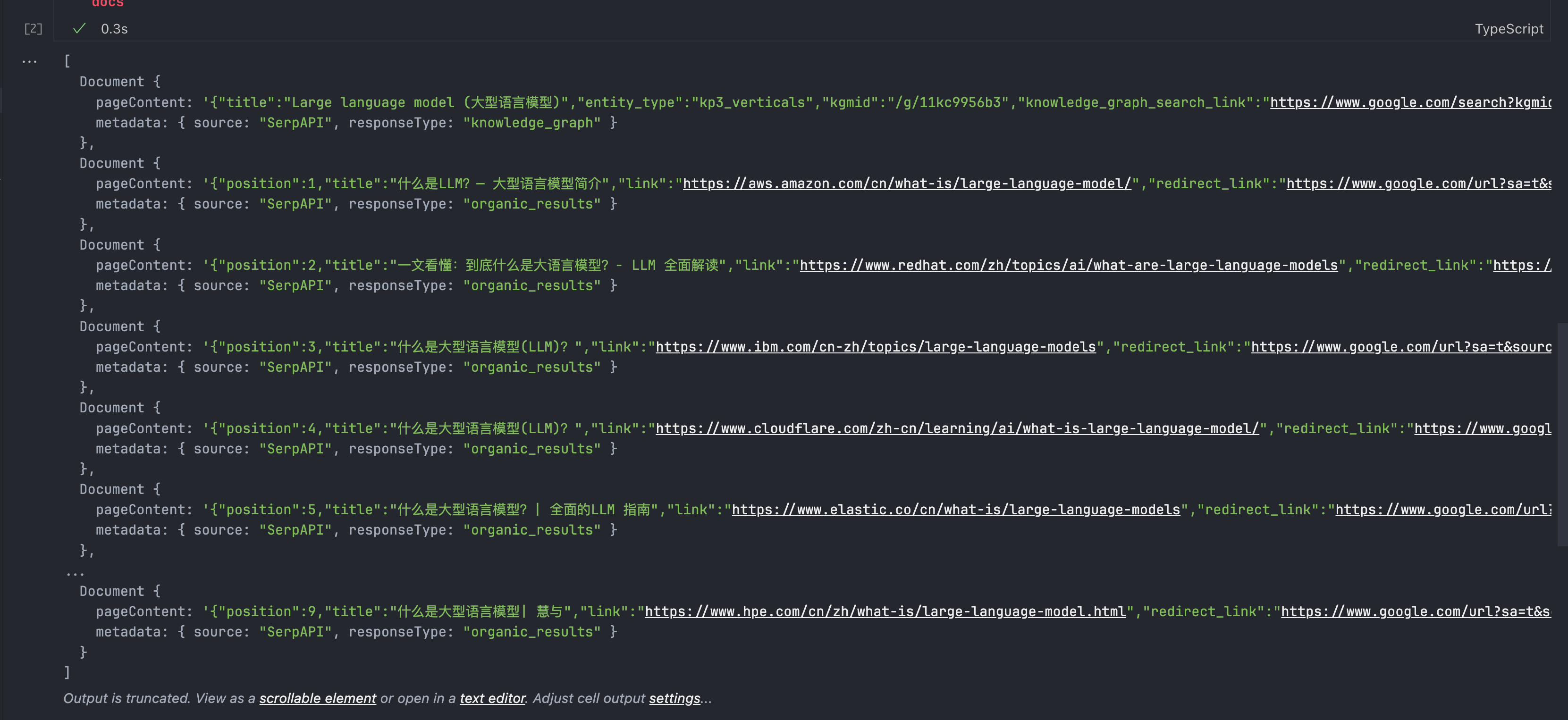
serp真的是非常强大的工具,不只是返回了Google的结果,会爬取每个结果的汇总和信息放在pageContent上面,搭配LangChain的对应集成,提供了开箱即用的接入了Google搜索和爬取内容的能力。也就是,给了chat Bot联网搜索的能力!
Loader不止这篇文章介绍的这么点,我只是取了几个有代表性的文章来说道说道,社区正在逐步发展,可以多关注LangChain的社区,说不定哪天也有你想要的,需要的Loader出现呢。