前言
OutParser这个方法因为我们使用的是Ollama作为教程的LLM,所以用不到,因为会直接返回我们需要的字符串。
但是用不到不代表我不能说。这一节就用OpenAI的API来演示吧。我们可以在网上搜索一些第三方的OpenAI key的代理,来使用chatgpt,或者你可以自行搜索Azure OpenAI(这是一个与openAI同源的服务,可以白嫖一些额度)
所以我们要更新一下Deno.json的内容:
{
"imports": {
"dotenv": "https://deno.land/std@0.220.0/dotenv/mod.ts",
"langchain": "npm:/langchain@0.1.29",
"langchain/": "npm:/langchain@0.1.29/",
"@langchain/openai": "npm:/@langchain/openai@0.0.22",
"@langchain/openai/": "npm:/@langchain/openai@0.0.22/",
"@langchain/core": "npm:/@langchain/core@0.1.48",
"@langchain/core/": "npm:/@langchain/core@0.1.48/",
"@langchain/ollama": "npm:/@langchain/ollama@0.1.2",
"zod": "npm:/zod"
},
"deno.enable": true
}
重新进入代码,编写下文需要用到这些包的内容的时候运行就会重新加载了。
至于OpenAI服务获取方面,需要注意,分为两种情况:
如果你是找的Azure OpenAI服务,那么你肯定获得了OpenAI的一些配置选项,请按照这些内容复制一份到你的.env文件中:
AZURE_OPENAI_API_KEY=abc AZURE_OPENAI_API_VERSION=abc AZURE_OPENAI_API_DEPLOYMENT_NAME=abc AZURE_OPENAI_API_INSTANCE_NAME=abc AZURE_OPENAI_API_EMBEDDINGS_DEPLOYMENT_NAME=abc- AZURE_OPENAI_API_KEY 是你部署的服务的 Key,可以在 密钥和终结点中找到。
- AZURE_OPENAI_API_VERSION 是使用的 API 版本,学习的话建议使用
2023-07-01-preview。 - AZURE_OPENAI_API_DEPLOYMENT_NAME 是你部署的模型实例的名称
- AZURE_OPENAI_API_INSTANCE_NAME 是你部署服务的名称
- AZURE_OPENAI_API_EMBEDDINGS_DEPLOYMENT_NAME 是你用于 embedding 的模型实例名称。创建步骤跟创建模型实例的部署一致。
如果你跟我一样是走的第三方的API转发服务,那么,就相对来说比较无脑的配置就行了:
OPENAI_API_URL=你的第三方转发服务的baseurl OPENAI_API_KEY=你的API key然后在代码里这样写:
const model = new ChatOpenAI({
configuration: {
baseURL: process.env.OPENAI_API_URL,
}
})ChatOpenAI实例会自动去检测你的env里有没有APIKey,然后自动填入到请求头里,很方便,直接访问检查一下:
输出正常,且内容就是这种AIMessage,是人类无法读取的。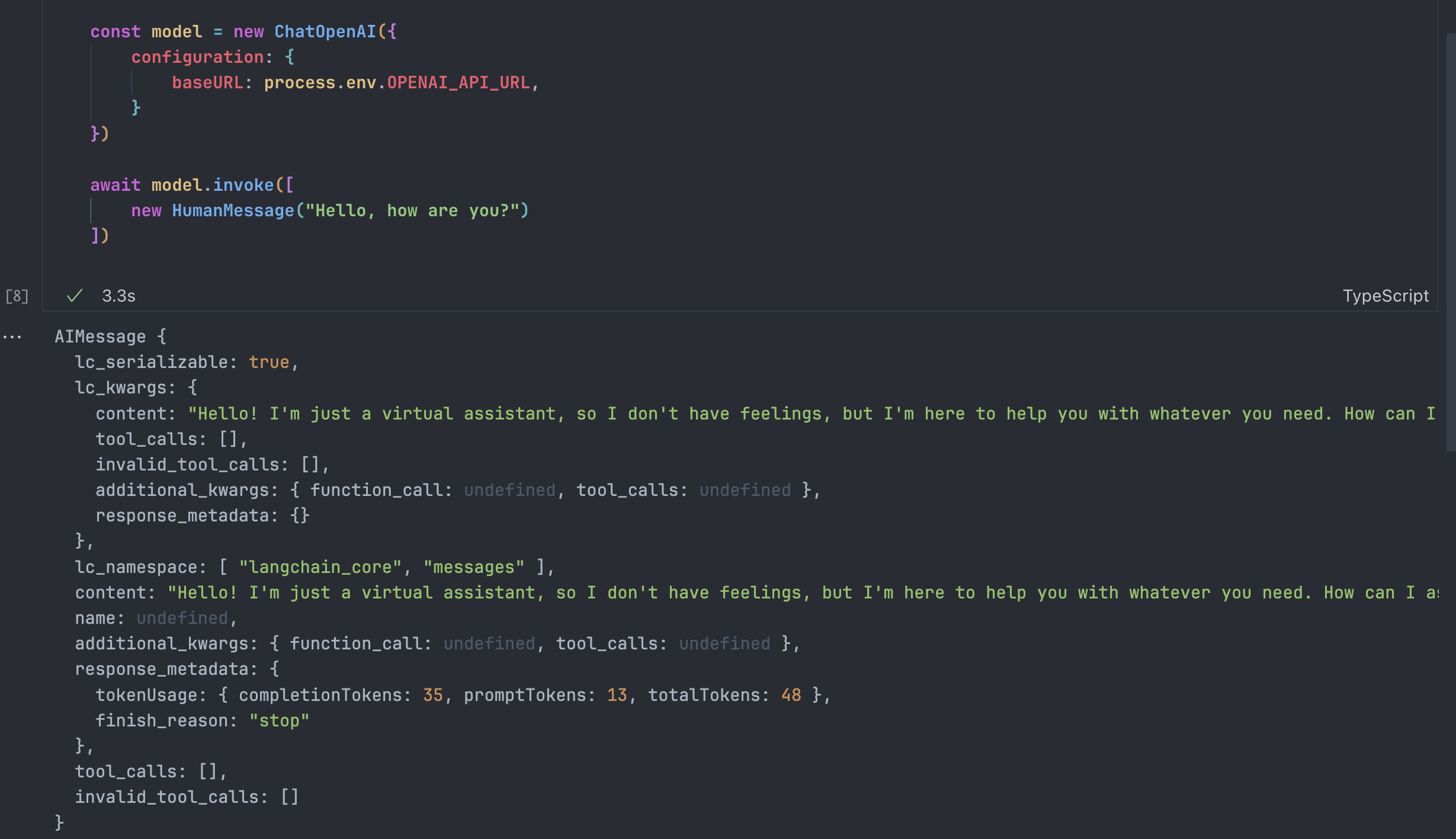
那么我们就可以进入正题了,我们的目的是构建格式化输出
