检索增强生成(RAG)原理与流程
随着大模型的技术发展,在应用领域里,逐渐聚焦于两个方向RAG与Agent,从这里,我们要开始探讨一下 RAG。
这是 LLM 中最为典型也最为流行的设计模式,全称为:Retrieval Augmented Generation,也就是:检索增强生成技术。其核心也从字面意思可以一探究竟:
检索 => 增强 => 生成。
这一篇文章我们不太会涉及到代码,主要是探讨如何理解 RAG 技术。
从原理到基本流程。
LLM 局限性
我们先从 LLM 的局限性开始讲起,在没有涉及到 RAG 之前,LLM 有什么问题?
因为最近一两年 LLM 话题的大热,幻觉问题(hallucination)这个词汇应该经常出现在大家的视野里。因为 LLM 的本身是基于从大量数据中训练出来的概率模型来生成一个个 Token,也就是说,实际上 LLM 并未内置严格的逻辑推理和事实校验机制,而是通过概率模型生成输出,所以我们才说 LLM 的智能说白了就是涌现性的智能,是基于概率产生的“概率驱动的智能”,亦或是“统计智能”。
但是实际上,这些东西对于应用层而已压根儿无所谓,因为这种涌现性的智能对于应用层已经足够强大,已经能够承担很大程度上的任务处理,展现出了足够的推理能力和逻辑。
那到底什么是涌现的智能?到底有没有智能?
我实际上可以给你举一个很简单的故事,比方说,我们把一只猴子的寿命拉到无限长,然后给他一个打字机,然后让他一直打字,把这个过程拉到无限长,总有一天,它能敲出来一本人间失格吗?当然,这是必然会敲出来的,甚至不只是人间失格,还会是莎士比亚的小说,还会是莫言的小说,因为时间是无限长的,它是随机打字,那么就会在某个时间点碰巧全部撞上这个概率,并且成了一本完整的小说。
那你会问我,猴子到底懂不懂小说,文学?我必然会告诉你是完全不懂的,它没有逻辑,只是概率性的事件碰巧凑到了一起。而 LLM 就是一只有更大概率敲出小说的猴子,它不理解输出文本的逻辑,更不理解内容背后的逻辑,但是因为它训练的足够多,模型足够大,数据集足够庞大,它输出正确的内容的概率也就足够大。所以,在我们看来,他就像真正理解内容一样,也就像具有了“真正的逻辑与推理能力”。
另外还有一个简单易懂的例子,目前来看,chatgpt 还是一个文本模型,但是你若是让它推荐色彩分明的颜色,它还是能够很好地推荐出来符合要求的颜色,但是它看得见颜色吗?其实看不见,它也看不到,理解不到色彩世界。它能够推荐出你想要的颜色,是因为它训练的数据集中色彩分明和部分色彩分明的颜色建立足够多的联系。
这下应该理解到了涌现性智能是什么意思了吧?
也就是说:
- 第一个问题:幻觉问题
- 第二个问题:对领域知识有所欠缺
对于第二个问题,分为两种情况:
- 就是知识更新很慢,因为数据集不是说每天都在更新的,当然现在的 chatgpt 可以联网查询,但是这并不是语言模型的固有能力,而是通过外部工具扩展实现的。
- 对特定领域不了解,容易瞎回答。
所以这两个问题的解决方案就是RAG。
RAG
