前言
获取 AI 服务有很多种选项,你如果有国外的信用卡就可以直接购买 OpenAI 的 API key,也可以走国内途径购买与 OpenAI 同源的 Azure OpenAI,当然,你也可以查询并且购买国内的三方代理的 API 服务,也可以做本地大模型,如果你的电脑配置满足最低要求,那么我建议使用这一方案,因为比较省钱嘛。本文也会着重讲解如何在MacOS获取本地大模型。
注:最低要求为:
Win 平台:显卡显存大于 6G
Mac 平台:M 芯片 + 16G 内存往上
本地大模型
在 Mac 平台下,我推荐使用 ollama,使用起来非常的简单,下载好模型之后,点开这个 app,就会自动在http://localhost:11434host 一个 llm 的服务。当然了,如果你在 win 平台,可以尝试一下LM Studio,这上面提供了更多的模型,已经更高的可玩性。
目前我本地使用的是 llama3.2
我们在 LangChain 里可以这么用: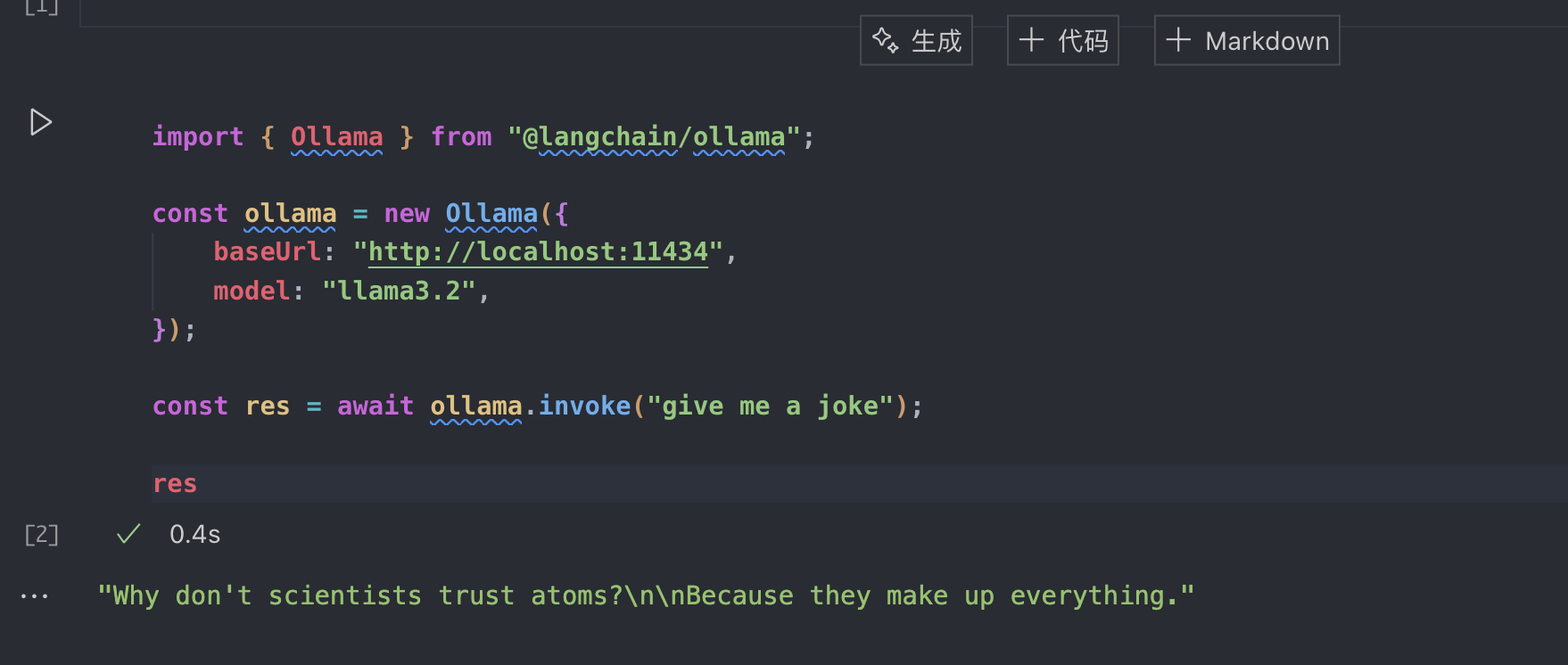
需要注意一下,如果这边使用的是 Deno,需要在 deno.json 里加入这一行代码:
"@langchain/": "npm:/@langchain/"如果本地模型你能跟我一样成功配置的话,我们接下来的学习过程都无需担心 llm 的费用问题,当然了,效果肯定就不如 chatgpt 强悍了。
这里有一个点需要注意,非常重要,因为 Deno 是运用的远端的包下载到本地的缓存区,所以在 vscode 里很多时候代码的类型提示是不管用的,但是不影响运行,请忽视报红