这样的数据我们是没有办法直接发送给用户的,但是这个代码显然是可以处理的,但是我们每次都要写代码去提取content的话有点太麻烦了,这里我们就要用到OutputParser,LangChain封装了一系列解析大模型的API返回结果的工具,当然,这个工具也可以制定LLM的格式
String Output Parser
接着上面的代码,我们只需要大模型的文本输出,就可以通过StringOutputParser方法来获取其中的内容:
import { load } from "dotenv"
import { HumanMessage } from "@langchain/core/messages"
import { ChatOpenAI } from "@langchain/openai"
import { StringOutputParser } from "@langchain/core/output_parsers";
const env = await load();
const process = {
env
}
const model = new ChatOpenAI({
configuration: {
baseURL: process.env.OPENAI_API_URL,
}
})
const parser = new StringOutputParser()
const chain = model.pipe(parser)
await chain.invoke([
new HumanMessage("Hello, how are you?")
])

这样就可以得到文本数据了,对比直接解析,LangChain内部会有错误处理和Stream之类的支持。
StructuredOutputParser
Output Parser的另一个意义就是引导模型用你想要的格式进行输出,有一些Parser会提前内置一些设计好的Prompt来对模型进行引导:
import { StructuredOutputParser } from "@langchain/core/output_parsers"
const parser = StructuredOutputParser.fromNamesAndDescriptions({
answer: "用户问题的回答答案",
evidence: "你回答用户问题所依赖的答案",
confidence: "你对回答的信心",
})
console.log(parser.getFormatInstructions())这里打印出来的内容是:
You must format your output as a JSON value that adheres to a given "JSON Schema" instance.
"JSON Schema" is a declarative language that allows you to annotate and validate JSON documents.
For example, the example "JSON Schema" instance {{"properties": {{"foo": {{"description": "a list of test words", "type": "array", "items": {{"type": "string"}}}}}}, "required": ["foo"]}}}}
would match an object with one required property, "foo". The "type" property specifies "foo" must be an "array", and the "description" property semantically describes it as "a list of test words". The items within "foo" must be strings.
Thus, the object {{"foo": ["bar", "baz"]}} is a well-formatted instance of this example "JSON Schema". The object {{"properties": {{"foo": ["bar", "baz"]}}}} is not well-formatted.
Your output will be parsed and type-checked according to the provided schema instance, so make sure all fields in your output match the schema exactly and there are no trailing commas!
Here is the JSON Schema instance your output must adhere to. Include the enclosing markdown codeblock:{"type":"object","properties":{"answer":{"type":"string","description":"用户问题的回答答案"},"evidence":{"type":"string","description":"你回答用户问题所依赖的答案"},"confidence":{"type":"string","description":"你对回答的信心"}},"required":["answer","evidence","confidence"],"additionalProperties":false,"$schema":"http://json-schema.org/draft-07/schema#"}OK,让我们来逐步分析这个指令:
先告诉LLM输出的类型
You must format your output as a JSON value that adheres to a given "JSON Schema" instance.使用few-shot(小样本学习),用实例来告诉LLM什么是JSON Schema,什么情况下会被 解析成功,什么情况下不会成功
For example, the example "JSON Schema" instance {{"properties": {{"foo": {{"description": "a list of test words", "type": "array", "items": {{"type": "string"}}}}}}, "required": ["foo"]}}}} would match an object with one required property, "foo". The "type" property specifies "foo" must be an "array", and the "description" property semantically describes it as "a list of test words". The items within "foo" must be strings. Thus, the object {{"foo": ["bar", "baz"]}} is a well-formatted instance of this example "JSON Schema". The object {{"properties": {{"foo": ["bar", "baz"]}}}} is not well-formatted.