综上所述,LLM 是基于概率性的底层逻辑,解决办法就是尽可能提供与答案相关的上下文,增强正确输出的可能性。
比方说把人间失格这本书放在猴子的身旁,让它一边看一边打字
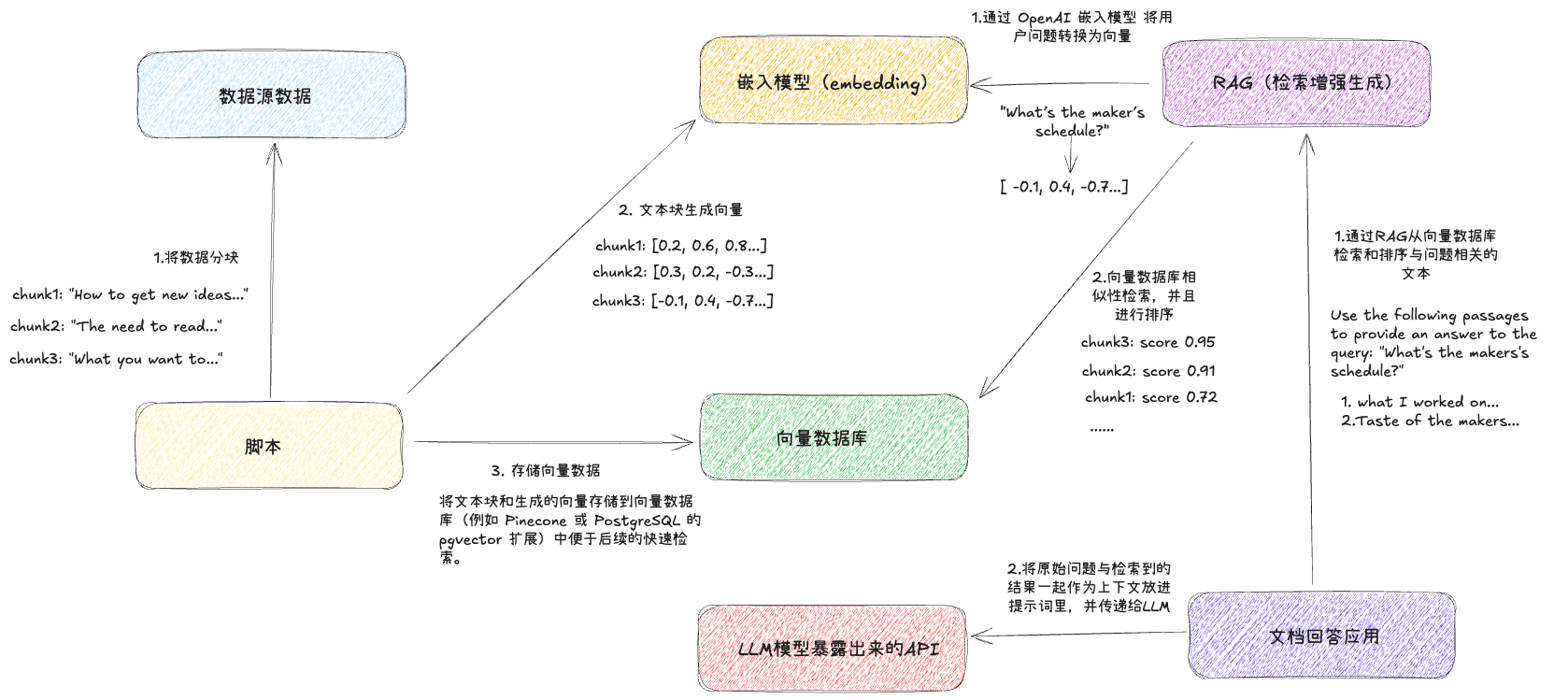
RAG 的流程:
- 用户输入提问
- 检索:根据用户提问对 向量数据库进行相似性检测,查找与回答用户问题最相关的内容
- 增强:根据检索到的结果,生成 Prompt。一般都会是“仅依赖下述信息来源来回答问题”这一类限制 llm 参考信息源的语句,来减少幻想,使得回答的精准性提高
- 生成:将增强之后的 Prompt 传给 llm,返回数据给用户
所以说 RAG 就是哪里有问题,我们就解决哪里,既然我们的大模型(借助网络的情况也只是依靠外部工具)无法获得最新和内部的数据集,那我们就使用外挂的向量数据库来为 llm 提供最新和内部的数据库。
既然大模型会有幻想问题,我们就把回答问题需要的信息和知识编码到上下文,强制大模型只要参考这些内容回答就行了。
说到更底层的逻辑,这也是我们应该对待 llm 的正确态度
llm 是逻辑推理引擎,不是信息引擎。由外挂的向量数据库提供最有效的知识,然后让 llm 根据知识进行推理,给出最有价值的回复
这种分工模式类似于一个团队:
- 向量数据库是专家,提供权威信息。
- LLM 是顾问,根据信息提供解答。
RAG 的流程
基本原理已经讲明白了,来看看 RAG Chat Bot 如何构建吧
1.加载数据
咱们的第一步就是根据用户的提问进行语义检索,我们需要把数据集放到向量数据库里,也就是我们需要把不同的数据源加载进来,比方说pdf、code、现成的数据库、云数据库之类的。
LangChain就提供了现成的非常多的集成工具,我们可以用它来加载多个数据源的数据。比方说文档加载器(Document Loaders)
2. 切分数据
现在的 chatgpt 主流模型 GPT-4 Omni 的上下文窗口是 128K(相当于 300 页文本内容),在实际测试显示,当输入超过 73,000 个 token 时,模型的理解能力可能会显著下降。
注:我们这个文集使用的 ollama 模型 llama3.2 的上下文窗口也是 128K
但是很多的数据源都非常容易大于这个窗口限制。更何况在 RAG 的原理背景下,用户的提问会容易涉及到多个数据源,所以我们需要对数据集进行语义化的切分,根据内容的特定和目标大模型的特点,上下文窗口,对数据源进行合适的切分。
听起来很容易?但是考虑到数据源的多种多样与自然语言的特点,事实上切分函数的选择与参数的设计都是挺难控制的。理想状态下,我们希望每个文档块都是语义相关并且互相独立。
3. 嵌入(embedding)
这里可能会涉及到一点机器学习的知识,我们来用嵌入模型最简单的例子来说明一下embedding的过程。
- 词袋模型就是最简单的情况,我们可以把一篇文章的单词提出来,放进一个袋子,每个单词都是独立的,我们暂时不关心他们的上下文关系