LangChain 基础
因为我们默认使用 Deno 以及本地大模型,所以我们需要向deno.json里添加 LangChain 的依赖别名:
{
"imports": {
"dotenv": "https://deno.land/std@0.220.0/dotenv/mod.ts",
"@langchain/core": "npm:/@langchain/core@latest",
"@langchain/ollama": "npm:/@langchain/ollama@latest"
},
"deno.enable": true
}这里添加了langchain/来方便引用 LangChain 众多的子包
然后咱们就可以引入环境变量了,因为我们使用的是本地模型,所以我们只需要把模型名字和地址写入就行了:
BASE_URL=http://localhost:11434
MODEL=llama3.2import { load } from "dotenv";
const env = await load();
const process = {
env
}
import { Ollama } from "@langchain/ollama";
import { HumanMessage } from "@langchain/core/messages";
const ollama = new Ollama({
baseUrl: process.env.BASE_URL,
model: process.env.MODEL
});LCEL
什么是LCEL?
全称:LangChain Expression Language
是 Language 无论 Python 还是 JS 都在主推的新设计。
此设计方法从底层设计的目标就是支持从原型到生产,完整的流程不需要修改任何的代码,也就是说我们在写的任何原型代码不需要太多的改变就可以支持生产级别的各种特性(比方说并行,steaming 之类的)
比方说我们来举一些例子:
从原型到生产的无缝过渡
- 核心理念:LCEL 的设计使得开发者在编写原型代码的过程中,就已经具备了生产环境需要的特性。
- 优势:减少了在不同开发阶段需要修改代码的情况,提高了开发效率和代码的稳定性
并行处理
- 自动并行化:如果链(Chain)中有可以同时执行的步骤,LCEL 就会自动识别他们并且执行他们
- 性能提升:通过减少处理时间,降低延迟,提高用户的体验
自动重试与回退机制
- 错误处理:链(Chain)的组件内置了自动重试机制,例如在网络故障导致请求失败时,就会自动地去重新尝试请求
- 回退方案:如果某个步骤持续重复失败,那么系统就会使用备用方案,确保整个链(Chain)的稳定性
- 对于开发者而言的收益:无需手动地编写大量错误处理代码,减少了开发的工作量
访问链的中间结果
- 可观测性:LCEL 允许每个开发者方便访问和检查链(Chain)中每个步骤的中间结构
- 调试便利:这使得定位问题,性能优化变得更加的容易
与 LangSmith 的集成
- 自动支持:LCEL 默认支持 LangChain 的官方记录与可视化工具
LangSmith - 功能:LangSmith 可以记录链(Chain)的执行过程,提供详细的日志与可视化界面
- 意义:帮助开发者了解链(Chain)的执行细节,找出导致最终结果不佳的中间环节,并且对其进行针对性的优化
- 自动支持:LCEL 默认支持 LangChain 的官方记录与可视化工具
总而言之,我总结了以下几点:
链(Chain)
在 LangChain 中,指代的是完成特定任务的一系列有序步骤或者组件的集合
LCEL 优势
- 代码一致性:从原型到生产是不需要改代码的
- 性能优化:自动并行执行,提高效率
- 可靠性提升:内置的重试和回退机制,减少错误
- 调试与监控:方便访问中间结果,与 LangSmith 集成,增强了对链的可观测性
Runnable
一条 Chain 组成的每个模块,都是继承自Runnable这个接口,而一条 Chain 也是继承自这个接口,也就是说,每一条 Chain 可以自然而然的成为另一个 Chain 的一个模块,并且所有的Runnable都有相同的调用方式。所以!我们在写 Chain 的时候就可以自由组合多个由这个接口继承的模块,形成复杂的 Chain 了
而对于Runnable对象,会有这么几个常用的标准调用接口:
invoke:基础调用,需要传入参数batch:批量调用,需要传入一组参数stream:流式调用,以 Stream 流的方式返回数据streamLog:除了像 Stream 流一样返回数据,还会返回中间的运行结果
让我们来看看代码怎么做的:
invoke
那么,我们启动了 Ollama 本地大模型之后,我们用最基础的Ollama,这其实也是一个Runnable对象,所以我们用这个例子来熟悉一下 LCEL 的Runnable中常见的调用接口。
import { Ollama } from "@langchain/ollama";
import { HumanMessage } from "@langchain/core/messages";
const ollama = new Ollama({
baseUrl: process.env.BASE_URL,
model: process.env.MODEL
});
const res = await ollama.invoke([
new HumanMessage('what is your name'),
]);这里面,HumanMessage可以理解为我们构建一个用户的输入,并且这里的 invoke 方法只能接受 message 列表,也就是说数据,不然会回复他无法理解: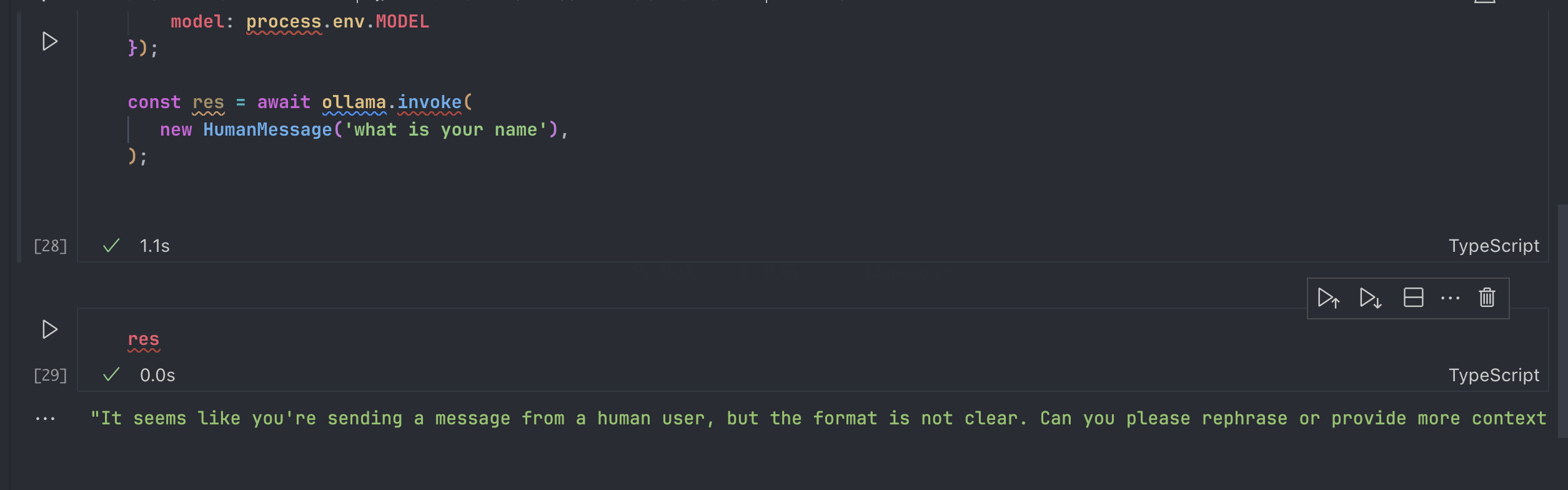
另外,因为我们使用的是 Ollama 模型,所以这里的 invoke 方法就会直接返回一个字符串。但是有一个东西值得一提的是,如果使用的是 OpenAI 的 invoke 接口,那么就会返回这样的结构体:
AIMessage:
{
"lc_serializable": true,
"lc_kwargs": {
"content": "Why don't scientists trust atoms?\n\nBecause they make up everything!",
"additional_kwargs": {
"function_call": undefined,
"tool_calls": undefined
},
"response_metadata": {}
},
"lc_namespace": ["langchain_core", "messages"],
"content": "Why don't scientists trust atoms?\n\nBecause they make up everything!",
"name": undefined,
"additional_kwargs": { "function_call": undefined, "tool_calls": undefined },
"response_metadata": {
"tokenUsage": {
"completionTokens": 13,
"promptTokens": 11,
"totalTokens": 24
},
"finish_reason": "stop"
}
}在这种情况下,为了方便展示,我们会加入一个简单的StringOutputParser来处理输出,你可以简单的理解为将 OpenAI 返回的复杂对象提取出最核心的字符串,用法很简单:
import { ChatOpenAI } from "@langchain/openai";
import { HumanMessage } from "@langchain/core/messages";
import { StringOutputParser } from "@langchain/core/output_parsers";
const chatModel = new ChatOpenAI();
const outputPrase = new StringOutputParser();
const simpleChain = chatModel.pipe(outputPrase)
await simpleChain.invoke([
new HumanMessage("Tell me a joke")
])这样一来就会输出一个普通的文本了,跟 Ollama 的效果如出一辙。
在 LCEL 中,使用.pipe()方法可以组装多个Runnable对象形成一个完成的 Chain,在这个 OpenAI 的例子中,我们可以看到无论是单个模块还是多个模块组装而成的 Chain 都是Runnable
batch
批处理,用法更简单: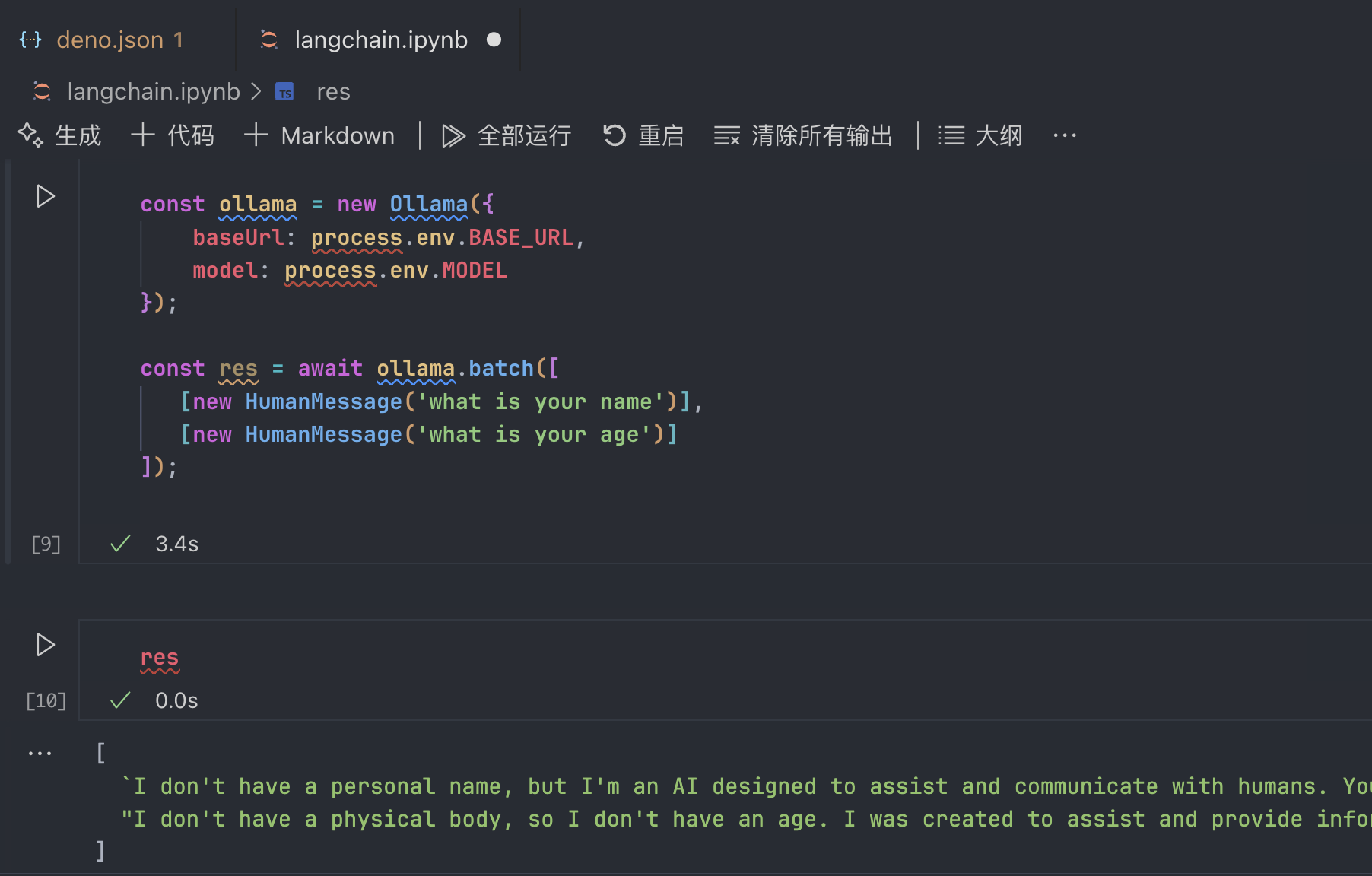
返回值也如同截图一样,是一个列表,同时回答了两个问题。
stream
因为 LLM 的很多调用都是一段段返回的,如果要等到完整的内容再统一返回给用户,就会让用户等待比较久,影响用户的体验。
但是 LCEL 开箱就是 streaming,我们可以使用我们定义的基础 Chain 来直接获得 streaming 的能力
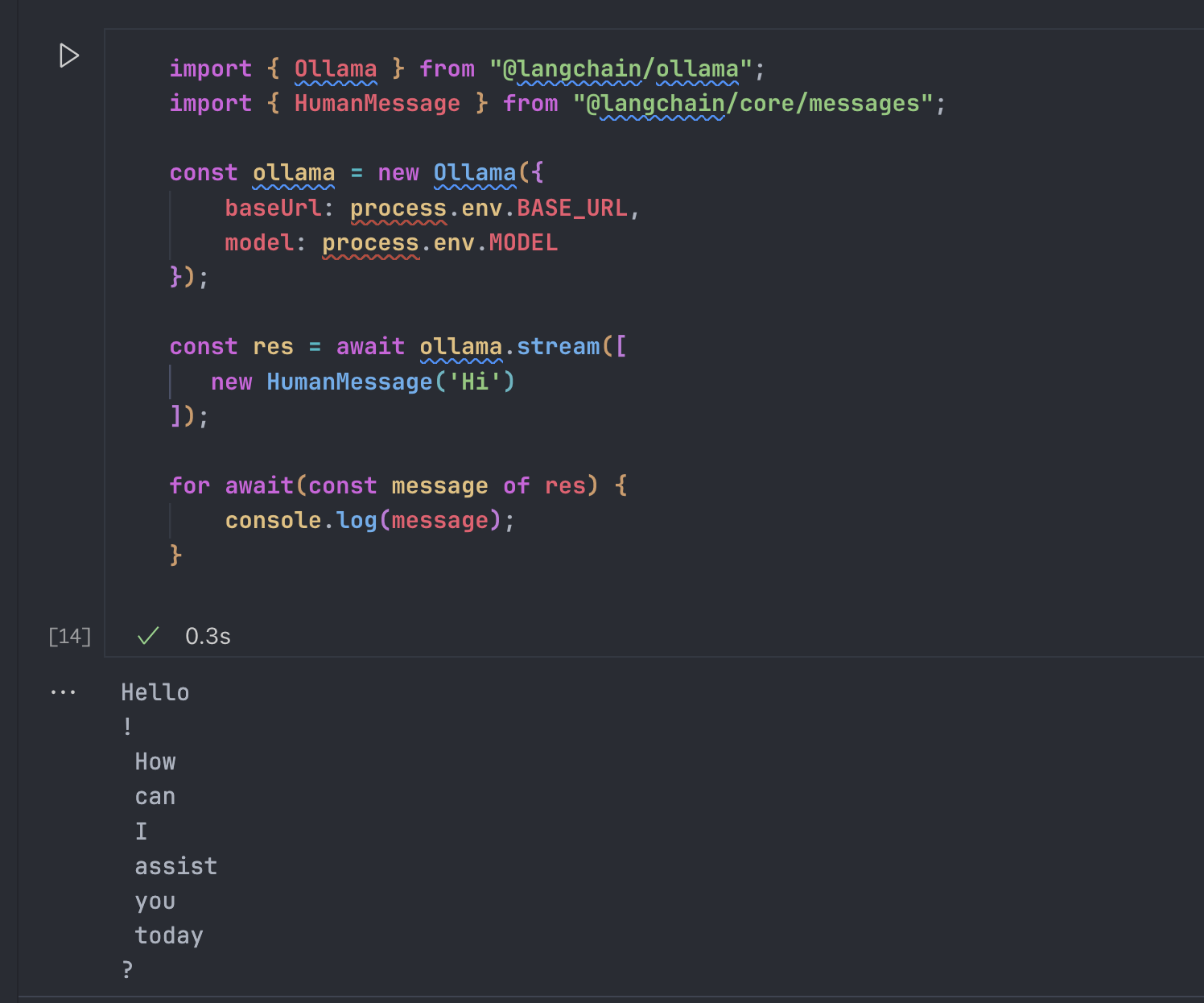
而有一个更少用的,但是我们可以提一下的就是 streamLog,他会在每次返回 Chunk 的时候,返回完整的对象:
const res = await ollama.streamLog([
new HumanMessage('Hi')
]);
for await(const message of res) {
console.log(message);
}如图所示: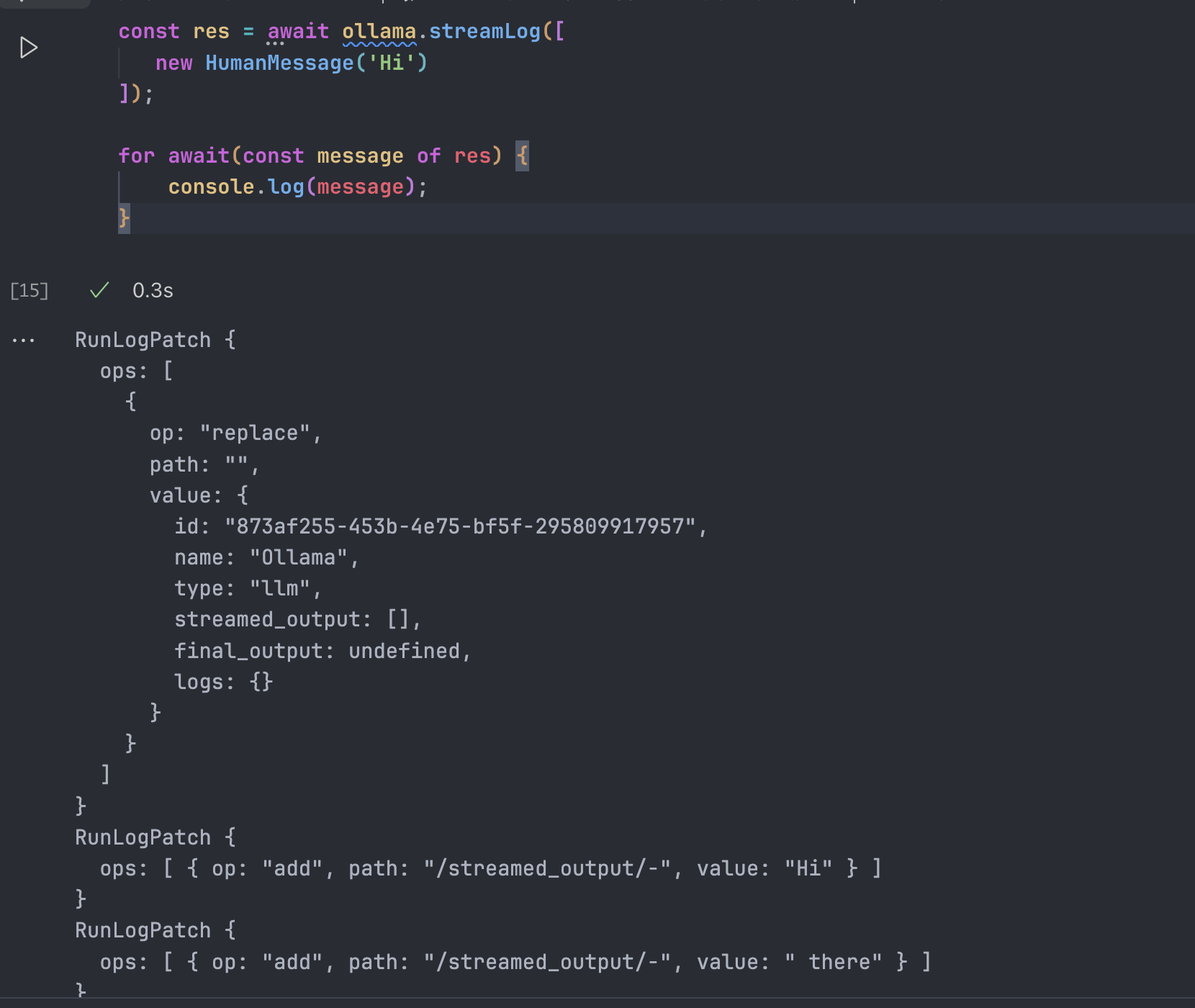
fallback
withFallbacks是任何 Runnable 对象都有的一个函数,可以给当前 Runnable 对象添加 fallback 然后生成一个带 fallback 的RunnableWithFallbacks对象,这适合我们将自己的 fallback 逻辑增加到 LCEL 中。
比方说我们创建一个必然会失败的 LLM:ollamaFake,然后我们将它的重试次数设置为 0:maxRetries
然后我们再创建一个可以成功的 LLM:ollamaTrue,然后我们设置 fallback,就可以得到正确的结果:
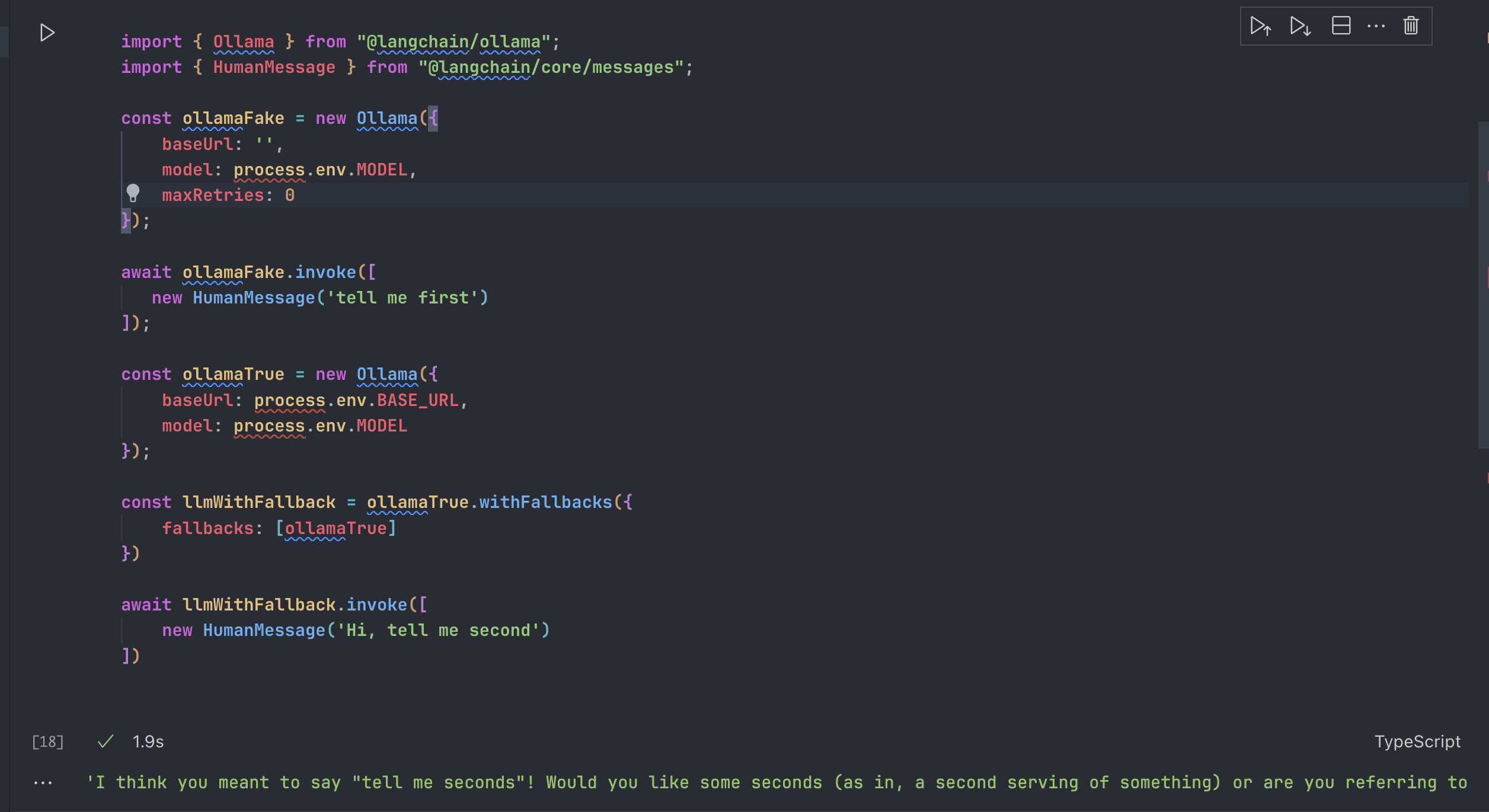
这是因为,无论是 llm model 还是其他的模块,还是整个 Chain 都是 Runnable 对象,所以我们可以给整个 LCEL 流程里的任何环节去增加 fallback,来避免一个环节出现问题卡住剩下环境的运行。
当然啦,我们也可以给整个 Chain 增加 fallback,比如说一个复杂但是输出高质量结果的 Chain 可以设置一个非常简单的 Chain 作为它的 fallback,这样一来,即使在极端环境下也是可以保证有一定的输出的。