随后再一次强调了类型的重要性,输出必须要遵循给定的JSON Scheme实例,确保所有的字段严格匹配Schema的定义,不应该有额外的属性,没有遗漏的必须属性。并且再次强调注意细节,比如不要在JSON对象里添加额外的逗号,这些都会导致解析失败。
这些Prompt的质量非常的高,把该任务里的大模型容易出现的问题全部进行了强调,有效地保障了输出的质量Your output will be parsed and type-checked according to the provided schema instance, so make sure all fields in your output match the schema exactly and there are no trailing commas!最后才是,说明我们制定的JSON格式和对应的描述
Here is the JSON Schema instance your output must adhere to. Include the enclosing markdown codeblock:{"type":"object","properties":{"answer":{"type":"string","description":"用户问题的回答答案"},"evidence":{"type":"string","description":"你回答用户问题所依赖的答案"},"confidence":{"type":"string","description":"你对回答的信心"}},"required":["answer","evidence","confidence"],"additionalProperties":false,"$schema":"http://json-schema.org/draft-07/schema#"}
通过这样较为复杂的操作,就可以保证大模型用指定的格式输出,我们来试试完成的运行一下:
import { load } from "dotenv"
import { ChatOpenAI } from "@langchain/openai"
import { StructuredOutputParser } from "@langchain/core/output_parsers"
import { PromptTemplate } from "@langchain/core/prompts"
const env = await load();
const process = {
env
}
const model = new ChatOpenAI({
configuration: {
baseURL: process.env.OPENAI_API_URL,
}
})
const parser = StructuredOutputParser.fromNamesAndDescriptions({
answer: "用户问题的回答答案",
evidence: "你回答用户问题所依赖的答案",
confidence: "你对回答的信心",
})
const prompt = PromptTemplate.fromTemplate("尽可能地回答用户的问题 \n{instructions}\n{question}")
const chain = prompt.pipe(model).pipe(parser)
const res = await chain.invoke({
question: "你好,请为我介绍日本东映公司的历史",
instructions: parser.getFormatInstructions()
})
console.log(res)输出结果是: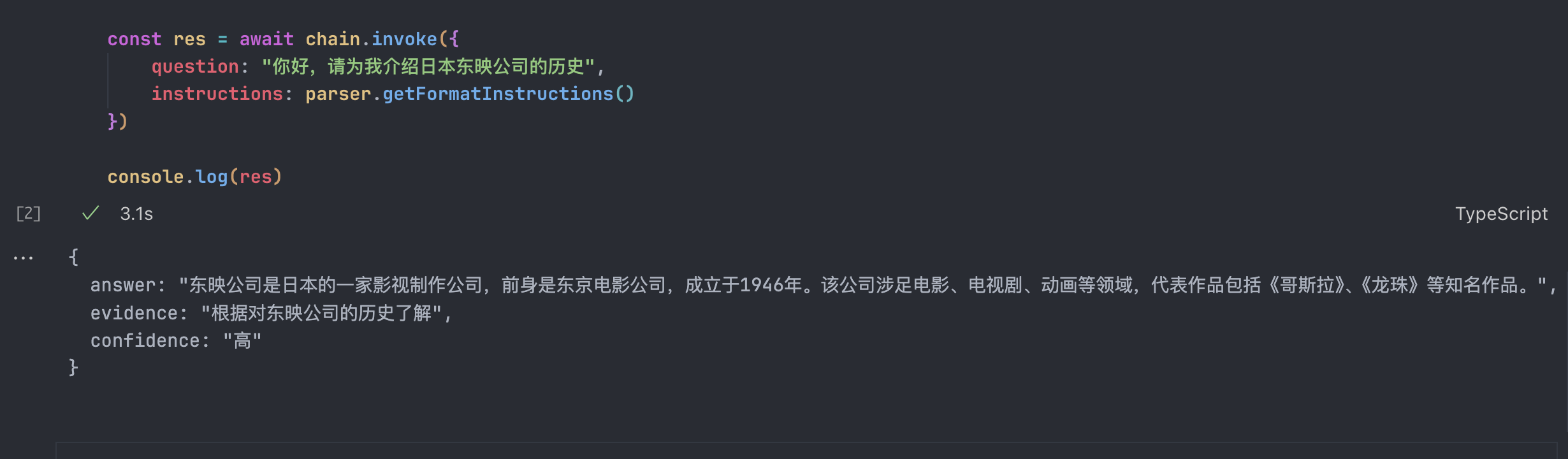
如此这般,我们就完成了强制大模型按照我们的需要和格式进行输出的output parser,说明parser不仅仅可以对大模型的输出进行处理,也有引导大模型按照对给定格式输出的能力,并且还内置了一些错误处理的能力,让部署在生产环境的难度降低。
列表类Output parser
上面的结构化parser反而比较复杂,这里还有一个比较简单的parser,也可以引导大模型输出,并且这个要简单很多
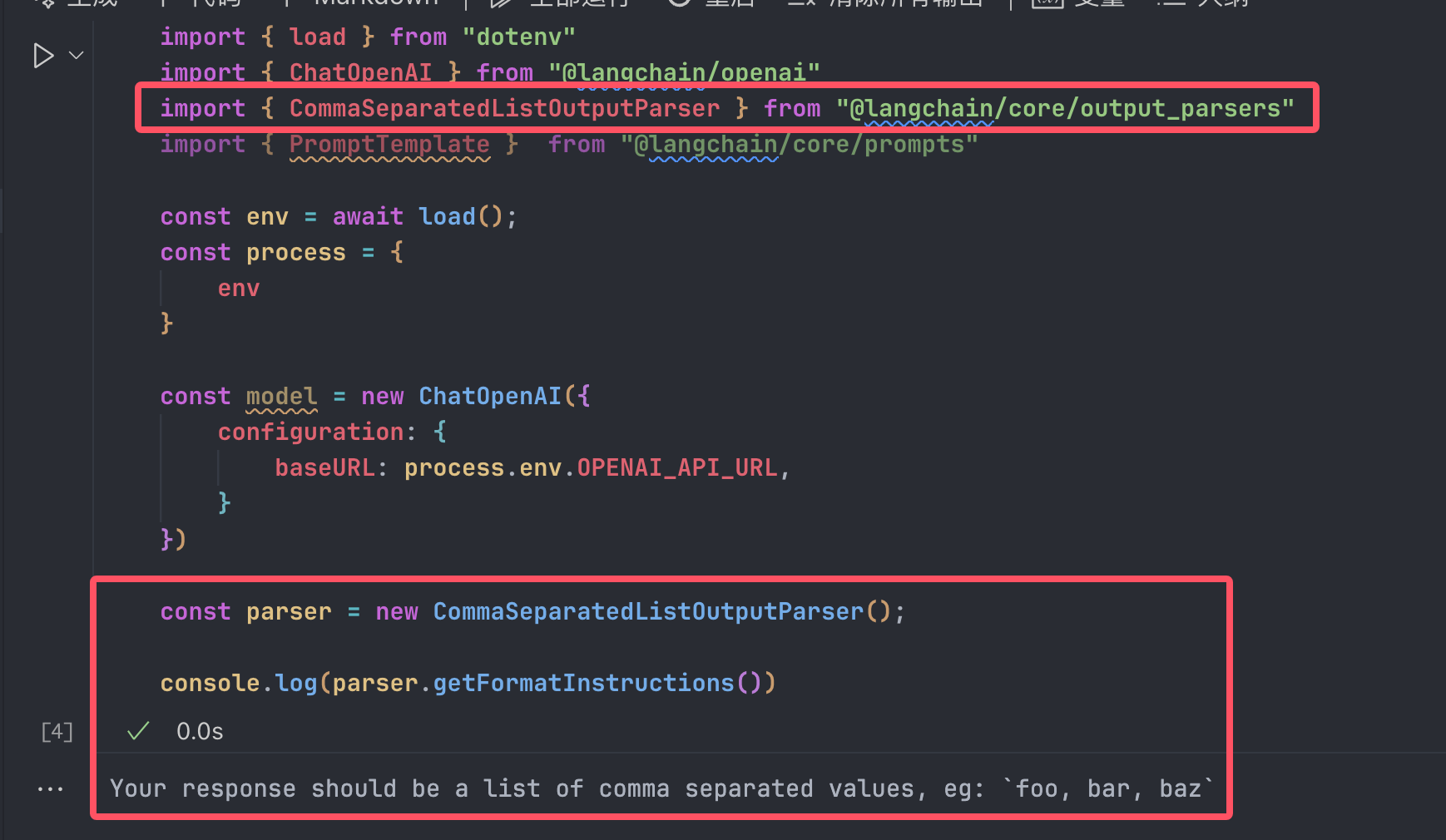
因为是输出列表的那种parser,所以引导用的Prompt也是更为简单的。
让我们来把整条Chain做一下:
import { load } from "dotenv"
import { ChatOpenAI } from "@langchain/openai"
import { CommaSeparatedListOutputParser } from "@langchain/core/output_parsers"
import { PromptTemplate } from "@langchain/core/prompts"
const env = await load();
const process = {
env
}
const model = new ChatOpenAI({
configuration: {
baseURL: process.env.OPENAI_API_URL,
}
})
const parser = new CommaSeparatedListOutputParser();
const prompt = PromptTemplate.fromTemplate("使用中文回答,列出你知道的五个{area}动画公司\n{instructions}")
const chain = prompt.pipe(model).pipe(parser)
const res = await chain.invoke({
area: "日本",
instructions: parser.getFormatInstructions()
})
res结果也很明显: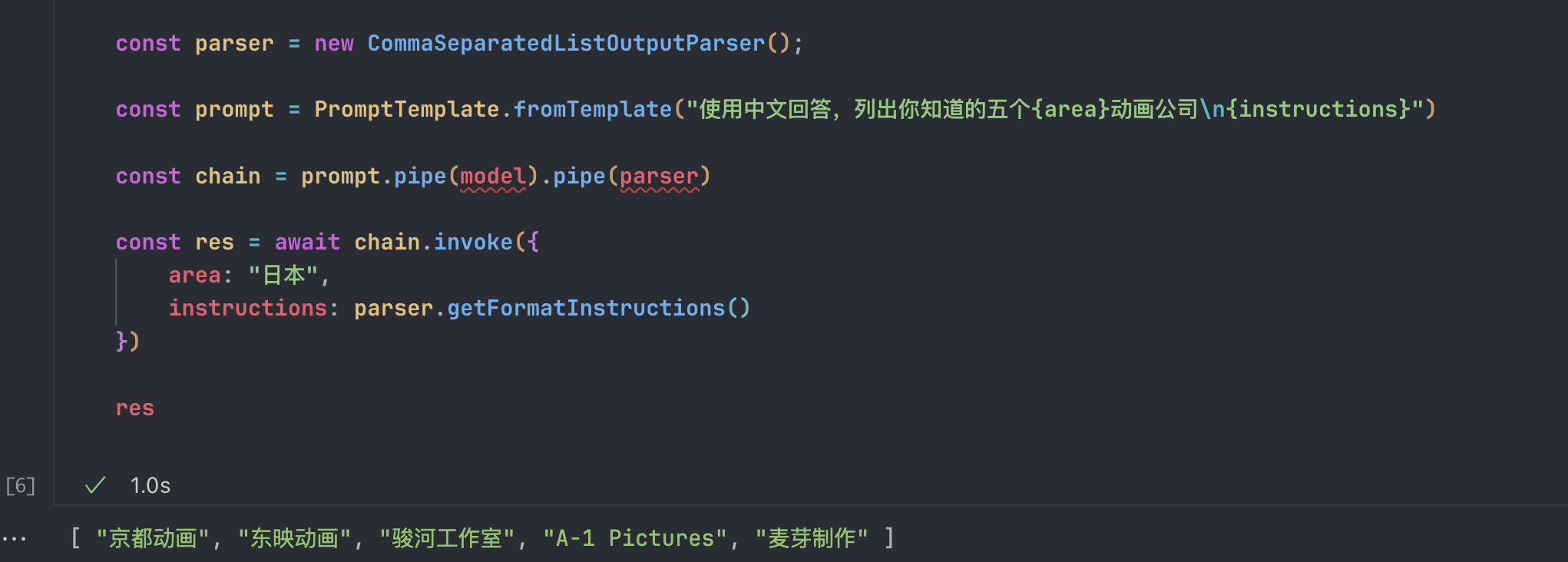
这大概就是Output parser的作用了,可以根据自己需要什么LLM输出格式,自行选择不用的parser,很简单吧?
Auto Fix Parser
最后再来一个更进一步的知识点,对于部分对输出质量要求很高的场景中,如果出现了输出不符合要求的状况,我们需要的不是让LLM反复输出,因为这个时候LLM说不定已经完全认定了自己的输出没有错误,我们要做的是,把报错的信息返回给LLM,让它知道错哪儿了
首先我们需要zod,一个验证js\ts类型是不是正确的三方库,在文章开头就已经更新在deno.json了,记得更新,并且删除lock文件重新加载。
定义Schema:
import { z } from 'zod'; const schema = z.object({ answer: z.string().describe("用户问题的答案"), confidence: z.number().min(0).max(100).describe("你对回答的信心,满分100分") });answer是字符串类型,表示用户问题的答案confidence:0到100的数字,表示的是模型对答案的置信度
使用
SptructuredOutputParser解析LLM的输出import { ChatOpenAI } from "@langchain/openai"; import { StructuredOutputParser } from "langchain/output_parsers"; import { PromptTemplate } from "@langchain/core/prompts"; const parser = StructuredOutputParser.fromZodSchema(schema); const prompt = PromptTemplate.fromTemplate( "尽可能地回答用户的问题 \n{instructions}\n{question}" ); const model = new ChatOpenAI({ configuration: { baseURL: process.env.OPENAI_API_URL, }, });PromptTemplate定义了生成答案的模板{instructions}正如我们之前所讲的那样,这是包含了格式化输出的说明的替换符,主要是parser.getFormatInstructions()生成的。{question}是用户的问题
调用LLM并且验证一下输出
const chain = prompt.pipe(model).pipe(parser); const res = await chain.invoke({ question: "你好,请问京阿尼动画在哪一年发生了火灾?", instructions: parser.getFormatInstructions() }); console.log(res);这个时候生成的是正确的内容:

这是符合Schema的内容,不需要进一步处理了调用
OutputFixingParser来进行修复错误如果模型的输出不符合预期了,我们就可以用这个方法来进行修复
import { OutputFixingParser } from "langchain/output_parsers"; const fixParser = OutputFixingParser.fromLLM(model, parser);我们在这里建立了一个专门用来修复的Parser,他有两个参数,一个是接受模型,一个是验证的规则。我们来创建两个场景来说明这个比较绕弯子的功能:
### 修复示例 1:字段错误const wrongOutput = { answer: "2018年", sources: "90%" // 错误字段 }; const fixedOut = await fixParser.parse(JSON.stringify(wrongOutput)); console.log(fixedOut);修复后输出:
{ "answer": "2018年", "confidence": 90 }### 修复示例 2:类型错误
const wrongOutput = { answer: "2018年", confidence: -1 // 不符合范围 }; const fixedOut = await fixParser.parse(JSON.stringify(wrongOutput)); console.log(fixedOut);修复后输出:
{ "answer": "2018年", "confidence": 90 }注意:修复器它并不能修复事实错误,比如京阿尼火灾是2019年这个事实,而是只是修改我规定的类型和数据还有属性错误
这里可以说明一下:
实际上算是一种多模型的协作- 用高质量模型(比如GPT4)生成初期的结果
再用低成本模型(GPT3.5或者本地大模型Ollama)来修复格式的错误
这样做可以显著降低成本,避免重复调用高成本模型