假设我们有三篇英文文章,我们把每个文章都拆分成单词,并且把所有的语态都还原成最初的形态:(has => have)。接着我们统计一下每个单词出现的次数。比如:
第一篇: alien: 100, ghost: 80 第二篇: alien: 80, ghost: 100, ufo: 20 第三篇: uda: 60, monster: 10那么我们来尝试构建一下向量,也就是说一个数组,每个位置都有一个值,代表的是每个单词在这个文章里面出现的次数
变量 [alien, ghost, uda, ufo, monster]那每一篇文章都可以用变量来表示:
第一篇:[100, 80, 0, 0, 0] 第二篇:[80, 100, 0, 20, 0] 第三篇:[0, 0, 60, 0 ,10]如此一来,我们就可以把一篇文章当成一个变量来表示了,然后我们可以用简单的余弦定理计算一下向量之间的夹角(梦回 shader),计算夹角之后可以确定向量之间的距离。
- 这样的话,我们就有了通过向量和向量之间的余弦夹角,来衡量文章之前相似程度的能力
- 局限性:虽然我们可以用词袋模型表示文本,但它无法捕捉单词间的语义关系或上下文。例如,“alien”和“ufo”之间的关联性在词袋模型中完全丢失。
现代嵌入的改进:
- 嵌入模型通过机器学习,可以将“alien”和“ufo”这样的语义相关单词映射到更接近的向量空间,同时考虑上下文,生成更精准的语义表示。
那么,回到 RAG 流程,我们会把第二步切分的每一个文档块使用这一步的嵌入算法转换为一个向量,存储到向量数据库里,每一个原始数据都有一个对应的向量,就可以用来做下一步的检索了。
4.检索数据
当所有需要的数据都存储到向量数据库里之后,我们可以把用户的提问也嵌入成向量,用这个向量去向量数据库里检索,找到相似度最高的几个文档切分块,返回内容
5.增强 Prompt
在有了跟用户提问最相关的文档块之后,我们根据文档块去构建 Prompt,这一步非常关键,目的是将从向量数据库中检索到的文档块整合为上下文信息,结合用户的提问构造一个 Prompt,来引导 LLM 生成更精准、更受控的回答。
这一步的核心问题是:LLM 本身可能会凭空“幻想”(生成与事实不符的内容),尤其是在上下文不明确时。
与之对应的增强 Prompt 的作用是:通过增强 Prompt,将与用户问题最相关的文档块嵌入到 LLM 的输入中,并明确限定 LLM 的回答范围。
一般的格式是:
你是一个知识助手,请根据以下上下文信息回答问题:
上下文信息:
1. <文档块 1>
2. <文档块 2>
3. <文档块 3>
用户提问:<用户的问题>
注意:仅根据上下文信息回答问题,如果信息不足,请回答“不知道”。6.生成
最后一步就很直白了,就是将组装好的 Prompt 传递给你的 chat Bot 进行生成回答。
总结
这篇文章基本上都是一些概念性的理论,实际上可以多看几遍理解一个大概。对于 LLM 应用层来说,我们不需要成为一个深入到算法,做科研的专家,我们的目的是理解原理,使得我们能够针对 llm 的特点设计应用与流程即可。
参考各种资料之后的一图流: